
实操教程|怎样制作目标检测的训练样本图像?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


极市导读
本文从五个问题出发依次递进讲解了该如何去制作目标检测的训练样本图像,并推荐了训练样本图像制作工具以及使用步骤。
【 看到这个题目相信不少人第一感觉是小题大作、故弄玄虚。不过还请先稍微按捺一下胸中的不快,在脑中给出下面这几个问题的答案。然后对照一下本文将要给出的答案,看看是否能够心平气和。】
像元值应该如何进行归一化? 样本图像的尺寸仅与内存、显存大小有关吗? 网络能检测的目标框范围只与图像大小有关吗? 卷积网络真的具有平移和旋转不变性? 制作目标检测训练样本的最佳方案是什么?
以下为原文:
像元值应该如何进行归一化?
不能想当然地认为像元值的取值范围就是0到255,虽然普通数码相机拍摄出来的图像各个通道的取值范围确实是0-255。要知道这个0-255的取值是从更大取值范围处理得来的。在局部强烈光照下或者均匀光照下,还是弱光环境或者强光环境,人眼能够感受到相同的颜色,但是数码相机的传感器会量化出不同的像元值。RGB的取值对应了固定的颜色,不同环境下传感器会量化出的像元值要怎么才能映射为一致的颜色?这个技术就叫做宽动态。为了宽动态处理结果更细腻,传感器的量化范围通常更大。如下图,左侧是关闭了宽动态的效果,在这个图上要想把手机检测出来几乎是不可能的。

