点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

来源:公众号 机器之心 授权
Transformer 已经为多种自然语言任务带来了突飞猛进的进步,并且最近也已经开始向计算机视觉领域渗透,开始在一些之前由 CNN 主导的任务上暂露头角。近日,加州大学圣迭戈分校与 Google Research 的一项研究提出了使用视觉 Transformer 来训练 GAN。为了有效应用该方法,研究者还提出了多项改进技巧,使新方法在一些指标上可比肩前沿 CNN 模型。
卷积神经网络(CNN)在卷积(权重共享和局部连接)和池化(平移等变)方面的强大能力,让其已经成为了现今计算机视觉领域的主导技术。但最近,Transformer 架构已经开始在图像和视频识别任务上与 CNN 比肩。其中尤其值得一提的是视觉 Transformer(ViT)。这种技术会将图像作为 token 序列(类似于自然语言中的词)来解读。Dosovitskiy et al. 的研究表明,ViT 在 ImageNet 基准上能以更低的计算成本取得相当的分类准确度。不同于 CNN 中的局部连接性,ViT 依赖于在全局背景中考虑的表征,其中每个 patch 都必须与同一图像的所有 patch 都关联处理。ViT 及其变体尽管还处于早期阶段,但已有研究展现了其在建模非局部上下文依赖方面的优秀前景,并且也让人看到了其出色的效率和可扩展性。自 ViT 在前段时间诞生以来,其已经被用在了目标检测、视频识别、多任务预训练等多种不同任务中。近日,加州大学圣迭戈分校与 Google Research 的一项研究提出了使用视觉 Transformer 来训练 GAN。这篇论文的研究议题是:不使用卷积或池化,能否使用视觉 Transformer 来完成图像生成任务?更具体而言:能否使用 ViT 来训练生成对抗网络(GAN)并使之达到与已被广泛研究过的基于 CNN 的 GAN 相媲美的质量?
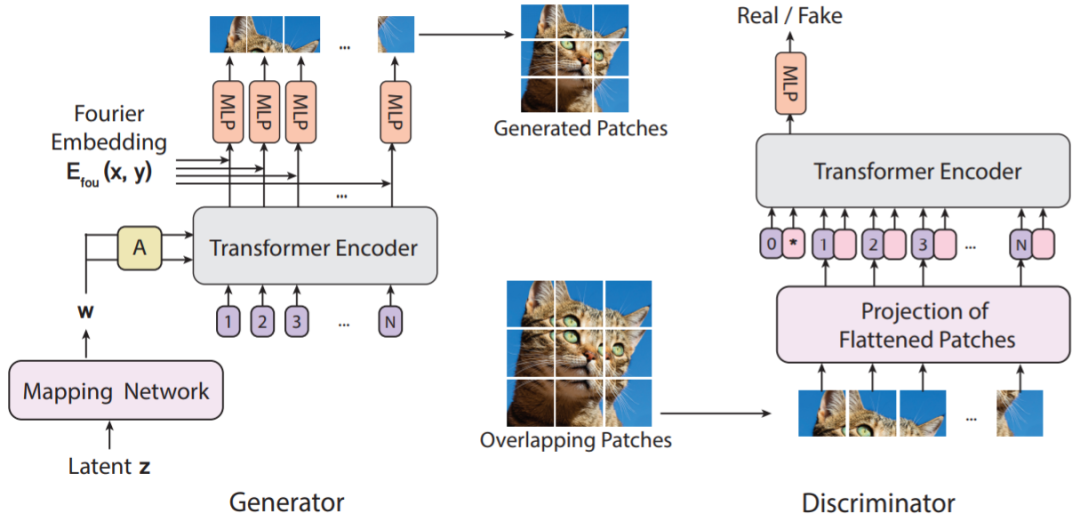
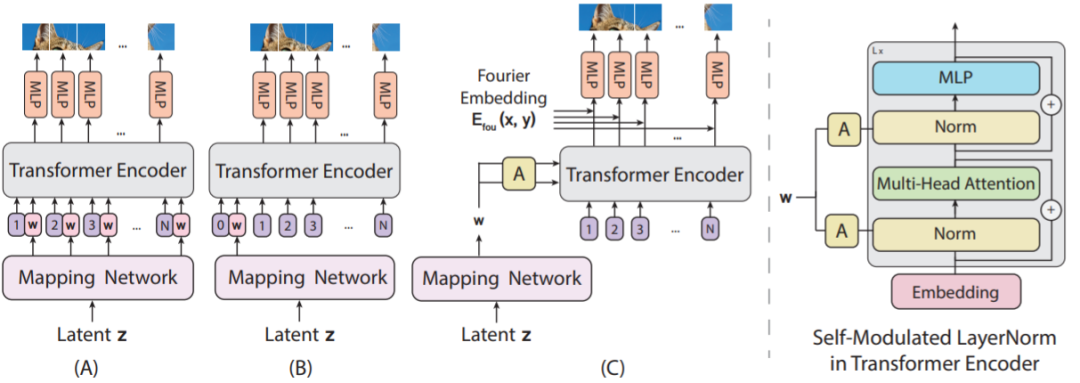
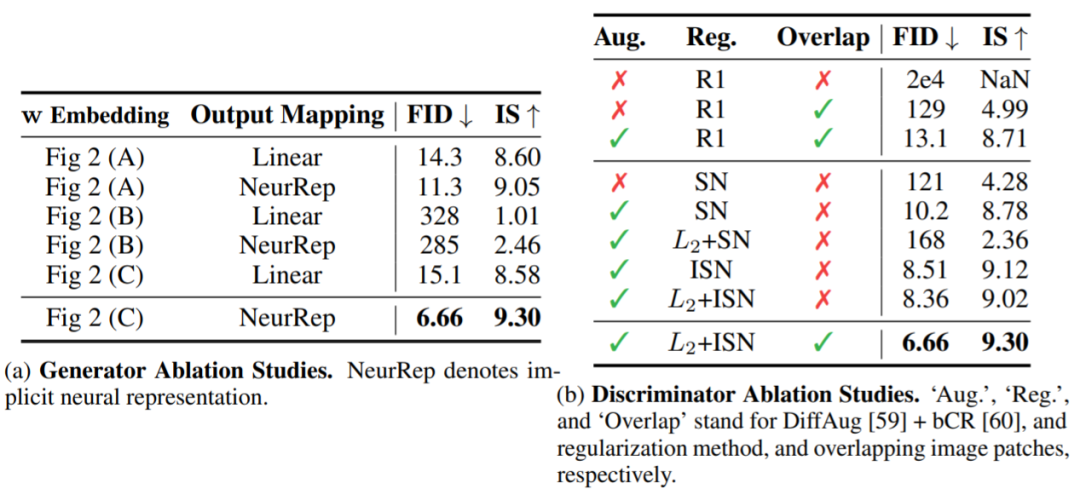
