
CVPR 2022丨无监督预训练下的视频场景分割
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
前言 对于视频场景分割任务,如何更好地在无标注长视频上进行自监督预训练?如何运用视频特征对该任务进行建模?腾讯优图实验室、深圳大学、KAUST等机构的研究成果入选今年CVPR 2022会议。
来源:腾讯优图实验室
编辑:CV技术指南

近年来,基于自监督(Self Supervised Learning ,SSL)方法在各计算机视觉任务上表现出强大的学习能力和泛化性,并随着如MoCo、SimCLR、SwAV、BYOL、SimSiam、MAE等SSL框架的诞生,使得基于的SSL方法受到越来越多的关注。
一般而言,大多数SSL方法在图像分类、视频分类、目标检测等任务上进行性能评估,并且其预训练范式并不适合视频场景分割(Video Scene Segmentation,VSS)任务,本工作主要讨论和探究各SSL对比学习范式和特征质量评估方案在VSS任务下的效果。主要研究动机如下:
在大量未标注的长视频数据上,对特征提取器进行预训练,使得模型能捕捉和建模长视频中的时序依赖关系和内容主题相关性。
常见的SSL训练范式在视频场景分割下游任务上泛化能力不够理想。
在先前的视频场景分割相关工作中,下游监督学习模型存在一定的归纳偏置,导致其对一些超参数较为敏感,以及较低的训练和推理效率。
