超越所有YOLO检测模型,mmdet开源当今最强最快目标检测模型!
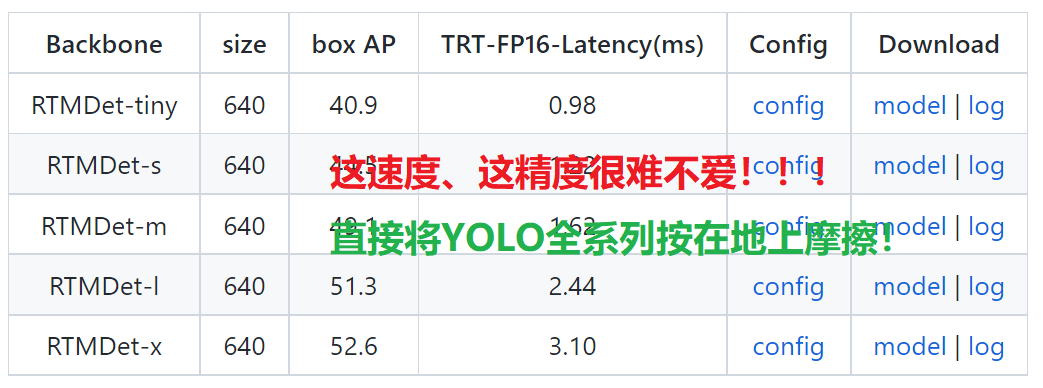
0、直接上架构图吧!
看着上面的图,熟悉不?是不是满满的YOLO系列的味道?是的,看代码我猜应该是基于YOLO来进行的增量实验吧,也仅仅是猜啦,毕竟暗俺也没看到RTMDet的论文,俺也不是开发者!
1、改进点1 —— CSPNeXt
1.1 Backbone 部分
话不多说,直接上代码:
class CSPNeXtBlock(BaseModule):
def __init__(self,
in_channels: int,
out_channels: int,
expansion: float = 0.5,
add_identity: bool = True,
use_depthwise: bool = False,
kernel_size: int = 5,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU'),
init_cfg: OptMultiConfig = None) -> None:
super().__init__(init_cfg=init_cfg)
hidden_channels = int(out_channels * expansion)
conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
self.conv1 = conv(
in_channels,
hidden_channels,
3,
stride=1,
padding=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.conv2 = DepthwiseSeparableConvModule(
hidden_channels,
out_channels,
kernel_size,
stride=1,