论文链接:https://arxiv.org/pdf/2107.04589.pdf为此,研究者遵照最本原的 ViT 设计,使用纯粹基本的 ViT(如图 2(A))训练了 GAN。其中的难点在于,GAN 的训练过程在与 ViT 耦合之后会变得非常不稳定,并且对抗训练常常会在判别器训练的后期受到高方差梯度(或尖峰梯度)的阻碍。此外,梯度惩罚、谱归一化等传统的正则化方法虽然能有效地用于基于 CNN 的 GAN 模型(如图 4),但这些正则化方法却无法解决上述不稳定问题。使用了适当的正则化方法后,基于 CNN 的 GAN 训练不稳定的情况并不常见,因此对基于 ViT 的 GAN 而言,这是一个独有的挑战。针对这些问题,为了实现训练动态的稳定以及促进基于 ViT 的 GAN 的收敛,这篇论文提出了多项必需的修改。在判别器中,研究者重新审视了自注意力的 Lipschitz 性质,在此基础上他们设计了一种加强了 Lipschitz 连续性的谱归一化。不同于难以应付不稳定情况的传统谱归一化方法,这些技术能非常有效地稳定基于 ViT 的判别器的训练动态。此外,为了验证新提出的技术的作用,研究者还执行了控制变量研究。对于基于 ViT 的生成器,研究者尝试了多种不同的架构设计并发现了对层归一化和输出映射层的两项关键性修改。实验表明,不管使用的判别器是基于 ViT 还是基于 CNN,基于修改版 ViT 的生成器都能更好地促进对抗训练。为了更具说服力,研究者在三个标准的图像合成基准上进行了实验。结果表明,新提出的模型 ViTGAN 极大优于之前的基于 Transformer 的 GAN 模型,并且在没有使用卷积和池化时也取得了与 StyleGAN2 等领先的基于 CNN 的 GAN 相媲美的表现。作者表示,新提出的 ViTGAN 算得上是在 GAN 中使用视觉 Transformer 的最早尝试之一,更重要的是,这项研究首次表明 Transformer 能在 CIFAR、CelebA 和 LSUN 卧室数据集等标准图像生成基准上超过当前最佳的卷积架构。图 1 展示了新提出的 ViTGAN 架构,其由一个 ViT 判别器和一个基于 ViT 的生成器构成。研究者发现,直接使用 ViT 作为判别器会让训练不稳定。为了稳定训练动态和促进收敛,研究者为生成器和判别器都引入了新技术:(1) ViT 判别器上的正则化和 (2) 新的生成器架构。图 1:新提出的 ViTGAN 框架示意图。