在本文介绍的《Scene Consistency Representation Learning for Video Scene Segmentation》工作中,提出了一种基于场景一致性自监督表征学习方案(SCRL),使得相似场景的镜头表征在特征空间中分布得更为紧凑,如图1(c)所示;
同时采用归纳偏置更低的时序建模方法对特征质量进行评估,并对视频场景分割任务进行建模。该方案在VSS任务上达到了SOTA水平。
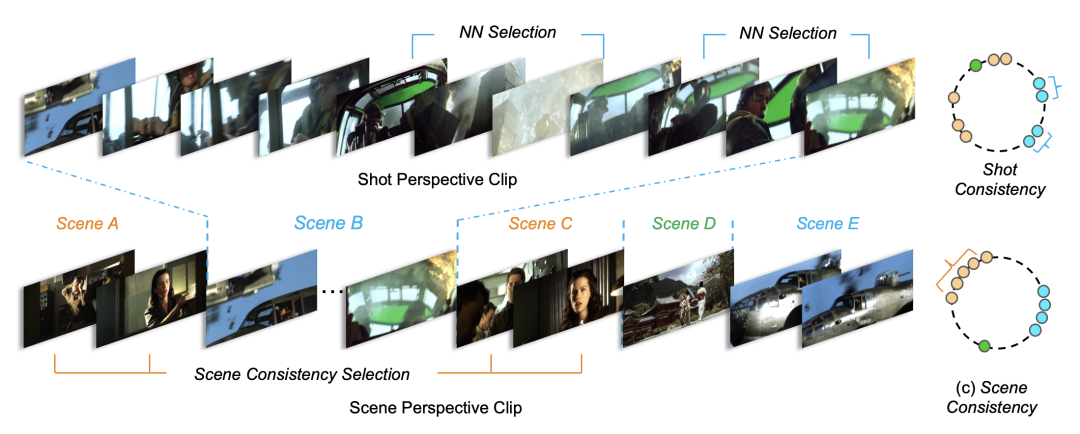
图1 SCRL算法动机示意图
论文:
https://arxiv.org/abs/2205.05487
代码:
https://github.com/TencentYoutuResearch/SceneSegmentation-SCRL
任务背景介绍
任务介绍
视频场景分割(Video Scene Segmentation,VSS)作为视频理解中的一个子任务,其主要目标是以一个长段视频按照场景内容的不同为切分线索,以镜头维度将长视频切分成若干独立子视频,切分过程又称作场景边界检测(Scene Boundary Detection),如图2所示。

图2 VSS任务介绍
背景知识
视频帧,镜头与场景间的关系
一组镜头(Shot)包含若干由同一个相机不间断拍摄到的连续帧,镜头切分结果可以通过成熟的算法获得,如:TransNet;
一个场景(Scene)由连续的镜头组成,一般描述相同的故事,具有更高级别的抽象语义。VSS任务则是在Scene级别对长视频在时域上进行分段,可以理解为按照不同故事线对长视频进行切分。

