
Transformer也能生成图像
Transformer 已经为多种自然语言任务带来了突飞猛进的进步,并且最近也已经开始向计算机视觉领域渗透,开始在一些之前由 CNN 主导的任务上暂露头角。近日,加州大学圣迭戈分校与 Google Research 的一项研究提出了使用视觉 Transformer 来训练 GAN。为了有效应用该方法,研究者还提出了多项改进技巧,使新方法在一些指标上可比肩前沿 CNN 模型。

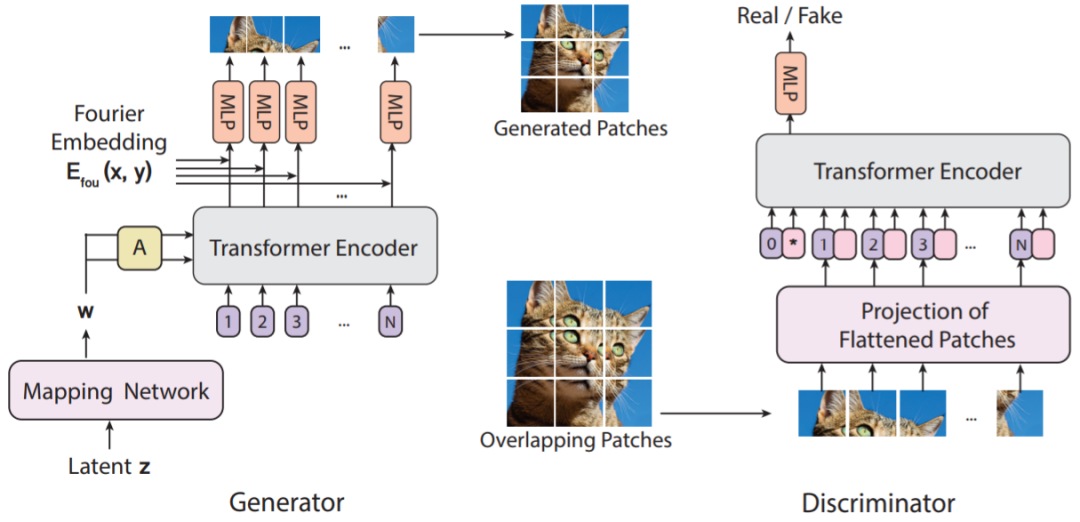
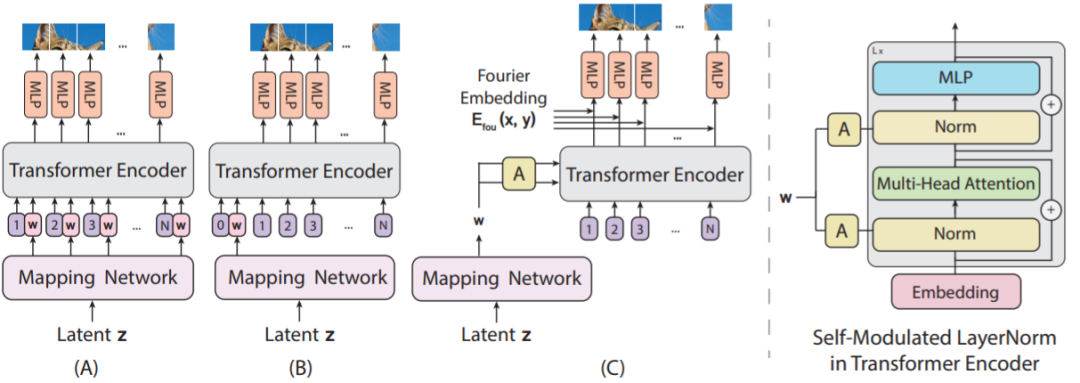
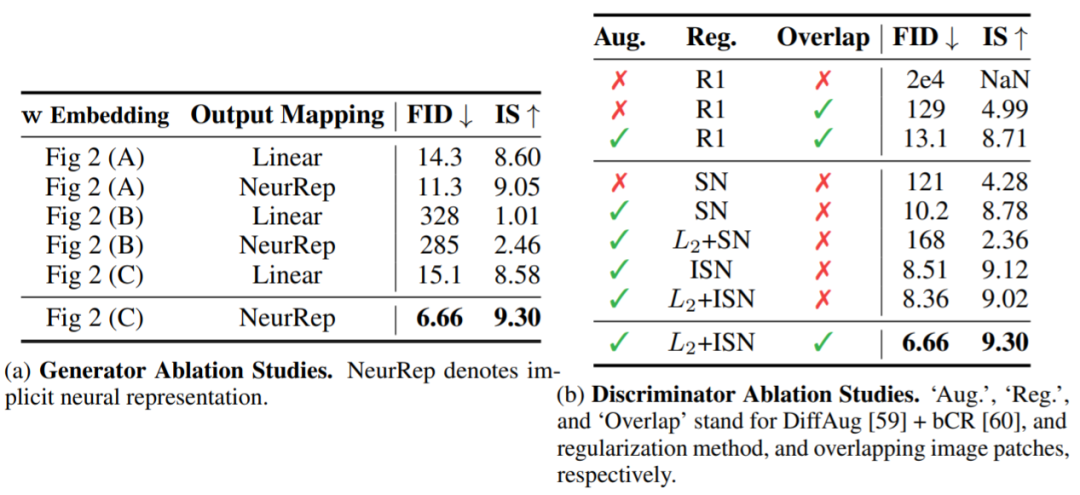