padding=kernel_size // 2,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.add_identity = add_identity and in_channels == out_channels
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.conv2(out)
if self.add_identity:
return out + identity
else:
return out
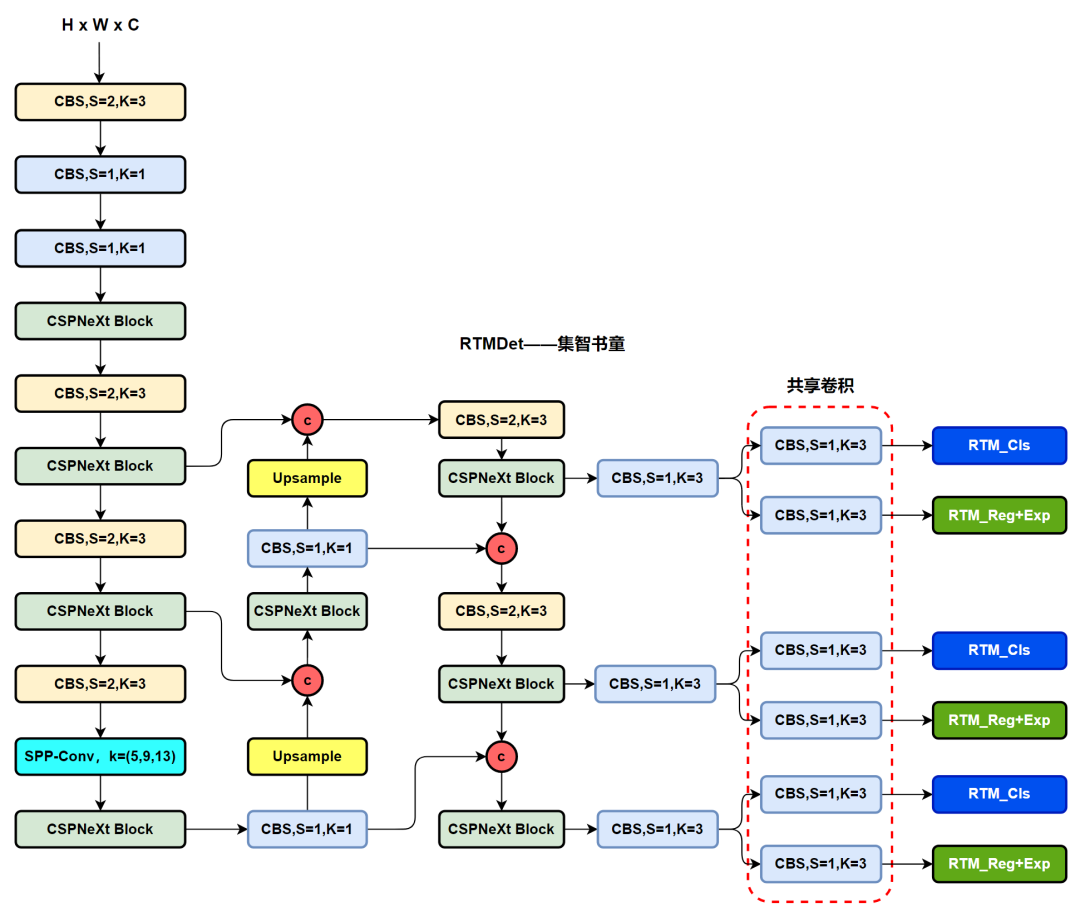
其实通过代码我们可以很直观的看出模型的架构细节,这里小编也进行了简要的绘制,具体如下图:
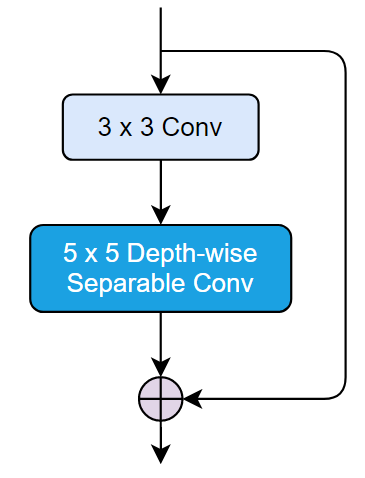
这里提到的 Depthwise Separable Convolution 是 MobileNet 的基本单元,其实这种结构之前已经使用在 Inception 模型中。Depthwise Separable Convolution 其实是一种可分解卷积操作,其可以分解为2个更小的操作:Depthwise Convolution 和 Pointwise Convolution,如图所示。
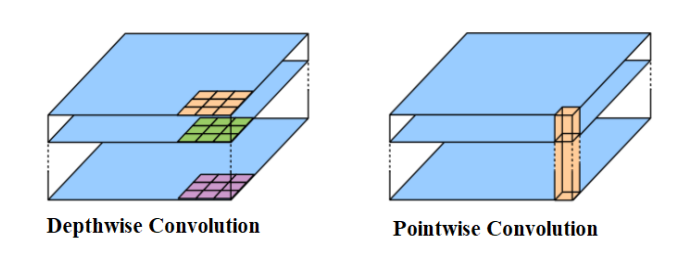
Depthwise Convolution 和标准卷积不同,对于标准卷积,其卷积核是用在所有的输入通道上(input channels),而 Depthwise Convolution 针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说 Depthwise Convolution 是 Depth 级别的操作。
而 Pointwise Convolution 其实就是普通的 1×1 的卷积。对于 Depthwise Separable Convolution,首先是采用 Depthwise Convolution 对不同输入通道分别进行卷积,然后采用 Pointwise Convolution 将上面的输出再进行结合,这样整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
