本文约2200字,建议阅读5分钟
本文为你介绍强化学习和遗传算法不同之处,适用于那些情况。
强化学习(Reinforcement Learning)和遗传算法(Genetic Algorithm)都是受自然启发的AI方法,它们有何不同?更重要的是,在哪些情况下,其中一种会比另一种更受青睐?”因此,今天我们将尝试解释这些原因。
他们是什么... ?
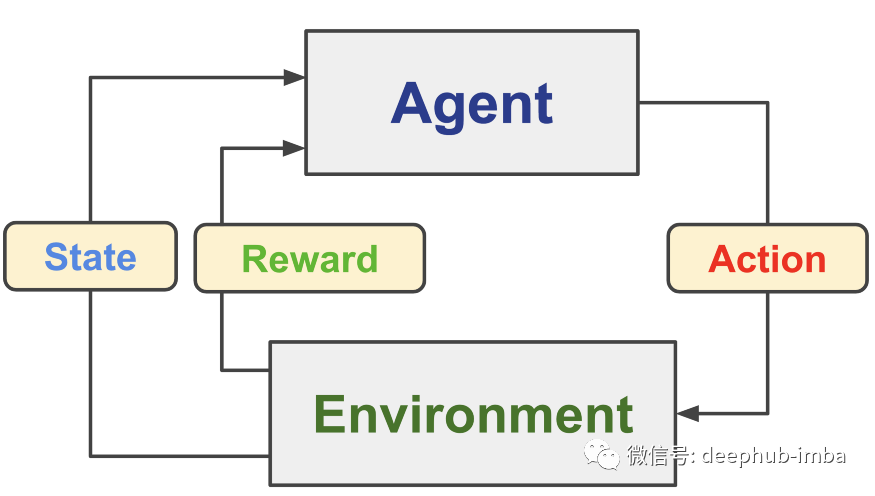
在我们开始比较之前,让我们更好地理解这些是什么……强化学习是训练机器学习模型以做出一系列决策。它被构造为与环境交互的代理。
在强化学习中,人工智能 (AI) 面临类似游戏的情况(即模拟)。人工智能通过反复试验来提出问题的解决方案。智能体缓慢而稳定地学习在不确定的、潜在复杂的环境中实现目标,但我们不能指望智能体盲目地偶然发现完美的解决方案。这是交互发挥作用的地方,为代理提供了环境状态,这成为代理采取行动的输入/基础。一个动作首先向代理提供奖励(注意,根据问题的适应度函数,奖励可以是正的也可以是负的),基于此奖励,代理内部的策略(ML 模型)适应/学习其次,它会影响环境并改变它的状态,这意味着下一个循环的输入会发生变化。这个循环一直持续到创建一个最佳代理。这个循环试图复制我们在自然界中看到的生物体在其生命周期中的学习循环。在大多数情况下,环境会在一定数量的循环后或有条件地重置。注意,可以同时运行多个代理以更快地获得解决方案,但所有代理都是独立运行的。遗传算法是一种搜索元启发式算法,其灵感来自查尔斯达尔文的自然进化理论。该算法反映了自然选择的过程,即选择最适合的个体进行繁殖以产生下一代的后代。
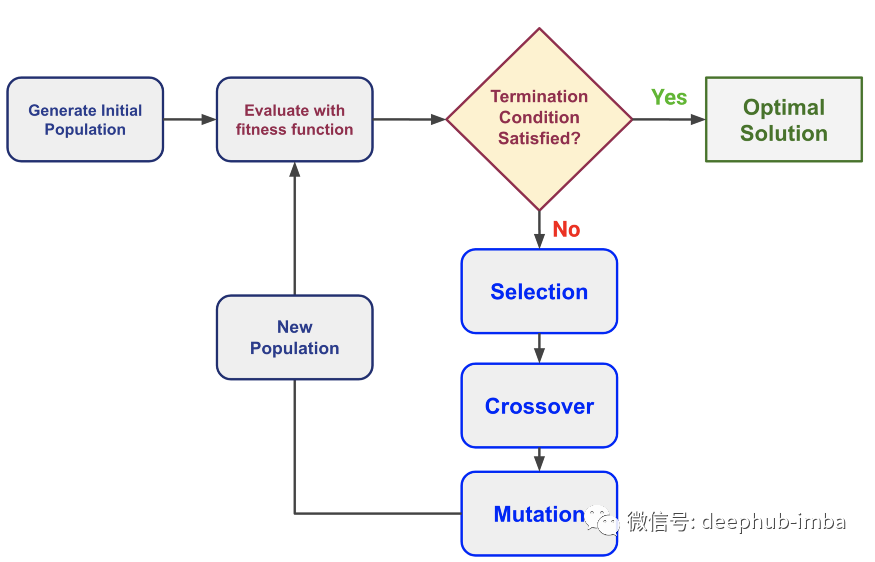
生成初始种群:一组“个体”被称为群体,其中每个个体的特征是一组以二进制表示的基因(即 0 或 1)。由字符串/序列表示的一组基因称为染色体。我们开始的人口称为初始人口。评估:适应度函数是一个系统,它确定一个人的健康程度(一个人与其他人竞争的能力)。它为每个人提供了一个适应度分数,这有助于量化表现。该函数在总体表现上执行,以量化和比较个体的表现。选择:挑选“最适合的”(基于评估阶段生成的适应度分数)个体以产生下一代(即下一个评估和繁殖周期的新种群)的过程。没有基于适应度分数的严格截止,但选择更多地基于概率(适应度分数越高,被选中的概率越高),并为下一阶段选择一对。交叉:混合选择的一对个体的基因以产生一对新个体的过程称为交叉或遗传操作。这个过程继续创造一个新的人口。交叉可以用不同的方法进行,例如:单点交叉、两点交叉、顺序交叉、部分映射交叉 、循环交叉。突变:在某些新个体中,他们的一些基因可能会以低随机概率发生突变。这意味着染色体(位序列)中的某些基因(位)可以改变(翻转)。突变有助于保持种群内的多样性并防止过早收敛。终止:当种群收敛时,算法终止。这里的收敛表示个体的遗传结构不再有显着差异。终止也可能在一定数量的循环后发生,这通常会导致多个收敛点。如何进行比较?
