
今晚世界杯来了,利用Python预测冠军(附全部代码)
完整代码和数据集, 回复 世界杯 获得。
今夜,2022年世界杯开始,世界各地的球迷都渴望知道:谁将夺取令人垂涎的奖杯?
如果你不仅仅是一个足球迷而且还是一个技术人员,我想你已经意识到机器学习和人工智能也是目前流行语。让我们结合这两个来预测哪个国家会赢得FIFA世界杯。

01
搞清楚目标是什么?
其实不难
目标是使用机器学习预测谁将赢得2022年世界杯足球赛。
预测整场比赛的单项比赛结果。
运行下一场比赛的模拟,例如四分之一决赛,半决赛和决赛。
这些目标提出了一种独特的真实世界机器学习预测问题,并涉及解决各种机器学习任务:数据整合,特征建模和结果预测。

02
数据是什么?
我使用了Kaggle的两个数据集。你可以在这里找到它们。我们将使用自1930年冠军开始以来所有参赛队的历史赛事结果。
限制:国际足联排名是在90年代创建的,因此缺乏大部分数据集。所以让我们坚持历史比赛记录。
环境和工具:jupyter笔记本,numpy,熊猫,seaborn,matplotlib和scikit-learn。
我们首先要对两个数据集进行一些探索性分析,做一些特征工程以选择最相关的特征进行预测,做一些数据处理,选择一个机器学习模型,最后将其部署到数据集上。
首先,导入必要的库并将数据集加载到一个,具体代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as ticker
import matplotlib.ticker as plticker
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
导入库,具体代码如下
#load data
world_cup = pd.read_csv('datasets/World Cup 2018 Dataset.csv')
results = pd.read_csv('datasets/results.csv')
加载数据集...
通过为两个数据集调用world_cup.head()和results.head(),确保数据集加载到数据框中,如下所示:
03
进行探索性分析
分析两个数据集后,所得数据集包含过去匹配的数据。新的(产生的)数据集对分析和预测未来的匹配很有用。
探索性分析和特征工程:涉及确定哪些特征与机器学习模型相关是任何数据科学项目中最耗时的部分。
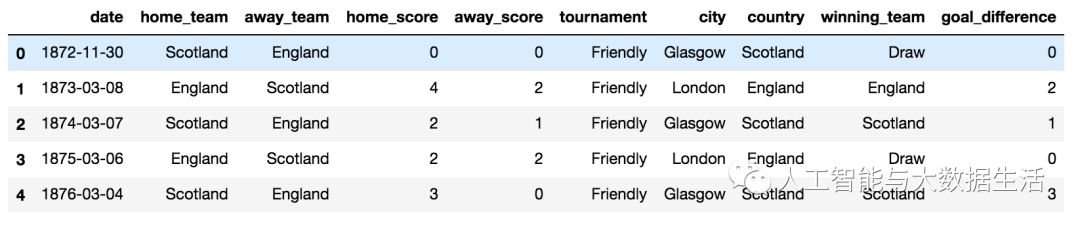
现在让我们将目标差异和结果列添加到结果数据集中。具体代码如下:
#Adding goal difference and establishing who is the winner
winner = []
for i in range (len(results['home_team'])):
if results ['home_score'][i] > results['away_score'][i]:
winner.append(results['home_team'][i])
elif results['home_score'][i] < results ['away_score'][i]:
winner.append(results['away_team'][i])
else:
winner.append('Draw')
results['winning_team'] = winner
#adding goal difference column
results['goal_difference'] = np.absolute(results['home_score'] - results['away_score'])
results.head()
运行结果如下:
然后,我们将处理一部分数据。
其中包括只有尼日利亚参加的比赛。这将有助于我们关注哪些国家的特色有趣,并随后扩展到参加世界杯的国家。
具体代码如下:
#lets work with a subset of the data one that includes games played by Nigeria in a Nigeria dataframe
df = results[(results['home_team'] == 'Nigeria') | (results['away_team'] == 'Nigeria')]
nigeria = df.iloc[:]
nigeria.head()