熟悉DarkNet的朋友应该都知道,如果你不知道,小编这里也给出架构图:
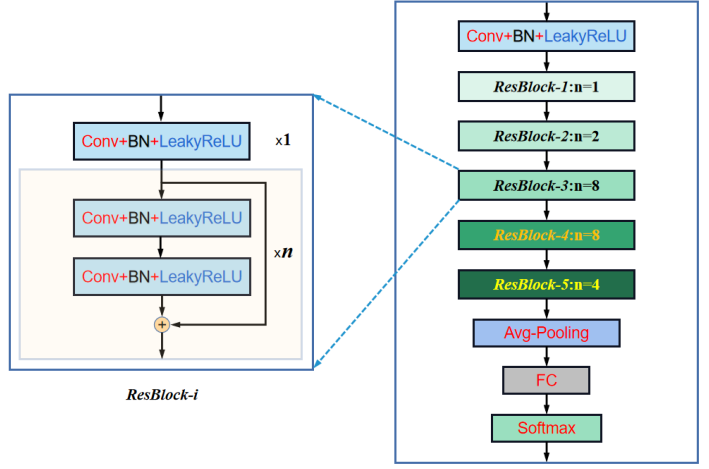
然后依旧是直接上CSPLayer的代码:
class CSPLayer(BaseModule):
def __init__(self,
in_channels: int,
out_channels: int,
expand_ratio: float = 0.5,
num_blocks: int = 1,
add_identity: bool = True,
use_depthwise: bool = False,
use_cspnext_block: bool = False,
channel_attention: bool = False,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='Swish'),
init_cfg: OptMultiConfig = None) -> None:
super().__init__(init_cfg=init_cfg)
block = CSPNeXtBlock if use_cspnext_block else DarknetBottleneck
mid_channels = int(out_channels * expand_ratio)
self.channel_attention = channel_attention
self.main_conv = ConvModule(
in_channels,
mid_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.short_conv = ConvModule(
in_channels,
mid_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.final_conv = ConvModule(
2 * mid_channels,