图3 帧、镜头(Shot)和场景(Scene)
在视频中的层次关系
方案介绍
任务Pipeline介绍
本框架总览如图4所示,该算法框架主要包含两个阶段:
镜头表征学习阶段;
视频场景分割阶段。
在镜头表征学习阶段中,与常见的SSL框架一致,通过复制特征提取器M得到由键值编码器(Key Encoder)和查询编码器(Query Encoder)组成的双路训练分支。
对于输入镜头序列而言,先经过Aug_K, Aug_Q数据增强方法得到增强后的输入镜头特征序列,随后在查询编码器(Query Encoder)产生的特征中,对每个查询镜头特征q筛选出对应正样本特征,得到代表样本i所对应的正样本下标的索引映射函数MAP(i),再从键值编码器(Key Encoder)产生的特征中根据MAP(i)选择出实际用于预训练的正样本对,如公式所示:
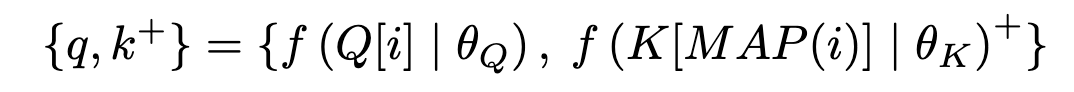
因此,不同的正样本选择策略可以转化成不同的映射函数。最后通过使用InfoNCE对比损失函数对整个预训练过程进行优化(若在无负样本训练框架中,则只使用余弦相似度函数进行优化)。
预训练完成后,查询编码器则作为后续监督学习阶段使用的镜头特征提取器。
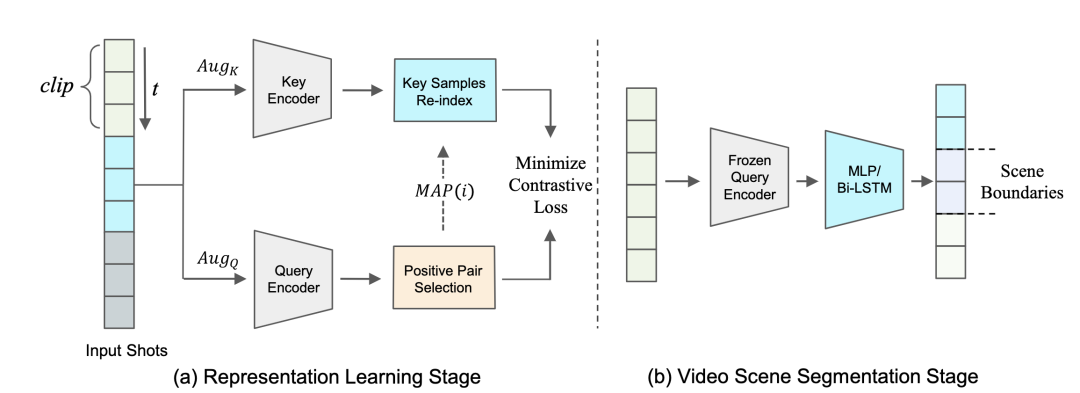
图4 算法整体Pipeline示意图