根据定义,遗传算法是一种跨生命的算法,这意味着该方法需要个体“死亡”才能前进。RL旨在成为一种生命内学习算法,最近开发的许多方法都针对持续学习和“安全RL”的问题。从根本上讲,这两种方法的操作原则是不同的。RL使用马尔可夫决策过程,而遗传算法主要基于启发式。RL中的值函数更新是基于梯度的更新,而GAs通常不使用这种梯度。RL是一种机器学习,它关注的是一种特定类型的优化问题,即寻找最大化回报的策略(策略),代理以时间步骤与环境进行交互。GAs是一种自学习算法,可以应用于任何优化问题,其中你可以编码解决方案,定义一个适应度函数来比较解决方案,你可以随机地改变这些解决方案。从本质上讲,GAs可以应用于几乎任何优化问题。原则上,您可以使用GAs来查找策略,只要您能够将它们与适应度函数进行比较。这并不意味着GA更好,这只是意味着如果没有更好的解决方案,GA将是你的选择。而RL对于需要在环境中进行顺序决策的问题是一个强有力的方案。遗传算法:需要较少的关于问题的信息,但设计适应度函数并获得正确的表示和操作可能是非常复杂和困难的。它在计算上也很昂贵。强化学习:过多的强化学习会导致状态过载,从而降低结果。这种算法不适用于简单问题的求解。该算法需要大量的数据和大量的计算。维数的诅咒限制了对真实物理系统的强化学习。怎么使用
正如我们已经讨论过的,除了根本的区别之外,这两种方法都有各自的用途和缺点。虽然GA的用途更广泛,但是定义一个适合问题的适应度函数以及正确的表示和操作类型是非常困难的。而RL最适合解决需要连续决策的问题,但需要更多的数据,当问题的维度较高时就不是很好。基于学习的早期阶段,RL模型也倾向于变得狭隘。由于明显的原因,当没有其他解决方案适合这种模式时,GA是最受欢迎的;
对于更简单的问题,大多数时候,RL是有效的,但通常比遗传算法更耗时,而且遗传算法的适应度函数和表示更容易编写,所以RL或遗传算法都可以根据问题工作;
当我们有中等程度的复杂性和高可用数据时,RL是首选;
对于具有更高复杂性的问题,GA和RL都需要花费大量时间,需要复杂的表示,或者受到需要处理的维数的限制。
二者结合
是的,结合遗传算法和强化学习是可能的,因为这两种方法不是相互排斥的。就像它们源于自然的两个原则一样,这些方法也可以共存。强化学习使代理能够基于奖励功能做出决策。然而,在学习过程中,学习算法参数值的选择会显著影响整个学习过程。使用遗传算法找到学习算法中使用的参数值,比如深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)结合后见经验回放(Hindsight Experience Replay, HER),以帮助加快学习代理。导致性能更好,比原来的算法更快。另一种方法是采用强化学习的部分,如Agent-Environment关系,并运行多个可以交叉和变异的代理,类似于遗传算法。