第一届世界杯是在1930年举办的。创建一个年份的专栏,选择1930年以后的所有比赛,具体代码如下:
#creating a column for year and the first world cup was held in 1930
year = []
for row in nigeria['date']:
year.append(int(row[:4]))
nigeria ['match_year']= year
nigeria_1930 = nigeria[nigeria.match_year >= 1930]
nigeria_1930.count()
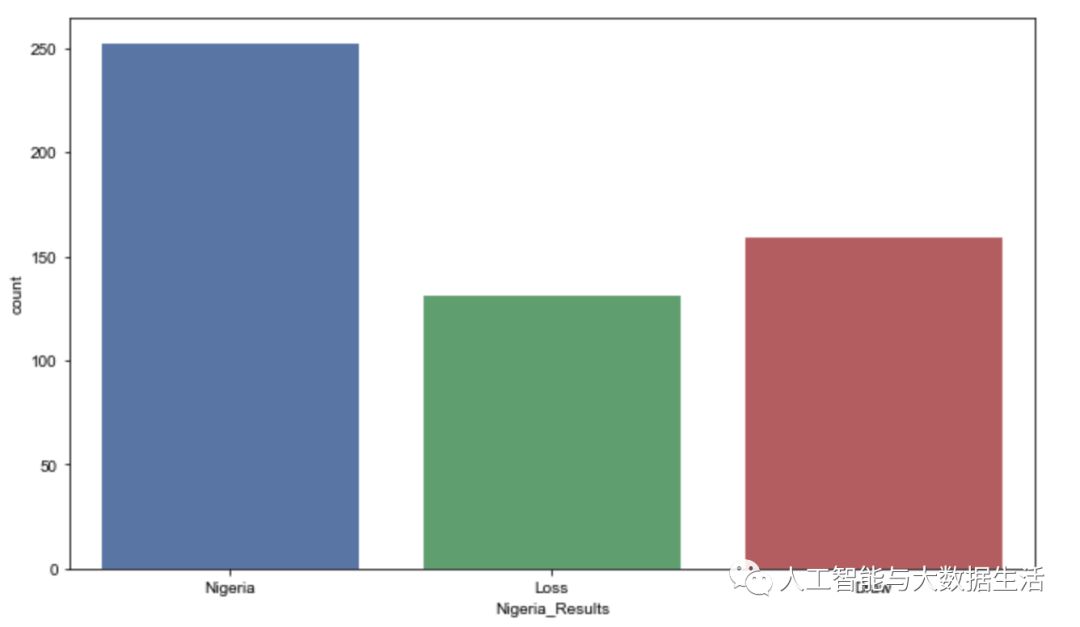
我们现在可以想象这些年来尼日利亚最常见的比赛结果。
具体如下:
#what is the common game outcome for nigeria visualisation
wins = []
for row in nigeria_1930['winning_team']:
if row != 'Nigeria' and row != 'Draw':
wins.append('Loss')
else:
wins.append(row)
winsdf= pd.DataFrame(wins, columns=[ 'Nigeria_Results'])
#plotting
fig, ax = plt.subplots(1)
fig.set_size_inches(10.7, 6.27)
sns.set(style='darkgrid')
sns.countplot(x='Nigeria_Results', data=winsdf)效果图如下:
 获得参加世界杯的每个国家的获胜率是一个有用的指标,我们可以用它来预测比赛中每场比赛的最可能结果。
获得参加世界杯的每个国家的获胜率是一个有用的指标,我们可以用它来预测比赛中每场比赛的最可能结果。
比赛场地无关紧要,缩小到参加世界杯的球队,与所有参与团队创建一个数据框,
具体代码如下
#narrowing to team patcipating in the world cup
worldcup_teams = ['Australia', ' Iran', 'Japan', 'Korea Republic',
'Saudi Arabia', 'Egypt', 'Morocco', 'Nigeria',
'Senegal', 'Tunisia', 'Costa Rica', 'Mexico',
'Panama', 'Argentina', 'Brazil', 'Colombia',
'Peru', 'Uruguay', 'Belgium', 'Croatia',
'Denmark', 'England', 'France', 'Germany',
'Iceland', 'Poland', 'Portugal', 'Russia',
'Serbia', 'Spain', 'Sweden', 'Switzerland']
df_teams_home = results[results['home_team'].isin(worldcup_teams)]
df_teams_away = results[results['away_team'].isin(worldcup_teams)]
df_teams = pd.concat((df_teams_home, df_teams_away))
df_teams.drop_duplicates()
df_teams.count()然后,我们会进一步过滤结果数据框,以显示从1930年起仅在今年世界杯上的球队以及丢弃重复。