生成器和判别器都是基于视觉 Transformer(ViT)设计的。判别器分数是从分类嵌入推导得到的(图中记为 *);生成器是基于 patch 嵌入逐个 patch 生成像素。增强 Transformer 判别器的 Lipschitz 性质。在 GAN 判别器中,Lipschitz 连续性发挥着重要的作用。人们最早注意到它的时候是将其用作近似 WGAN 中 Wasserstein 距离的一个条件,之后其又在使用 Wasserstein 损失之外的其它 GAN 设置中得到了确认。其中,尤其值得关注的是 ICML 2019 论文《Lipschitz generative adversarial nets》,该研究证明 Lipschitz 判别器能确保存在最优的判别函数以及唯一的纳什均衡。但是,ICML 2021 的一篇论文《The lipschitz constant of self-attention》表明标准点积自注意力层的 Lipschitz 常数可以是无界的,这就会破坏 ViT 中的 Lipschitz 连续性。为了加强 ViT 判别器的 Lipschitz 性质,研究者采用了上述论文中提出的 L2 注意力。如等式 7 所示,点积相似度被替换成了欧几里得距离,并且还关联了投影矩阵的权重,以用于自注意力中的查询和键(key)。这项改进能提升用于 GAN 判别器的 Transformer 的稳定性。经过改进的谱归一化。为了进一步强化 Lipschitz 连续性,研究者还在判别器训练中使用了谱归一化。标准谱归一化是使用幂迭代来估计每层神经网络的投影矩阵的谱范数,然后再使用估计得到的谱范数来除权重矩阵,这样所得到的投影矩阵的 Lipschitz 常量就等于 1。研究者发现,Transformer 模块对 Lipschitz 常数的大小很敏感,当使用了谱归一化时,训练速度会非常慢。类似地,研究者还发现当使用了基于 ViT 的判别器时,R1 梯度惩罚项会有损 GAN 训练。另有研究发现,如果 MLP 模块的 Lipschitz 常数较小,则可能导致 Transformer 的输出坍缩为秩为 1 的矩阵。为了解决这个问题,研究者提出增大投影矩阵的谱范数。他们发现,只需在初始化时将谱范数与每一层的归一化权重矩阵相乘,便足以解决这个问题。具体而言,谱归一化的更新规则如下,其中 σ 是计算权重矩阵的标准谱范:重叠图像块。