
SIGIR'21腾讯 FORM:元学习+FTRL+动态学习率
点击

蓝字关注,提升学习效率
title: FORM: Follow the Online Regularized Meta-Leader for Cold-Start Recommendation
link: https://dl.acm.org/doi/pdf/10.1145/3404835.3462831
from:SIGIR 2021

1. 背景
本文针对元学习在在线推荐系统的冷启动中存在的问题提出FORM学习框架,通过正则化的方式来缓解在线系统的波动以及产生稀疏的权重,并且提出可缩放的学习率使模型能更有效的适应新用户。现有的元学习方法存在的问题:
无法根据不同用户的历史记录的多样性对其进行评估,对所有用户都同等对待 难以抵抗在线系统的复杂波动 解决在线系统的巨大吞吐量具有挑战性
作者在文中列出了伪代码,感兴趣的小伙伴可以阅读
2. 基于元学习的推荐系统基本形式
用户集合表示为,画像为,商品集合为,商品画像为。表示用户和商品之间的交互,包括显式和隐式。在元学习框架下,将每一个用户u作为一个任务,表示和用户交互的商品的集合,将其分为支持集合查询集。目标是去学习未知的。主要包含三个部分:embedding and evaluation framework, local user-level gradient update principles, and global system-level update principles。
小概览
embedding and evaluation framework:生成相应特征的embedding,模型预测 local user-level gradient update principles:元学习中不同任务的梯度更新,在本文中就是不同用户构建为单个任务所以是user-level。 global system-level update principles:元学习中meta模型的参数更新,这里的meta就是在MAML(具体可以看预备知识中的元学习)中生成初始化参数的模型。
2.1 Embedding and Evaluation
将用户和商品的特征作为输入,用户特征表示为,商品特征表示为,分别包含对应的id和画像特征。经过MLP和ReLU激活函数可以得到对应的embedding,然后将其拼接后送入后续的模型进行预测。其中表示向量拼接。最终如下式计算损失函数后,进行梯度回传,这里笔者认为作者应该是举个例子,其他损失函数应该也是可以的,不唯一。
2.2 Local User-Level Update
局部和全局共享embedding和评估框架,但是在梯度更新的时候存在不同。传统机器学习是随机初始化参数,然后不断训练慢慢收敛。元学习,例如MAML,通过一些先验知识得到模型的初始化参数,然后可以使得模型能够快速收敛并具有较好的性能。
模型参数通过两层更新,分别为局部更新和全局更新。局部更新通过先验用户历史进行训练,公式如下,其中表示支持集,L()表示针对用户u的训练任务的损失函数,
2.3 Global System-Level Update
然后利用查询集,对用户集合U中的每个用户u的任务都用初始化,然后对每一个用户产生的损失求和,优化下面的损失。
对于每个用户u的任务来说,参数更新方式如下,
对于初始化参数来说,参数更新方式如下,
3. 方法
3.1 动机