自调制型层范数(SLN)。新的做法不是将噪声向量 z 作为输入发送给 ViT,而是使用 z 来调制层范数运算。之所以称这样的操作为自调制,是因为该过程无需外部信息;
用于图块生成的隐式神经表征。为了学习从 patch 嵌入到 patch 像素值的连续映射,研究者使用了隐式神经表征。当结合傅里叶特征或正弦激活函数一起使用时,隐式表征可将所生成的样本空间约束到平滑变化的自然信号空间。研究发现,在使用基于 ViT 的生成器训练 GAN 时,隐式表征的作用尤其大。
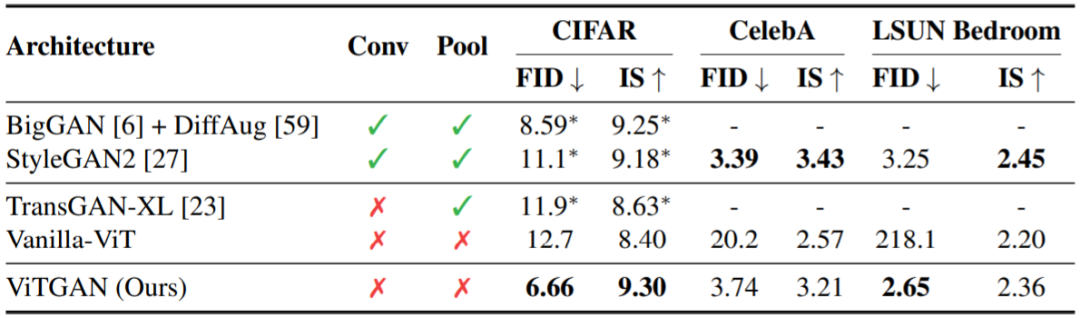

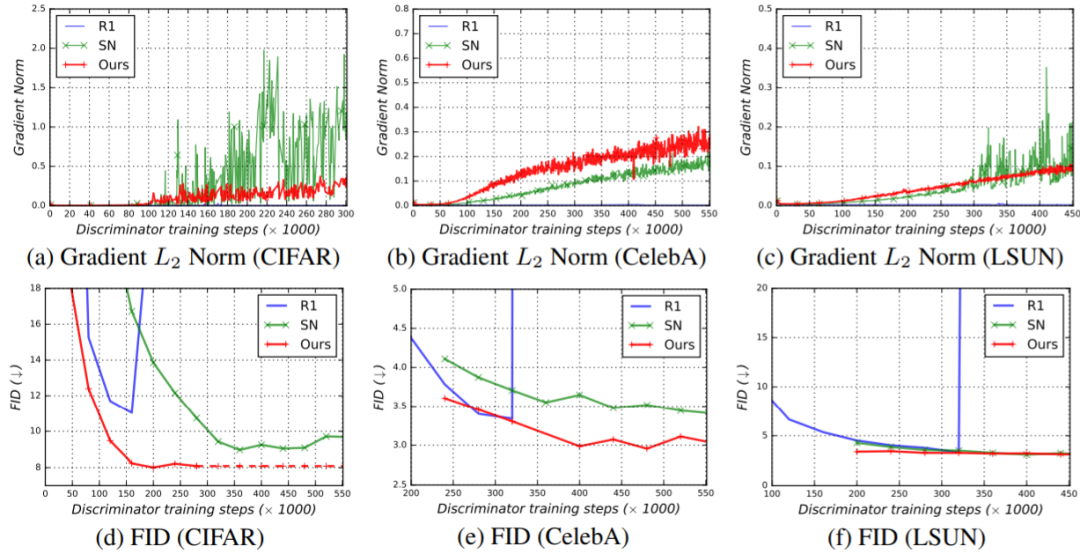
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论