在视频场景分割阶段,使用参数固定的查询编码器对输入的视频镜头序列提取特征,再将特征输入到设计好的基于MLP/Bi-LSTM的视频场景分割模型中完成VSS任务建模。
正样本选择范式
本文分析和讨论了四种自监督训练范式,如图5所示,包含了图片分类、视频分类和视频的时序分割的预训练范式。
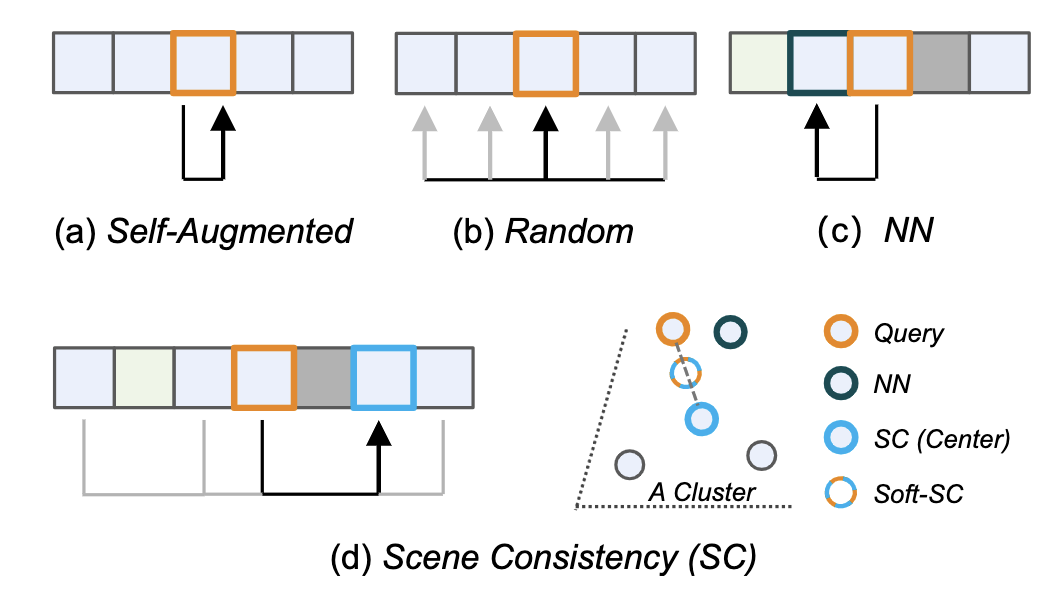
图5 4种正样本选择范式
对于图片级别的预训练任务而言,通常选择原样本的两个不同的增强视图作为正样本对,这里统称为Self-Augmented方法,此时映射函数可以表示为恒等映射:
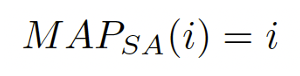
对于视频分类而言,对于查询样本,通常随机采样选择邻域范围为n的片段作为正样本,称为Random方法,映射函数表示为:
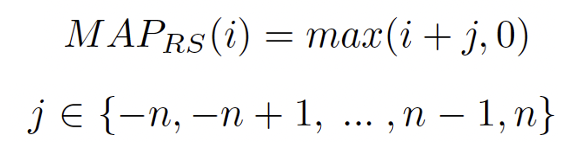
类似的,发表于CVPR2021的ShotCoL算法选择邻域范围为m的最近邻片段作为正样本,称作Nearest Neighbor(NN)正样本选择策略,映射函数可以表示为:
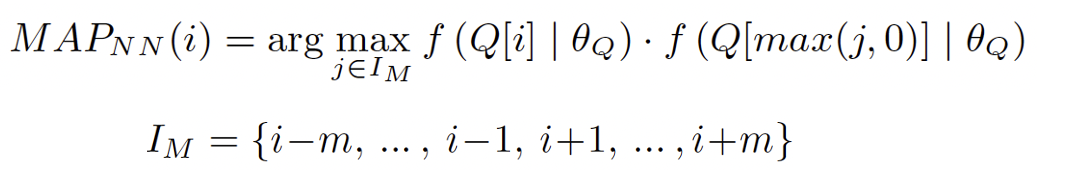
由于长视频场景通常交错排布和具有较高的冗余性,因此本工作使用聚类中心作为正样本,并对正样本进行线性插值,称为Scene Consistency(SC)方法,映射函数表示为:
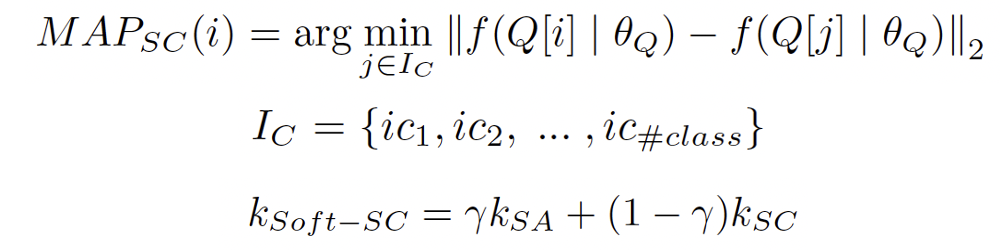
数据增强