现有的方法旨在学到一个好的初始化参数,这个参数可以可以在所有用户上都表现的好。但是这种方法难以处理在线场景,在线推荐系统中,支持集的用户是从波动和嘈杂的在线序列中随机选择的。此类训练质量有限的用户可能会进一步导致梯度退化和局部最优。如图1所示,元推荐的命中率偶尔会出现不必要的下降。更糟糕的是,每次元推荐的性能下降时,在训练过程中命中率的方差急剧增加,如图 1 的子图所示。因此,我们需要新的方法来控制在线性能并提供更多稳定的训练过程。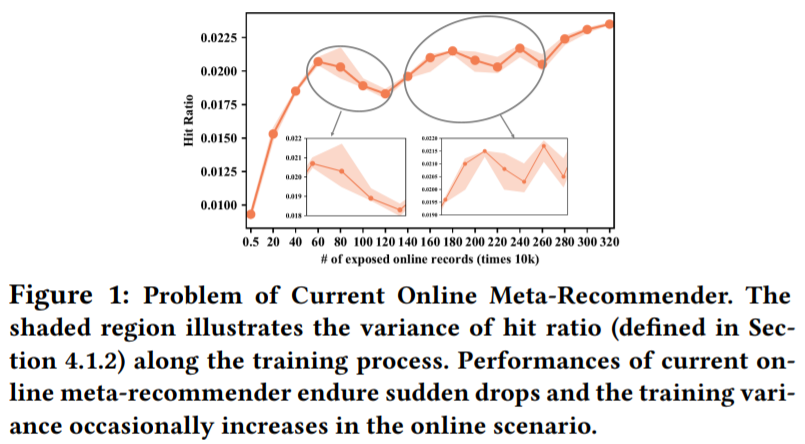
3.2 Follow the Online Regularized Meta-Leader
虽然元学习在离线情况下已经取得了较大成功,但是在在线推荐中还存在以下问题:
用户以在线顺序到达,因此需要设计方法来有效的学习在线梯度 由于在线系统的波动性,在梯度正确收敛之前可能会发生剧烈波动 不同用户在全局更新中都是同等对待的
本文作者提出了三个方法来解决上述问题:Follow the Online Meta Leader (FTOML), Follow the Regularized Online Meta Leader (FTROL), and Optimize the Online Scalable Learning Rate (SLR)。
如图所示为模型的流程图,首先,用户和商品被记录到缓冲区;然后从用户集合中提取一个batch,利用Local-Update结合FTROL算法对用户u在时刻t时的局部参数进行更新,并且只有小于阈值C的损失才送入全局参数更新,结合SLR为不同的用户提供不同的学习率。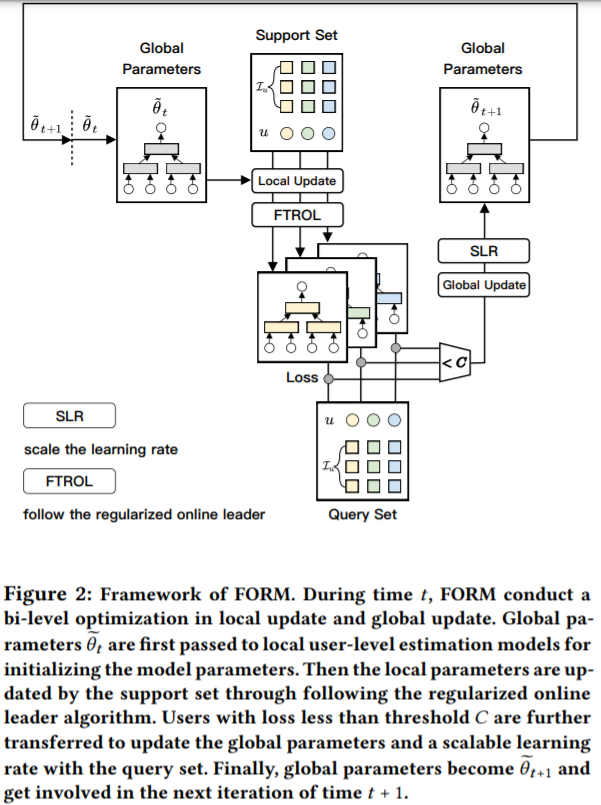
3.2.1 Follow the Online Meta leader
基于FTL(可看预备知识中的FTRL)算法,作者提出FTOML方法来进行在线局部参数更新。核心思想:将所有来自先前用户流的数据合并到一个元梯度学习步骤中,而不是仅考虑当前流中采样的记录。从而使得模型能够不仅准确预测当前记录也能预测之前的记录。目标函数为下式,其中损失函数表示用户u在时刻s的局部损失,D为用户u的训练数据集。
为了确保性能,作者设置了一个阈值𝐶 用于控制用户级模型的性能,只有当损失值小于阈值时,可以被用于更新全局参数。
3.2.2 Follow the regularized online meta leader
由于用户随机且不均匀地到达,因此参数会在不同的轮次中更新 波动性强,导致梯度下降不稳定。并且,参数越稀疏,在线计算效率越高,因此作者在FTOML的基础上加入正则项,提出FTROL来确保更新过程的一致性和稳定性和参数稀疏性。更新公式如下,其中为上述的正则项,公式如下,可以发现这里其实为FTRL和meta learning的结合,正则项就是FTRL的正则项,
可以将上式改写为下式,从而可以直接求得闭式解,
3.2.3 Optimize Scalable Online Learning Rate
这部分用于针对不同的用户应该给予不同的重视程度,对于历史信息少,且损失函数波动大的用户,应该从中抽取更少的元知识。作者设计一个可缩放的在线学习率,这个学习率可以衡量梯度的方差和历史数据的长度,用户u在k个商品下的最优学习率计算公式如下,其中α为原本的学习率,为梯度的方差,为梯度的期望。
4. 结果
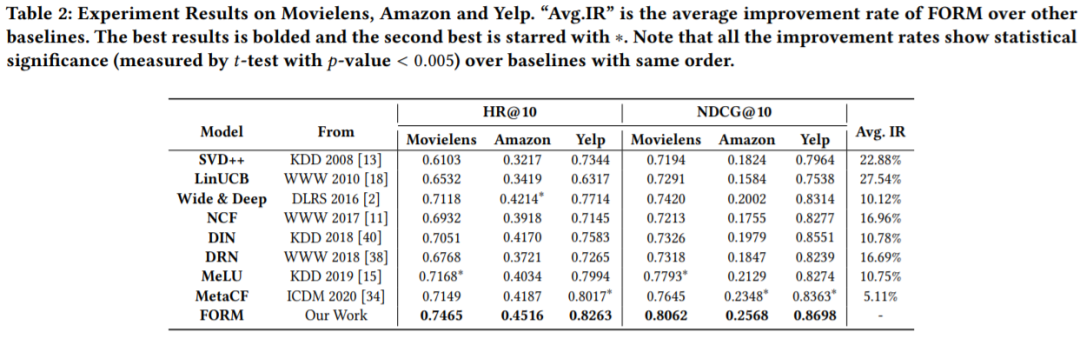
5. 总结
作者在文中讲解了往常基于元学习的推荐系统的大概流程,因此对于元学习如何应用于推荐系统不熟悉的小伙伴可以阅读这部分,另一方面,作者针对现有元学习方法应用于在线推荐系统的缺陷,将元学习和FTRL在线学习方法结合,并通过设计动态的学习率来对每一个用户提供不同的关注度,从而提升了总体上的性能。
点个在看你最好看