由于数码相机做过了宽动态处理,对普通数码照片进行归一化,可以简单的将0-255线性映射到0-1。而医学图像、遥感图像则不能简单的利用最小最大像元值归一化到0-1。由于白噪声的存在,医学图像、遥感图像的直方图通常如下图所示(横轴代表像元值范围,红色纵轴表示归一化后的取值,绿色纵轴表示不同像元值的像素频数,绿色曲线就是直方图)。
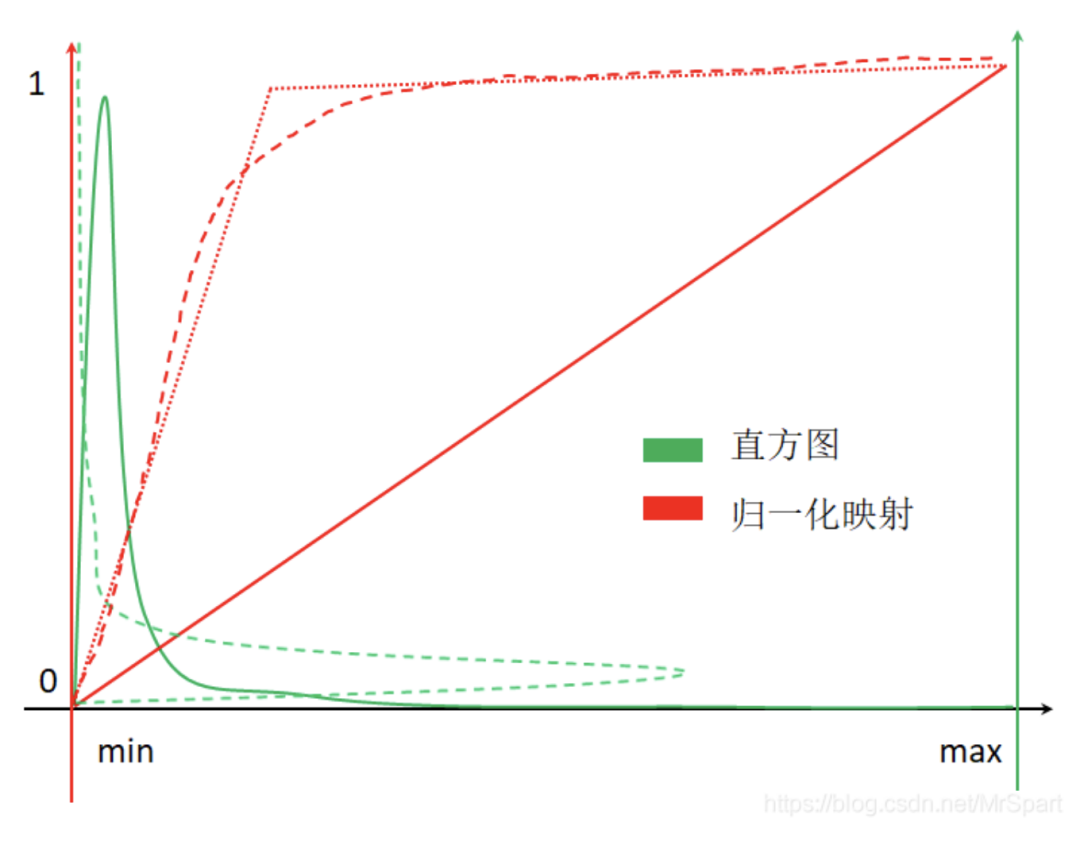
如果按照红色实线代表的归一化映射进行处理,最终绝大多少像素取值集中在0附近,整幅图像一片黑(翻转后的绿色虚曲线就是归一化后的直方图。最佳的处理方式是按照红色长线段虚线代表的映射进行归一化,但是这个映射难以求解,一般按照红色点虚线代表的映射进行处理就行。
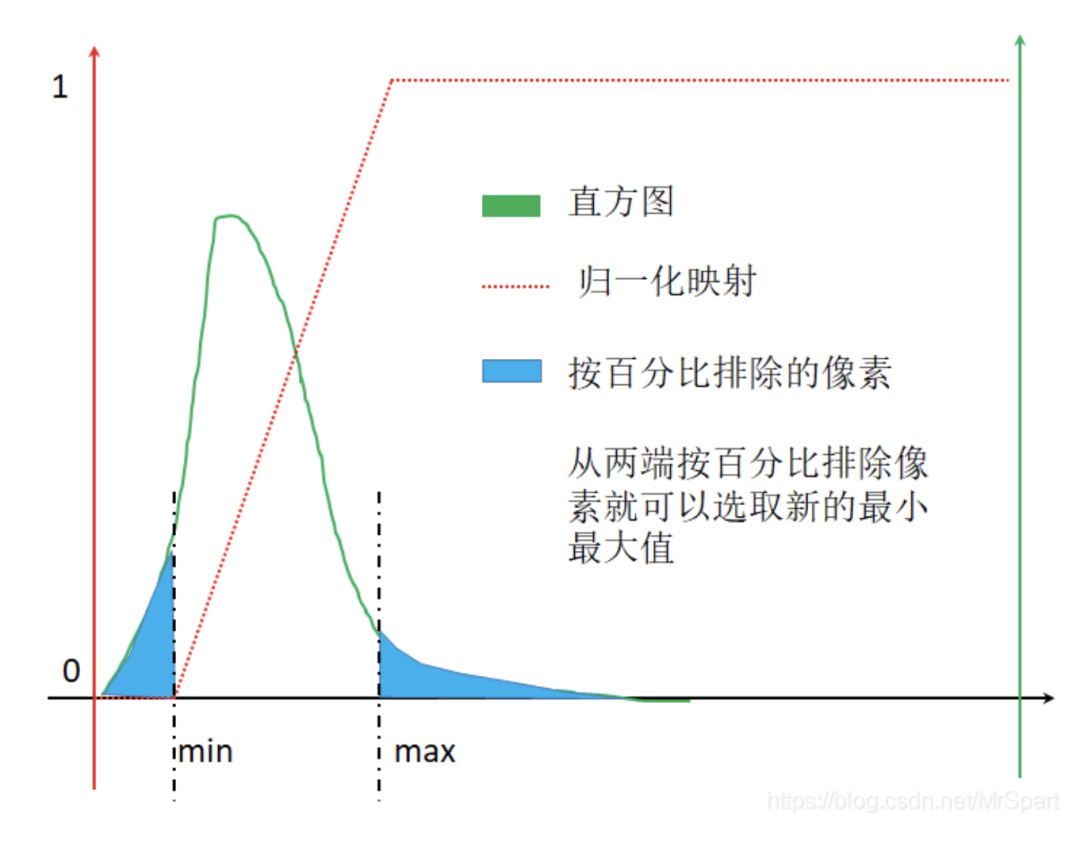
红色点虚线代表的映射其实挺简单的,选取合适的最小最大值,小于最小值的置为0,大于最大值的置为1,中间的线性映射。最大最小值的选取方法有均值+-x*标准差和排除两端一定占比的像素。排除两端一定占比的像素的示意图如下,从两端按照百分比排除像素时就能够选取新的最小最大值,此时的归一化映射图像为红色点虚线。
样本图像的尺寸仅与内存、显存大小有关吗?