由于 ViT 判别器具有过多的学习能力,因此容易过拟合。在这项研究中,判别器和生成器使用了同样的图像表征,其会根据一个预定义的网络 P×P 来将图像分割为由非重叠 patch 组成的序列。如果不经过精心设计,这些任意的网络划分可能会促使判别器记住局部线索,从而无法为生成器提供有意义的损失。为了解决这个问题,研究者采用了一种简单技巧,即让 patch 之间有所重叠。对于 patch 的每个边缘,都将其扩展 o 个像素,使有效 patch 尺寸变为 (P+2o)×(P+2o)。这样得到的序列长度与原来一样,但对预定义网格的敏感度更低。这也有可能让 Transformer 更好地了解当前 patch 的邻近 patch 是哪些,由此更好地理解局部特性。基于 ViT 架构设计生成器并非易事,其中一大难题是将 ViT 的功能从预测一组类别标签转向在一个空间区域生成像素。图 2:生成器架构。左图是研究者研究过的三种生成器架构:(A) 为每个位置嵌入添加中间隐藏嵌入 w,(B) 将 w 预置到序列上,(C) 使用由 w 学习到的仿射变换(图中的 A)计算出的自调制型层范数(SLN/self-modulated layernorm)替换归一化。右图是用在 Transformer 模块中的自调制运算的细节。研究者先研究了多种生成器架构,发现它们都比不上基于 CNN 的生成器。于是他们遵循 ViT 的设计原理提出了一种全新的生成器。图 2(c) 展示了这种 ViTGAN 生成器,其包含两大组件:Transformer 模块和输出映射层。为了促进训练过程,研究者为新提出的生成器做出了两项改进:自调制型层范数(SLN)。新的做法不是将噪声向量 z 作为输入发送给 ViT,而是使用 z 来调制层范数运算。之所以称这样的操作为自调制,是因为该过程无需外部信息;
用于图块生成的隐式神经表征。为了学习从 patch 嵌入到 patch 像素值的连续映射,研究者使用了隐式神经表征。当结合傅里叶特征或正弦激活函数一起使用时,隐式表征可将所生成的样本空间约束到平滑变化的自然信号空间。研究发现,在使用基于 ViT 的生成器训练 GAN 时,隐式表征的作用尤其大。
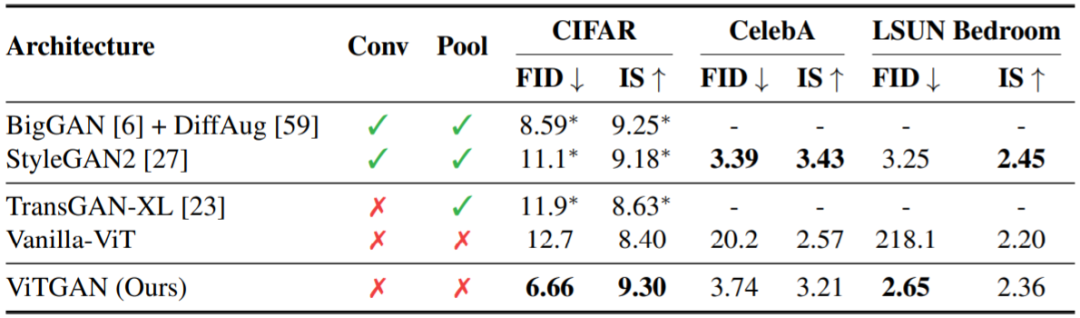