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.blocks = nn.Sequential(*[
block(
mid_channels,
mid_channels,
1.0,
add_identity,
use_depthwise,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg) for _ in range(num_blocks)
])
if channel_attention:
self.attention = ChannelAttention(2 * mid_channels)
def forward(self, x: Tensor) -> Tensor:
x_short = self.short_conv(x)
x_main = self.main_conv(x)
x_main = self.blocks(x_main)
x_final = torch.cat((x_main, x_short), dim=1)
if self.channel_attention:
x_final = self.attention(x_final)
return self.final_conv(x_final)
其结构如下所示,毫无疑问依旧是香香的CSP思想,但是这里的结构使用了5×5的DW卷积,实现了更少的参数量的情况下,带来更大的感受野。
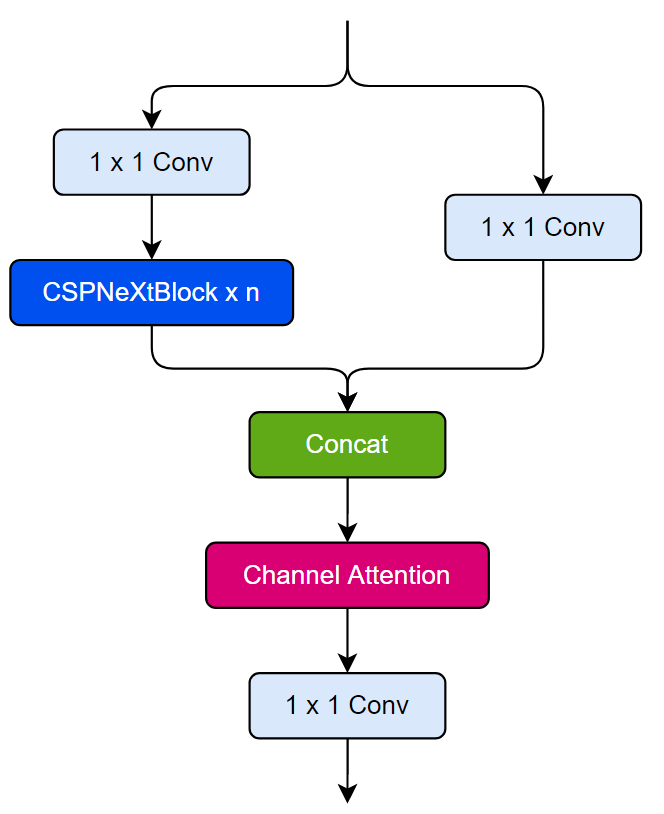
同时这里RTMDet的Backbone中还考虑了通道注意力的问题,其代码如下:
class ChannelAttention(BaseModule):
def __init__(self, channels: int, init_cfg: OptMultiConfig = None) -> None:
super().__init__(init_cfg)
