
港中文博士提出首个基于Transformer的条件GAN:成像质量仍不如CNN

新智元报道
新智元报道
编辑:LRS
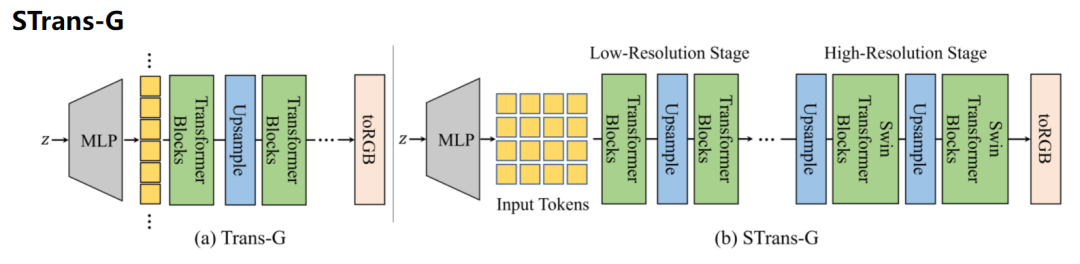
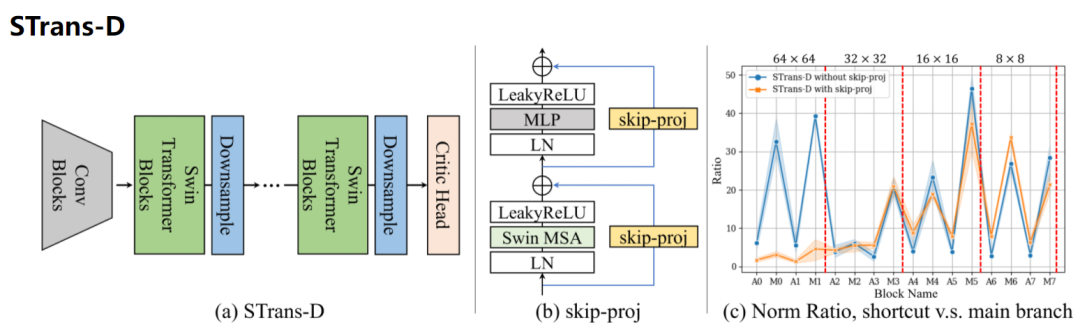
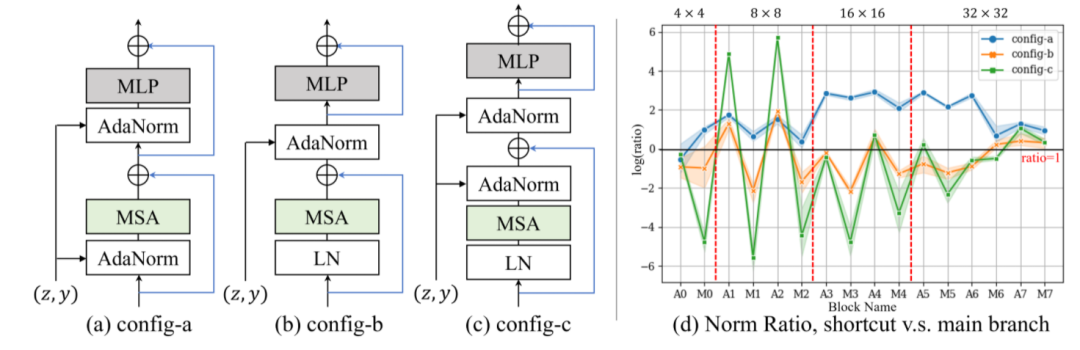
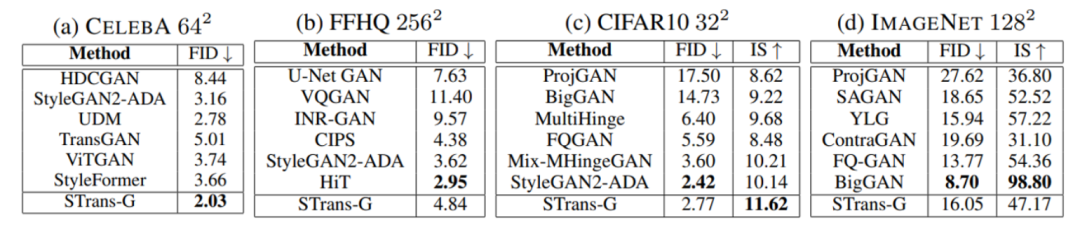
【新智元导读】Transformer在图像分类任务上经过充分训练已经足以完全超越CNN模型,但GAN仍然是Transformer无法踏足的领域。最近港中文博士提出首个基于Transformer的条件GAN模型STransGAN,缓解了Transformer的部分问题,但成像质量仍不如CNN。




参考资料:
https://arxiv.org/abs/2110.13107

评论