如果栅格的边长减去1后不能被stride整除,卷积的降采样过程会丢弃边缘的像素,结果是特征图像素与输入图像位置映射会产生偏移。最终的特征图是不能完整映射到输入图像范围的,拿一个错位的特征图像素去预测原图上的目标,想想都不靠谱。目前所有的深度学习框架都没有考虑这里的映射错位关系,就算用Mask-RCNN提供的ROIAlign也是错位的。
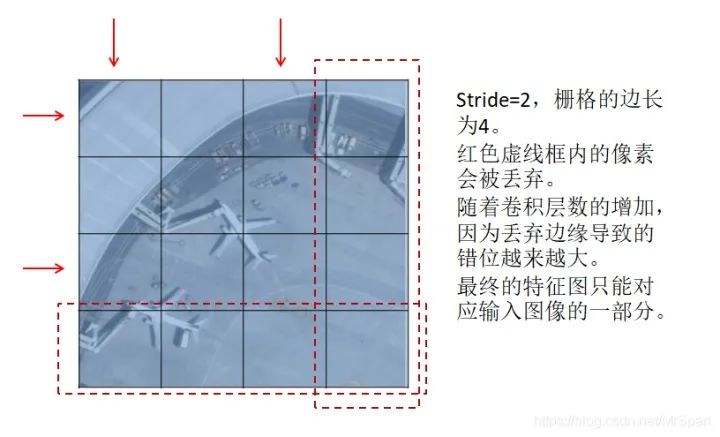
所以训练时输入样本图像的大小和检测时切块的大小只能用最终特征图的尺寸反推回去,保证在卷积过程中不丢弃边缘。
网络能检测的目标框范围只与图像大小有关吗?
感受野是直接或者间接参与计算特征图像素值的输入图像像素的范围,直接感受野就是卷积核大小,随着卷积层数的加深之前层次的感受野会叠加进去。感受野小了缺乏环境信息,感受野大了引入太多环境干扰,所以一个网络能够检测的目标框范围与特征图像素或者特征向量的感受野有关,通常能够检测的目标框边长范围是感受野边长的0.1-0.5倍。
详细结论参考论文:Understanding the effective receptive field in semantic image segmentation
https://www.onacademic.com/detail/journal_1000040207575210_3759.html
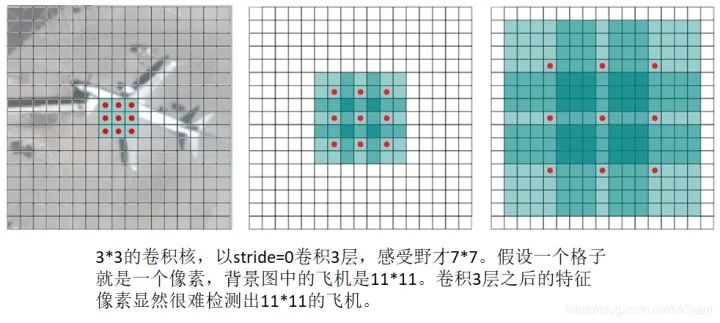
拿到了一个网络要做感受野分析,然后确定它能够检测多少像素的目标。实际目标检测任务需要综合网络结构设计和图像分辨率选择。如果目标框的像素范围超过了网络的感受野,就需要将原始图像缩小后再检测。
卷积网络真的具有平移和旋转不变性?
直觉上同一个卷积核,只要不是中心对称的像素团,旋转之后的卷积值肯定是不一样的,也就是说卷积网络显然不具有旋转不变性。那么卷积是否具有平移不变性呢?好像具有平移不变性啊,同一个像素团不管放在哪里,只要卷积核对齐了,卷积值都是一样的。但是不要忘记了padding,每一层卷积都加padding的话,图像边缘的像素混入的padding影响肯定更大。对于卷积网络来说,同一个像素团离图像中心的距离不同卷积值肯定是不同的,所以加了padding的卷积网络平移不变性也是不存在的。不带padding的网络每一层都必须进行严密的设计,就像不带padding的UNet一样的,显然是很麻烦的。通常为了网络设计的简单,对训练样本做平移增广是很有必要的。
可能有些人还记着以前关于CNN具有各种不变性的尬解释,转不过来弯的读读下面的论文,CNN啥不变性都没得,就靠蛮力拟合大量得数据。
Making Convolutional Networks Shift-Invariant Again SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Mind the Pad -- CNNs Can Develop Blind Spots On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location How much Position Information Do Convolutional Neural Networks Encode Why do deep convolutional networks generalize so poorly to small image transformations
制作目标检测训练样本的最佳方案是什么?