self.global_avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Hardsigmoid(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = self.global_avgpool(x)
out = self.fc(out)
out = self.act(out)
return x * out
小编依旧给小伙伴们画了示意图:
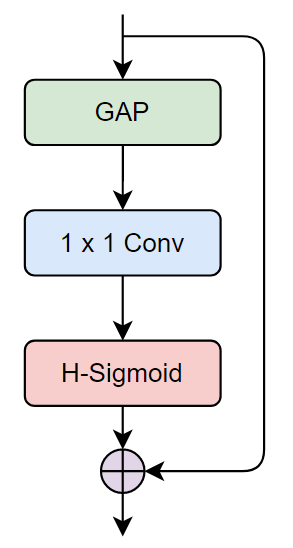
其实还有一个细节,这里我想的也不是很明白,如果熟悉ResNet构建的小伙伴应该知道,凯明大神在构建ResNet50是使用的残差Block的数量配比就是[3,6,6,3],

这里RTMDet使用的配比也是:
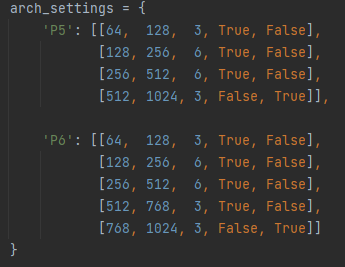
但是小编在白嫖 TRT-ViT、NeXtViT、SWin以及ConvNeXt的时候都在或有或无地说逐层增加配比会带来更好的结果,这里不知道为什么RTMDet选择以前的数据,期待论文中的描述和解释!
1.2 Neck部分
其实也是毫不意外的PAFPN的架构,只不过这里作者选择把YOLO系列中的CSPBlock替换为了本方法中的CSPNeXt Block,具体架构图如下所示:
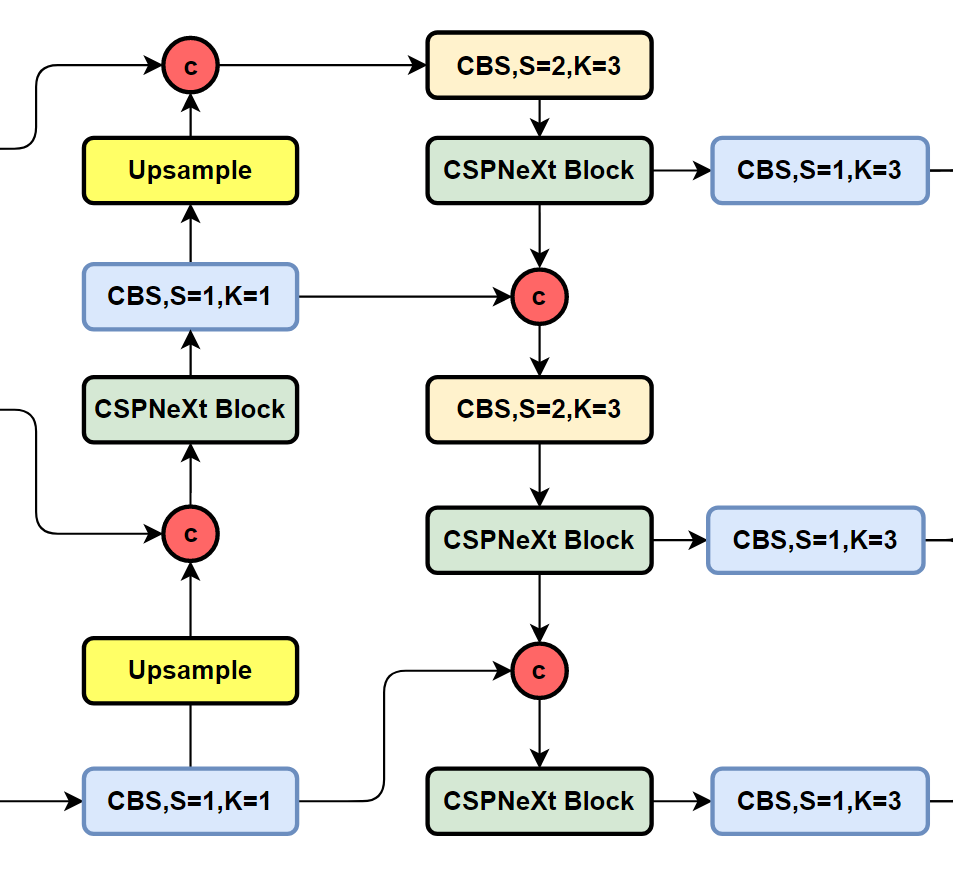
1.3 Head部分
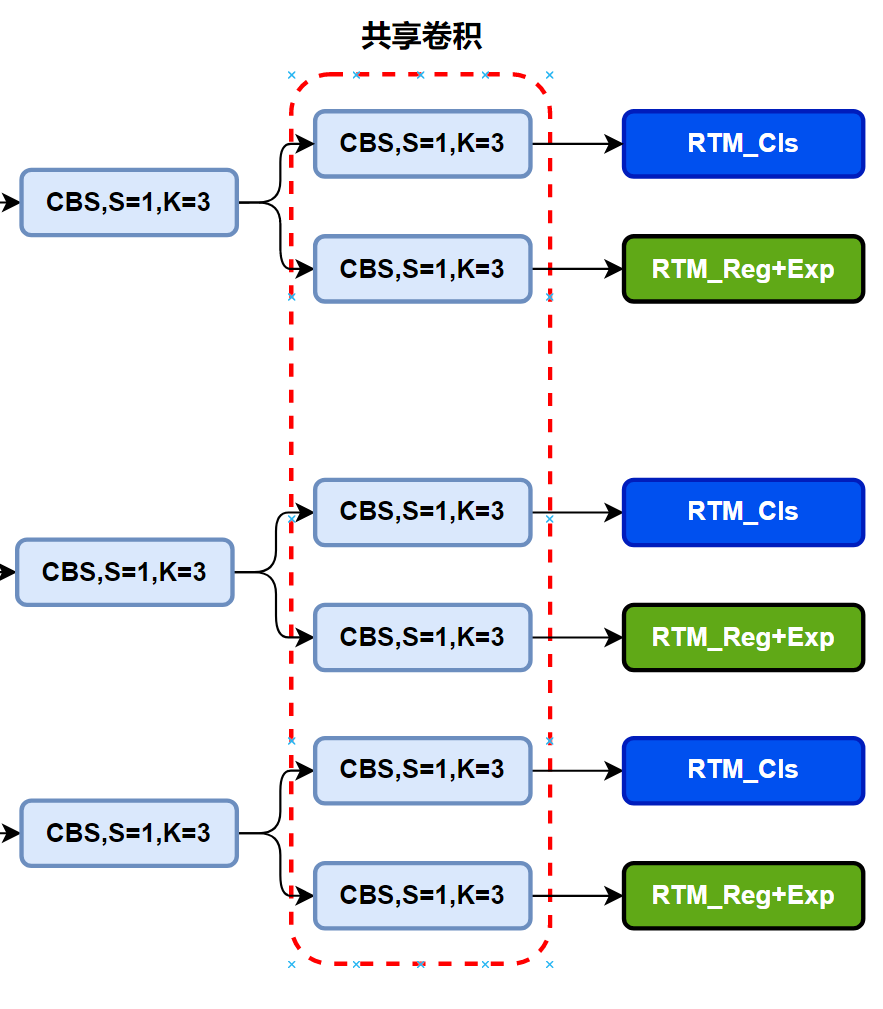
这部分也是相对比较常规的设计,对于PAFPN结构输出的特征,先使用由堆叠的卷积所组成的分类分支以及回归分支提取对应的分类特征和回归特征,然后分别送到对应的RTM分类分支和回归分支,得到我们最终随需要的东西,这里有一个小小的细节,便是堆叠的卷积在不同level的中是共享权重的,具体可以参见代码,这里也不进行过多的猜测,最终还是以论文为主。
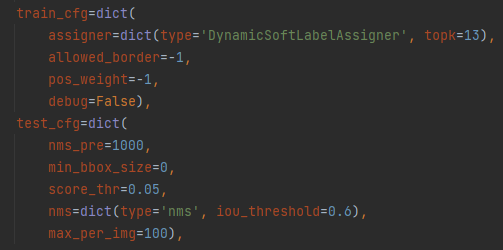
2、匹配策略
直接上配置参数,熟悉Nanodet的小伙伴你是不是又知道了!嗯,是的是熟悉的味道,就是NanoDet-Plus的哪个策略,依旧很香,依旧很好用!!!