在1930年之前创建年份栏和放弃游戏以及不会影响例如日期,主场比分,客场比赛,比赛,城市,国家,goal_difference和match_year等比赛结果的栏。具体代码如下:
#create an year column to drop games before 1930
year = []
for row in df_teams['date']:
year.append(int(row[:4]))
df_teams['match_year'] = year
df_teams_1930 = df_teams[df_teams.match_year >= 1930]
df_teams_1930.head()
具体结构如下:


修改“Y”(预测标签)以简化模型的处理。如果主队获胜,winner_team列将显示“2”,如果是平局则显示“1”,如果客队赢了,则显示“0”,具体代码如下:
#the prediction label: The winning_team column will show "2" if the home team has won, "1" if it was a tie, and "0" if the away team has won.
df_teams_1930 = df_teams_1930.reset_index(drop=True)
df_teams_1930.loc[df_teams_1930.winning_team == df_teams_1930.home_team,'winning_team']=2
df_teams_1930.loc[df_teams_1930.winning_team == 'Draw', 'winning_team']=1
df_teams_1930.loc[df_teams_1930.winning_team == df_teams_1930.away_team, 'winning_team']=0
df_teams_1930.head()
运行结果如下:
通过设置虚拟变量,将home_team和_team从分类变量转换为连续输入。使用熊猫,get_dummies()函数。
它取代类别列与他们的一个热(数字“1”和“0”)表示,使他们能够被装载到Scikit学习模式。
然后,我们将X和Y组分开,并将数据分成70%的训练和30%的测试。代码如下:
#convert home team and away team from categorical variables to continous inputs
# Get dummy variables
final = pd.get_dummies(df_teams_1930, prefix=['home_team', 'away_team'], columns=['home_team', 'away_team'])
# Separate X and y sets
X = final.drop(['winning_team'], axis=1)
y = final["winning_team"]
y = y.astype('int')
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)


看起来很棒。我们现在准备将其传递给我们的算法,代码如下
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
score = logreg.score(X_train, y_train)
score2 = logreg.score(X_test, y_test)
print("Training set accuracy: ", '%.3f'%(score))
print("Test set accuracy: ", '%.3f'%(score2))
我们的模型在训练集上的准确率为57%,在测试集上的准确率为55%。这看起来不太好,
但让我们继续前进。在这一点上,我们将创建一个数据框,我们将部署我们的模型。
我们将首先加载截至2018年4月的国际足联排名数据集和包含从这里获得的比赛小组赛阶段的小组赛阶段的数据集。
国际足联排名较高的球队将被视为比赛的“最爱”球员,因此,由于世界杯比赛中没有“主队”或“客队”球队,他们将被定位在“home_teams”栏目下。
然后,我们根据每个团队的排名位置将团队添加到新的预测数据集中。下一步将创建虚拟变量并部署机器学习模型。
现在你想知道我们会不会接受预测?这是太多的代码和谈话,你什么时候会向我们展示预测?紧紧抓住我们几乎在那里......
将模型部署到数据集。我们从将模型部署到组比赛开始。从小组赛开始,进行比较。具体代码和结果如下所示:
#group matches
predictions = logreg.predict(pred_set)
for i in range(fixtures.shape[0]):
print(backup_pred_set.iloc[i, 1] + " and " + backup_pred_set.iloc[i, 0])
if predictions[i] == 2:
print("Winner: " + backup_pred_set.iloc[i, 1])
elif predictions[i] == 1:
print("Draw")
elif predictions[i] == 0:
print("Winner: " + backup_pred_set.iloc[i, 0])
print('Probability of ' + backup_pred_set.iloc[i, 1] + ' winning: ', '%.3f'%(logreg.predict_proba(pred_set)[i][2]))
print('Probability of Draw: ', '%.3f'%(logreg.predict_proba(pred_set)[i][1]))
print('Probability of ' + backup_pred_set.iloc[i, 0] + ' winning: ', '%.3f'%(logreg.predict_proba(pred_set)[i][0]))
print("")
小组赛部分结果,请关注公众号 并 回复 世界杯 获得所有代码,然后运行查看所有结果。
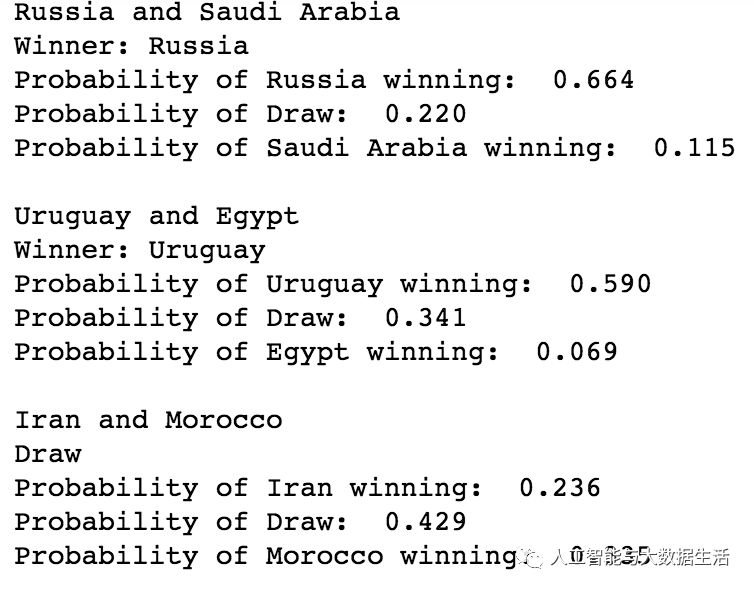
该模型还可以预测三人将在葡萄牙和西班牙之间安然下注,但西班牙队获胜的可能性很高。
我用这个网站模拟了小组赛的比赛。同时也预测在四分之一决赛之间:葡萄牙vs法国,巴西vs英格兰,西班牙vs阿根廷,德国vs比利时。