1.做感受野分析,确定能够检测目标边长范围
这一步得自己算。现成的网络都能搜到别人算好的结果,拿来直接用。
2.用最终特征图的尺寸反推训练样本图像的尺寸
这一步也得自己算。有了目标边长范围,选择大于目标框最大边长2倍左右的训练样本图像的尺寸。
3.对原始样本图像进行旋转和成像效果变换增广
这一步得写代码。目前广泛使用的正框样本库,旋转之后范围框更加不准,没得意义。如果自己要做样本记得一定要用倾斜范围框去标注,这样才能做旋转样本增广,从倾斜范围框生成的正框准一些。旋转增广有现成的工具可以用,但是都是基于正框实现的,这里有一个基于python和opencv实现的(https://github.com/XuelianZ/augment)。
成像效果变换样本指,通过直方图匹配等算法,仿真夜晚、雾、雨、雪等天气情况的成像效果。
为什么这两种增广放到切图之前?对于成像效果变换来说需要的统计信息越准确越好,切成小图之后难以得到较好的算法效果。对于旋转来说,切完图进行旋转,必然要填充值。填充值属于人为制造的伪显著区域,不符合检测时的实际情况。
4.对原始样本图像进行切图,切图的同时可以做平移样本增广
这一步还得写代码。已经有的工具很多都是简单的切图,只能支持0-255的普通数码照片,也没有考虑到能够检测的目标边长范围。如果有超过能够检测的目标边长范围的范围框,需要对图像进行缩小,且要将这个缩小比率记录下来。检测目录时也要按这个缩放比率进行检测。对于医学图像、遥感图像在切图过程中需要进行归一化处理。归一化参数需要从原始大样本图像上计算出来,切完的小图的统计信息不够全面,归一化参数可能不够好。
5.其它样本增广操作
比如翻转、加噪、拼接、抠洞、缩放等等,这些操作可以在训练过程中随机执行。个人认为拼接、抠洞、缩放对工程应用来说没有意义。拼接增广指随机找几张图各取一部分或者缩小之后拼起来作为一幅图用,拼接出来的图有强烈的拼接痕。抠洞指随机的将目标的一部分区域扣掉填充0值。拼接、抠洞属于人为制造的伪显著区域,不符合实际情况,白白增加训练量。
拼接的一个作用是增加了小目标样本的数量,其实平移增广也可以增加小目标样本的数量。因为小目标可以在图像范围内平移的次数更多。
训练过程随机缩放也是没必要的,缩放之后的图像可能会导致特征图和输入图像映射错位(参考“样本图像的尺寸仅与内存、显存大小有关吗?”);另外工程应用过程中控制好成像距离就能控制目标尺寸范围。仅采集符合所设计目标尺寸范围的样本图像即可。
强烈推荐的训练样本图像制作工具(切图工具)