当年的Nanodet-Plus是这样的:
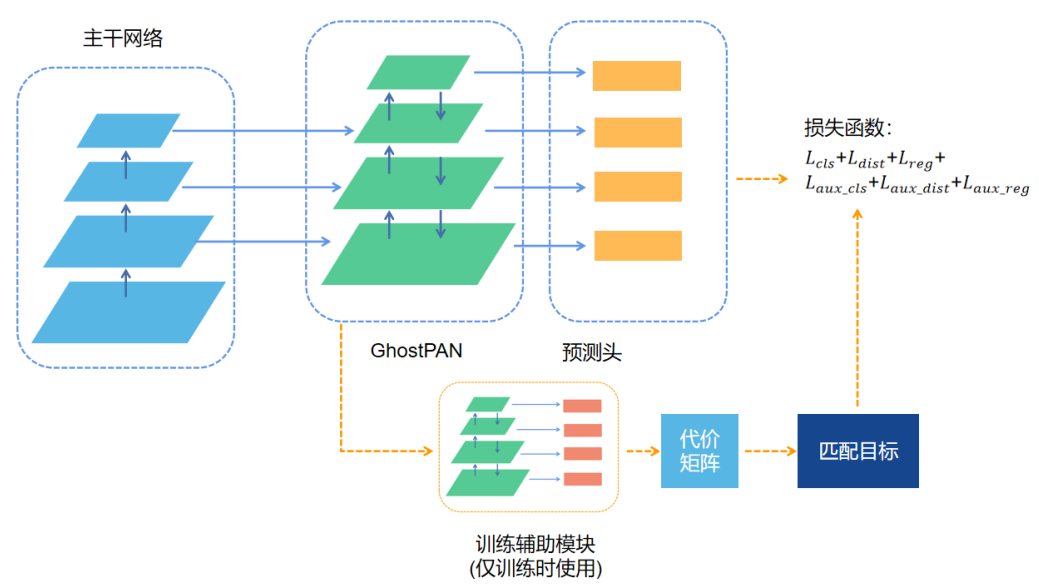
这里所谓动态匹配,简单来说就是直接使用模型检测头的输出,与所有Ground Truth计算一个匹配得分,这个得分由分类损失和回归损失相加得到。特征图上N个点的预测值,与M个Ground Truth计算得到一个N×M的矩阵,称为Cost Matrix,基于这个矩阵可以让当前预测结果动态地寻找最优标签,匹配的策略有二分图匹配、传输优化、Top-K等,在NanoDet中直接采取了Top-K的策略来匹配。
这种策略的一个问题在于,在网络训练的初期,预测结果是很差的,可能根本预测不出结果。所以在动态匹配时还会加上一些位置约束,比如使用一个 5×5 的中心区域去限制匹配的自由程度,然后再依赖神经网络天生的抗噪声能力,只需要在Ground Truth框内随机分配一些点,网络就能学到一些基础的特征。
3、损失函数
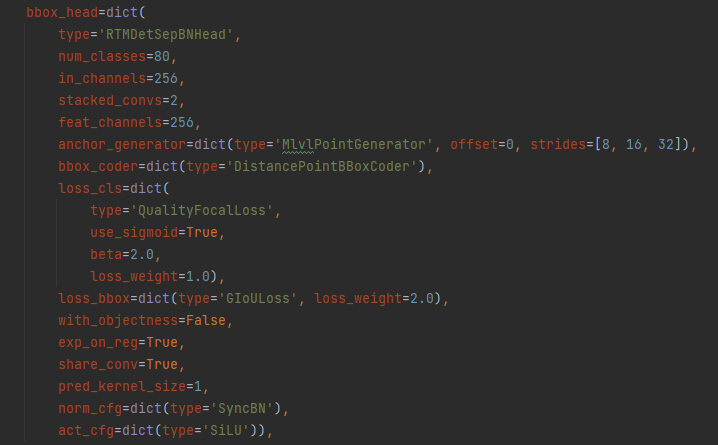
这部分主要是是用来QFL和GIOU Loss,这里不进行过多描述,以后尽可能补上吧,今天太累了,已经太晚了。。。。
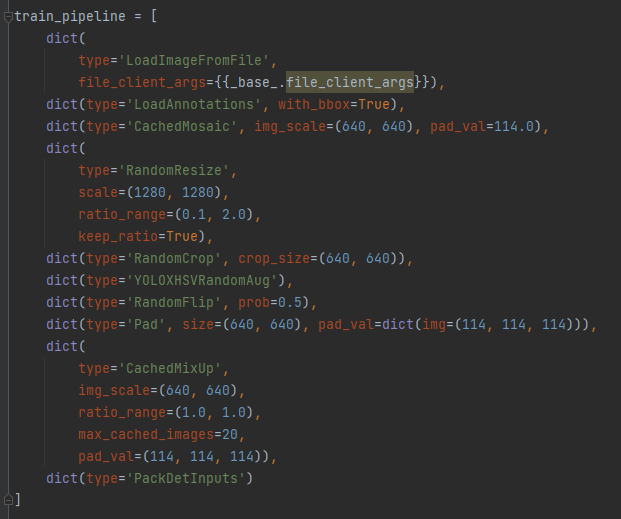
4、输入端部分
阶段一
作者在训练的第一阶段,主要是使用了CacheMosaic数据增强,RandomResize,RandomCrop,RandomCrop,CacheMixup以及YOLOX关于HSV的一些增强手段,这里的CacheMosaic以及CacheMixup是mmdet中全新提出的新Trcik炼丹术;