具体结果,请关注公众号 并 回复 世界杯 获得所有代码,然后运行查看所有结果。但是该模型,最后预测的大赛是 巴西和德国之间,具体代码 如下:
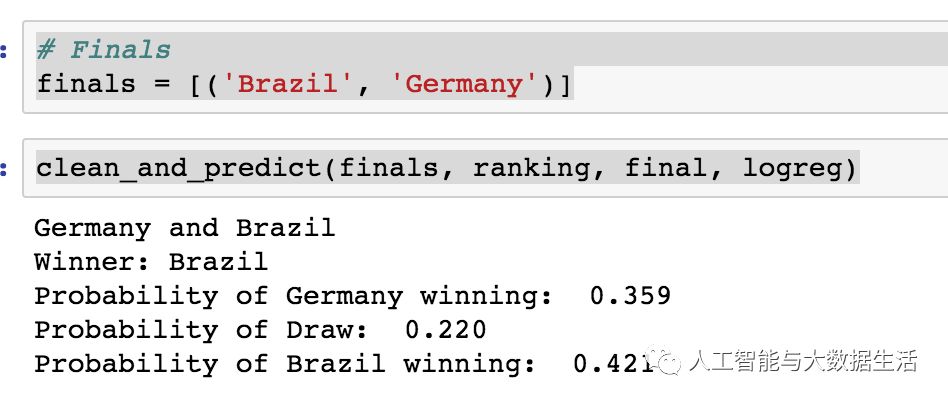
根据这个模型,巴西很可能赢得这个世界杯。但是 2018年世界杯的32支队伍,根据以往的世界杯比赛数据来看,预测前三强为 德国、阿根廷和巴西,其中德国队应该是夺冠的最大热门。

进一步研究/改进的领域
数据集; 为了改进数据集,您可以使用FIFA(游戏而不是组织)来评估每个团队成员的质量。
混淆矩阵对分析模型出错的游戏非常有用。
我们可以合作,也就是说,我们可以尝试将更多模型堆叠在一起以提高准确性。
结论
有很多事情可以做,以改善这项工作。现在让我们看看我们是否幸运。充分披露:我不是足球的巨大粉丝😀。所以预测你自己的风险。
完整代码,请关注公众号 并 回复 世界杯 获得。
本文是小编翻译整理。具体翻译来自 Gerald Muriuki博客:https://blog.goodaudience.com/predicting-fifa-world-cup-2018-using-machine-learning-dc07ad8dd576。
推荐小码哥新书!
小码哥新手《Python + Excel/Word/PPT一本通》正式上市了!书中详细介绍了零基础用Python实现办公自动化的各方面知识,提高职场办公效率,附赠PPT/源代码/重点教学视频讲解和作者VIP一对一指导。
内容介绍:《Python + Excel/Word/PPT 一本通》内容介绍
扫码购买
▼点击阅读原文,了解本书详情~