这套工具在切图过程中实现了两种归一化方案和平移增广,输出图像可以选择输出为0-1或者0-255,输出到0-255的图像可以用普通看图工具查看。输出到0-1的图像数值精度高一些,可能训练效果会好一些。对于普通数码照片,因为原来取值范围就是0-255,仅以0和255作为最小最大值做个线性映射,不会选取新的最小最大值。这套工具还包含一个统计范围框宽高范围并确定切图缩放比率的工具。
这套工具仅支持yolo格式的范围框标注,范围框坐标可以是归一化的也可以是不归一化的。建议做样本时不要归一化坐标,整数的坐标值还是更准一些,可以利于其它处理。
(一)范围框宽高统计工具
是命令行工具,有6个参数,参数之间用空格分开。
输入目录 范围框标注格式 c,cx,cy,w,h 输出目录 输入文件扩展名,多个扩展名用半角逗号分隔 输入影像的比例尺,0表示从影像中读取,没有空间参考的影像的比例尺默认为1,普通照片就是没有空间参考的,遥感影像才有空间参考 输出样本图片边长 裁剪出的样本图片上的目标框边长范围,有四个值半角逗号分隔,头两个是“按照所需缩放比例缩放之后最佳目标框边长的范围”,后两个是“按照所需缩放比例缩放之后有效目标框边长的范围”
“最佳目标框边长的范围”指需要对图像进行缩放,让所有的范围框的边长都能落入这个范围。“有效目标框边长的范围”指按照某个比例缩放后,还是有目标框不能落在最佳范围,但是只要在有效范围内就保留。
下面是一个运行示例,路径参数中有空格需要用半角引号包起来。
sidelen_cwh.exe "D:\DOTA v1.5\train\images\images" D:\Test png,jpg 0 576 21,405,10,567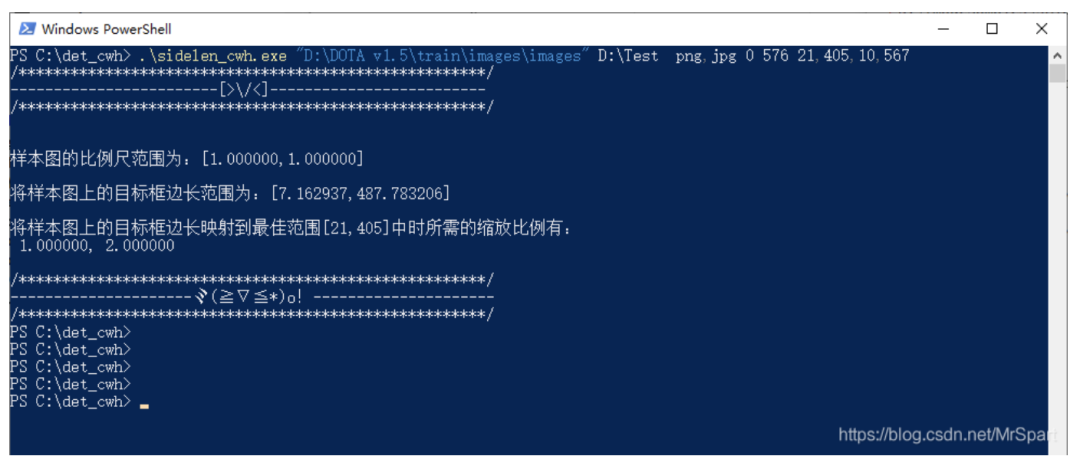
这个工具会输出一个文本文件STATS.txt。其中内容为
1.000000,2.0000001.000000,1.0000007.162937,487.783206
这里为了兼容遥感影像,引入了比例尺的概率。第一行缩放比例是一个像素对应的地理长度,普通数码照片的比例尺默认为1,还有一个为2的缩放比例,意思是将图像宽高都缩小为原来的二分之一。第二行是所有图像的原始比例尺范围,因为没有空间参考,所以比例尺都是1。第三行是范围框边长的范围,以地理长度为单位的,如果没有空间参考也就是像素单位。
从中可以看出DOTA数据集范围框边长的最大值有488,对于yolov3的感受野来说不能全都检测出来,除了在原始比例尺检测外,还得在缩小后的图像上检测。当然训练也是一样的需要在多个比例尺上进行。
(二)训练样本裁剪工具
也是命令行工具,有12个参数,参数之间用空格分开。