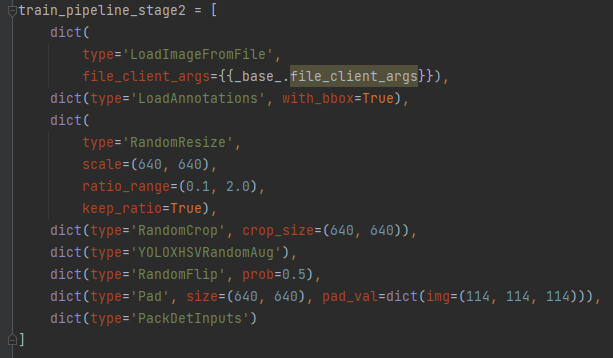
阶段2
作者在训练阶段2提出了前面提出的新技术,CacheMosaic以及CacheMixup,看样子这里应该是学习YOLOX的训练技术:
4.1、CacheMosaic
1、Mosaic流程:
选择Mosaic中心作为4幅图像的交点。 根据索引获取左上图,从自定义数据集中随机抽取另外3张图片。 如果图像大于Mosaic Patch,子图像将被裁剪。
2、CacheMosaic流程:
将上次Transform的结果加到Cache中。 选择Mosaic中心作为4幅图像的交点。 根据索引获取左上图,从结果缓存中随机抽取另外3张图片。 如果图像大于Mosaic Patch,子图像将被裁剪。
优点我猜就是训练快!!!
4.2、CacheMixup
1、Mixup
另一个随机图像被数据集挑选并嵌入到左上角的Patch中(在填充和调整大小之后) mixup变换的目标是mixup image和origin image的加权平均。
2、CacheMixup
将上次Transform的结果加到Cache中。 从Cache中挑选另一个随机图像并嵌入到左上角的Patch中(在填充和调整大小之后) mixup变换的目标是mixup image和origin image的加权平均。
参考
[1].https://github.com/RangiLyu/mmdetection/tree/rtmdet_config/configs/rtmdet.

分享
收藏
点赞
在看