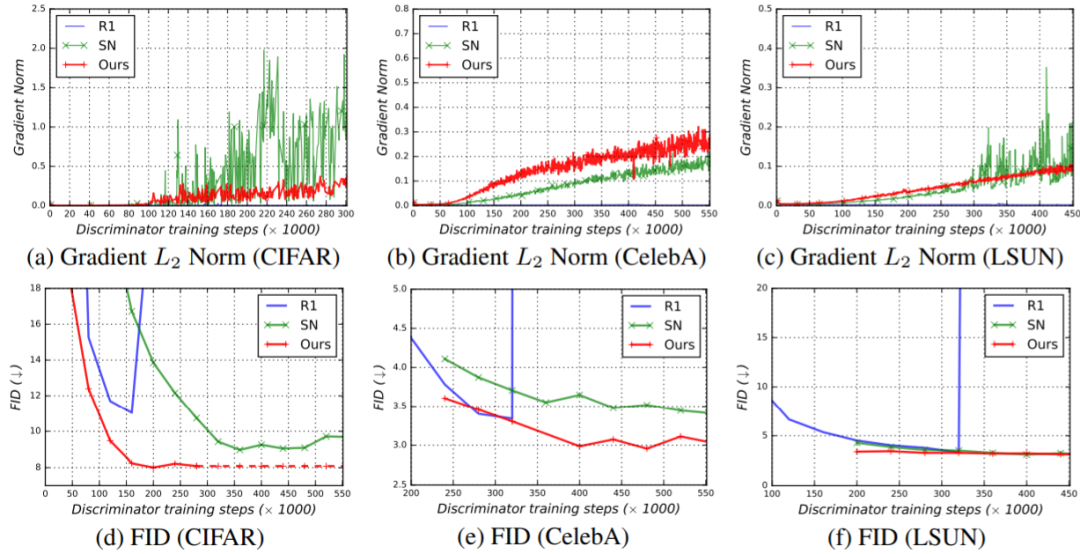
需要指出,由于生成器和判别器的图像网格不同,因此序列长度也不一样。进一步的研究发现,当需要将模型扩展用于更高分辨率的图像时,只需增大判别器的序列长度或特征维度就足够了。表 1:几种代表性 GAN 架构在无条件图像生成基准的结果比较。Conv 和 Pool 各自代表卷积和池化。↓ 表示越低越好;↑ 表示越高越好。表 1 给出了在图像合成的三个标准基准上的主要结果。本论文提出的新方法能与以下基准架构比肩。TransGAN 是目前唯一完全不使用卷积的 GAN,其完全基于 Transformer 构建。这里比较的是其最佳的变体版本 TransGAN-XL。Vanilla-ViT 是一种基于 ViT 的 GAN,其使用了图 2(A) 的生成器和纯净版 ViT 判别器,但未使用本论文提出的改进技术。表 3a 中分别比较了图 2(B) 所示的生成器架构。此外,BigGAN 和 StyleGAN2 作为基于 CNN 的 GAN 的最佳模型也被纳入了比较。图 3:定性比较。在 CIFAR-10 32 × 32、CelebA 64 × 64 和 LSUN Bedroom 64 × 64 数据集上,ViTGAN 与 StyleGAN2、Transformer 最佳基准、纯净版生成器和判别器的 ViT 的结果比较。图 4:(a-c) ViT 判别器的梯度幅度(在所有参数上的 L2 范数),(d-f) FID 分数(越低越好)随训练迭代的变化情况。可以看到,新提出方法的表现与使用 R1 惩罚项和谱范数的两个纯净版 ViT 判别器基准相当。其余架构对所有方法来说都一样。可见新方法能克服梯度幅度的尖峰并实现显著更低的 FID(在 CIFAR 和 CelebA 上)或相近的 FID(在 LSUN 上)。表 3:在 CIFAR-10 数据集上对 ViTGAN 执行的控制变量研究。左图:对生成器架构的控制变量研究。右图:对判别器架构的控制变量研究。
推荐阅读
“拍一拍” 能撤回了 !!!
5款Chrome插件,第1款绝对良心!
为开发色情游戏,这家公司赴日寻找AV女优拍摄,期望暴力赚钱结果...
拼多多终于酿成惨剧
华为阿里下班时间曝光:所有的光鲜,都有加班的味道
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!