对于大多SSL方法来说,数据增强是至关重要的,本框架使用的数据增强主要分为两种,一是对输入镜头序列进行打乱,称作场景无关的镜头序列打乱(Scene Agnostic Clip-Shuffling),二是对输入的单个镜头进行非对称的图像增强。在输入镜头打乱方法中,为了提升一个批次中的镜头和场景的丰富度,本文提出用固定长度为ρ的连续镜头序列为独立单位,对来自不同视频的镜头序列进行打乱,如图6所示:
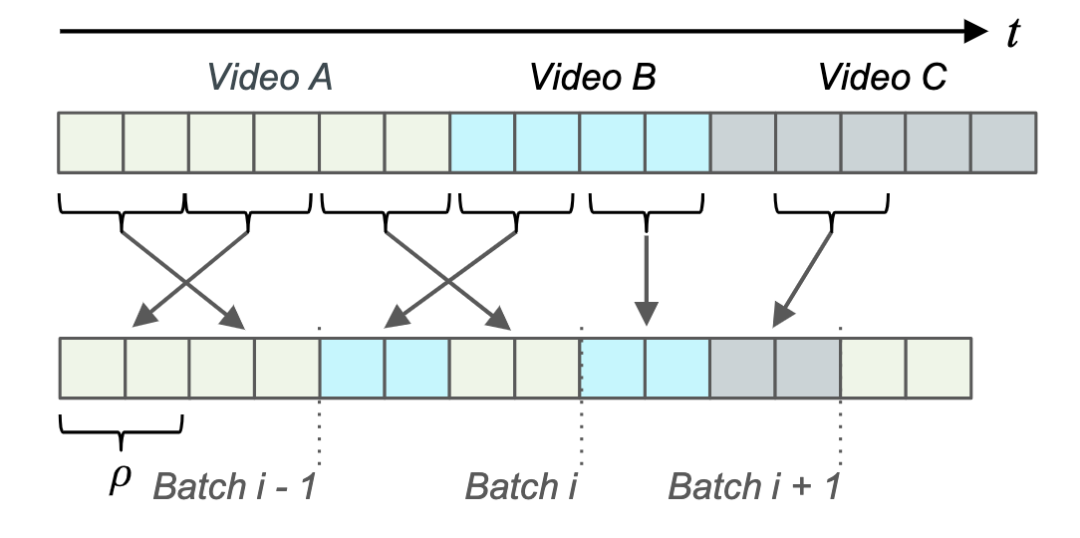
图6 Scene Agnostic Clip-Shuffling
方法示意图
非基于场景边界模型
不同于先前工作的基于场景边界(Boundary based)模型,本框架提出非基于场景边界(Boundary free)模型来对视频场景分割任务进行建模,如图7所示。
以输入长度为B * Shot-Len * N 长度的数据为例(B为批次大小,Shot-Len为单个批次中处理的镜头个数,N为镜头特征的维度),场景边界模型输出为B * 2,即对镜头中心边界进行建模。
而本框架提出使用基于Bi-LSTM序列建模方式,对每个镜头都进行场景边界进行分类,即经过Bi-LSTM模型序列建模后,序列输出为B * Shot-Len * 2,这样做的好处有:
可以有效降低模型复杂度和参数量;
提高推断的效率;
降低场景边界模型对场景边界镜头数量的归纳偏置。
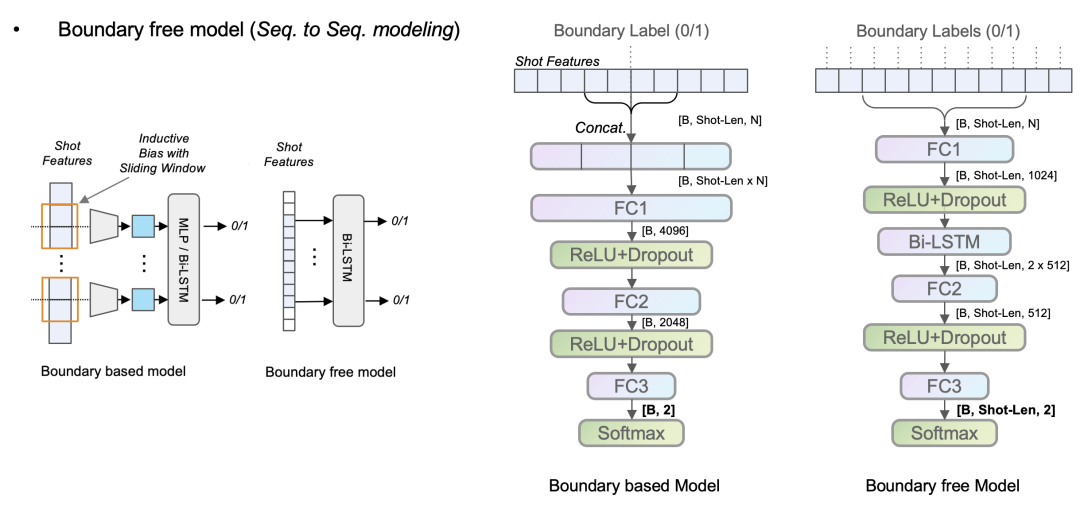