输入目录 范围框标注格式 c,cx,cy,w,h 输出目录 输入文件扩展名,多个扩展名用半角逗号分隔 输入影像的比例尺,0表示从影像中读取,没有空间参考的影像的比例尺默认为1,普通照片就是没有空间参考的,遥感影像才有空间参考 输出样本的比例尺,也就是缩放比例,多个值用半角逗号分隔。采用范围框宽高统计工具输出文件的第一行。 输出样本图像的通道组合,将原始样本图像的多个通道按顺序输出,通道编号从1开始 归一化映射参数,有mg、mo、sg、so四种方式,其后跟的数值是相应方式的归一化参数。m表示最大最小值拉伸,其后的数值表示像元数目截断的百分比;s表示均值加减标准差拉伸,其后的数值表示标准差的倍数;g表示拉伸到0-255,如果本来就是8位的则不拉伸;o表示拉伸到0-1,如果本来就是8位的则直接将0-255映射到0-1。 输出样本图片边长 裁剪出的样本图片上的目标框边长范围,与范围框宽高统计工具一致。 进行样本增广时目标框平移的最小像素数量和平移量占范围框宽高的比值,当比值乘以实际范围框宽高小于最小平移量时仍然按最小平移量移动。 目标范围框在裁剪图像范围内的部分占比的阈值,超过这个值才保留。切图之后范围框跑到图像外了,需要排除。 目标框宽高聚类数目。
下面是一个运行示例,路径参数中有空格需要用半角引号包起来。
splitimg_cwh.exe "D:\DOTA v1.5\train\images\images" D:\Test png,jpg 0 1 1,2,3 sg2.5 576 21,405,10,567 237,0.65 0.67 9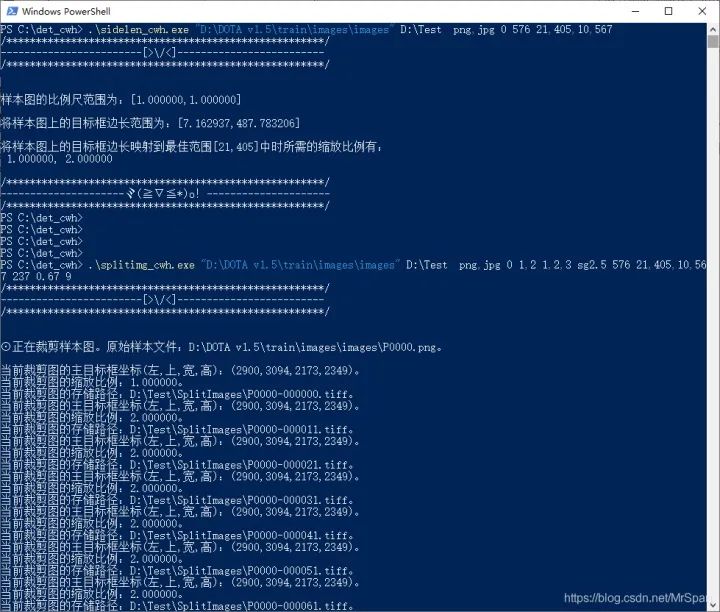
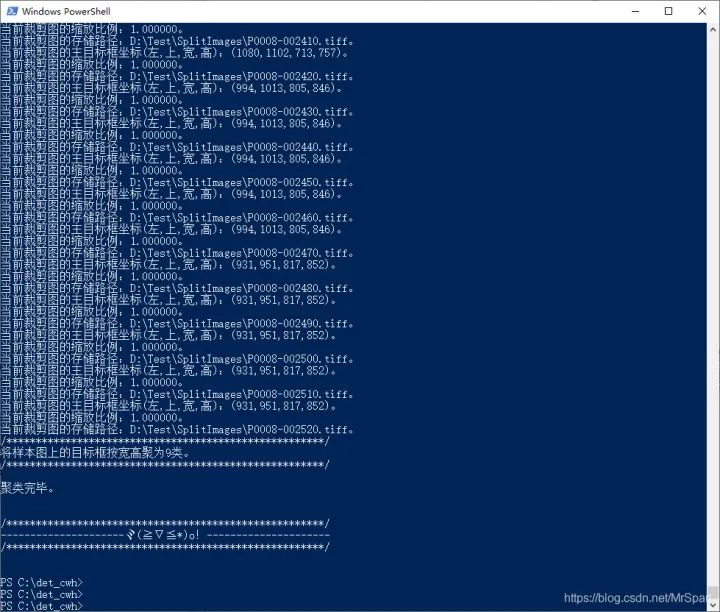
这个工具除了输出裁剪出来的样本外,还会输出一个文本文件ANCHORS.txt和一个图像HIST.tif。
ANCHORS.txt其中内容为
20,20, 57,45, 104,78, 150,139, 169,179, 25,89, 30,169, 42,329, 122,407这是范围框宽高的聚类中心,可以直接用做yolo的锚点框。
HIST.tif是范围框的二维统计直方图,像素值累计了各个宽高的范围框数量。利用范围框的二维累计直方图可以加快聚类。

裁剪出来的样本图像如下。
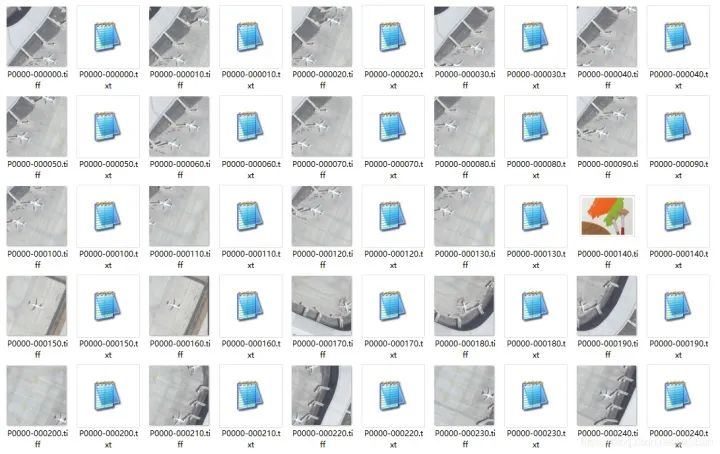
挑选了几个方块图,把范围框叠加显示看看平移增广的效果。

det_cwh.zip-深度学习文档类资源
https://download.csdn.net/download/MrSpart/17933383
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!