图7 Boundary based/free 模型示意图
实验结果
视频场景分割实验
如图8实验结果所示,在所有协议下,我们提出的方案在MovieNet-Scene Seg数据集上均能达到VSS任务下的优异水平(其中LGSS和ShotCoL分别为发表在CVPR2020和CVPR2021的工作)。
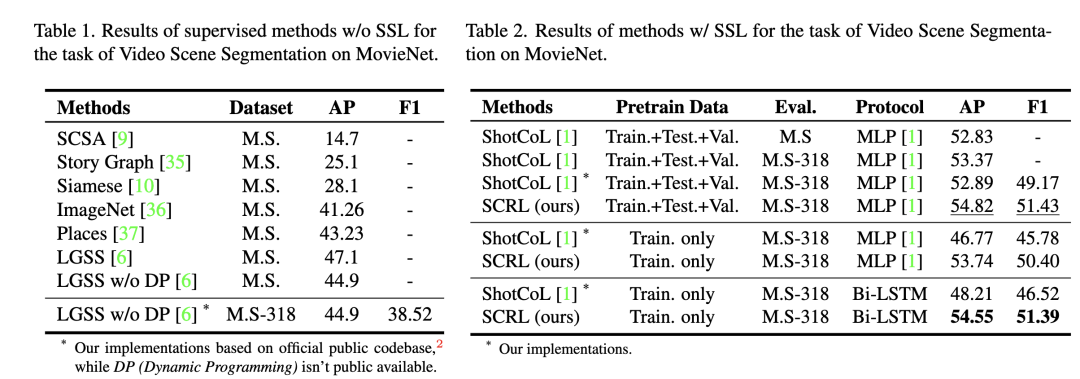
图8 各算法在MovieNet-SceneSeg数据集上
VSS任务上的效果
正样本选择消融实验
使用ResNet50作为特征提取器的backbone和MoCo v2作为预训练框架,对分析的正样本选择范式进行消融实验。如图9所示,可以观察到以下现象:
Self-Augmented方案在预训练中收敛速度最快,但由于其缺少时序建模,在VSS下游任务中表现最差;
Random方案在随机邻域范围小于4时,才可以正常收敛,在下游任务中表现稍好;
NN方案在所有方案中初始下降速率最快,在下游任务上表现中等,表示主动建模相似镜头的相关性有利于VSS任务,但下降速率快可能导致一定的过拟合现象和平凡解;
提出的SC方案虽然预训练损失下降速率一般,但是在VSS任务上的泛化能力优于其他方案。
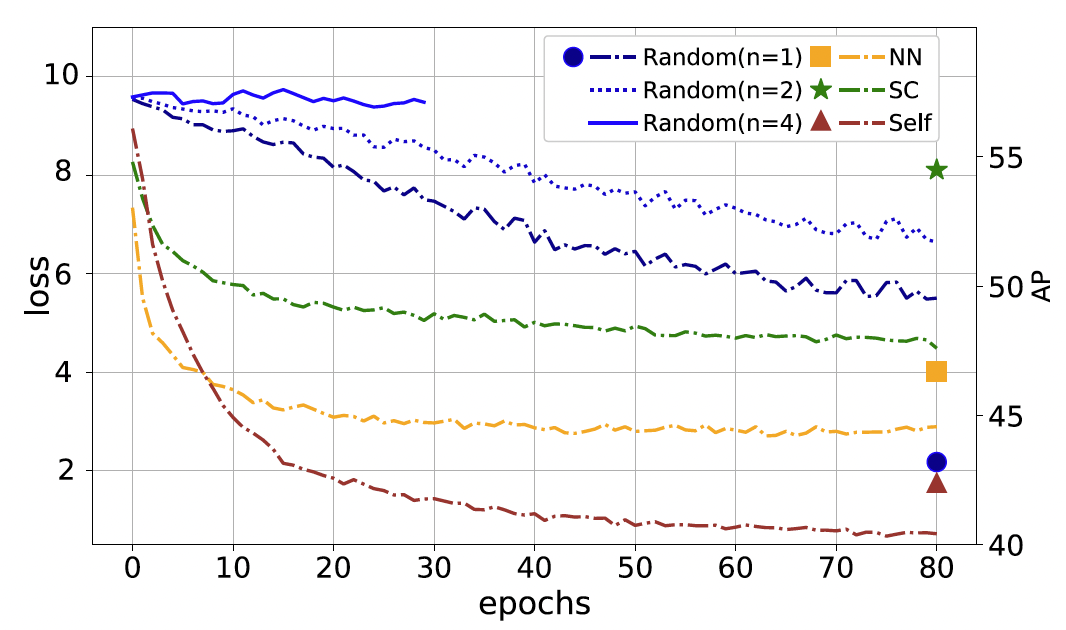
图9 各正样本选择策略的收敛曲线
和下游任务效果示意图
泛化性实验
该实验分为两组,分别为:将预训练好的特征直接运用到大规模多模态的监督模型(LGSS)上与测试下游模型的迁移能力,如图10所示。
在将无监督预训练好的特征提取器得到特征直接运用到大规模监督算法(LGSS)的pipeline上后,可以显著提高LGSS在VSS任务上的性能表现。
具体而言,将原算法中的Place365数据集上有监督预训练好的特征替换成SCRL算法预训练好的特征,值得注意的是,替换的特征是通过无监督学习得到的。
另一方面,提出的算法的迁移能力也是显著优于CVPR2021的SOTA算法(ShotCoL)。
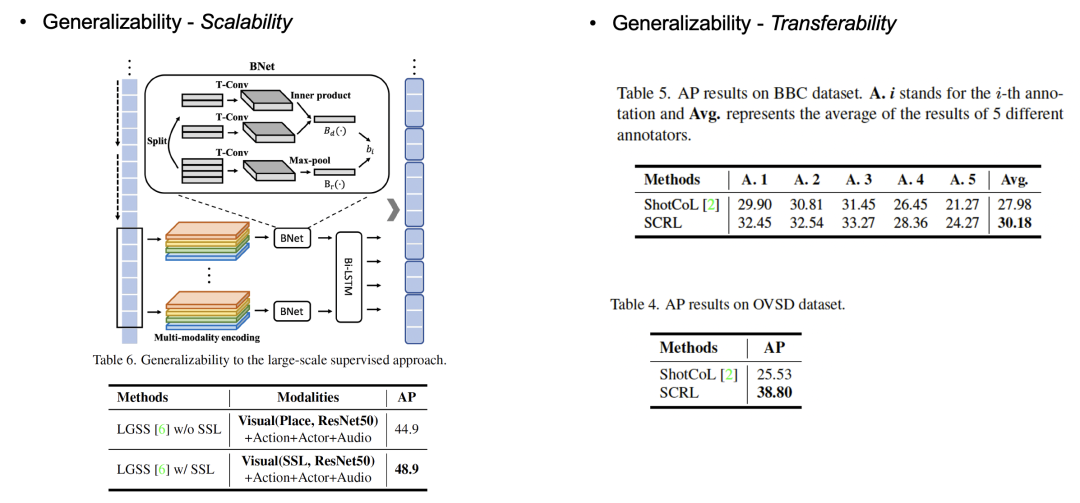
图10 泛化性实验结果
可视化实验
为了测试算法预训练好的模型是否有良好的镜头语义内聚性,本文还设计了镜头检索实验,从图11检索结果可以看到,使用提出的算法检索出的镜头具有更好一致性。

图11 镜头检索实验结果
算法落地
得益于本文提出的场景一致性自监督表征学习算法(SCRL)的易用性和良好的泛化能力,我们在腾讯云-媒体AI中台项目上将该算法进行了落地与业务算法迭代。
该业务算法能将完整的长视频按照内容进行结构化拆分,例如,将新闻视频拆分为若干独立的新闻事件,将综艺节目视频拆分为若干个独立的子节目等,如图12所示,拆分后的视频片段可进一步用于内容检索、资源整理、资源搜索等相关业务。
目前,腾讯云-媒体AI中台智能拆条应用已服务于多家客户,获得了广泛的好评。
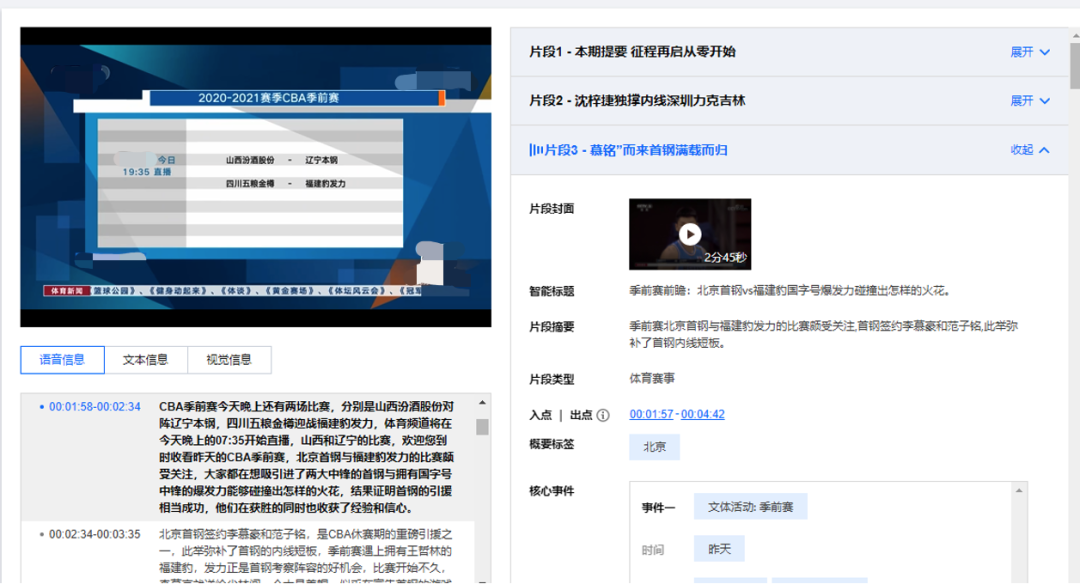
图12 腾讯云-媒体AI中台 智能拆条应用
本文仅做学术分享,如有侵权,请联系删文。