
稀疏纹理也能匹配?一种基于Transformers的图像特征匹配器|CVPR2021
极市平台
共 1806字,需浏览 4分钟
·
2021-04-12 22:08

极市导读
本文提出了一种新颖的用于局部图像特征匹配的方法,使用Transformers中的自我和交叉注意力层来获取两个图像的特征描述符,能够在低纹理区域产生密集匹配。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
“
本文提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,本文提出首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。与使用cost volume搜索对应关系的稠密匹配方法相比,本文使用了Transformers中的自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。Transformers提供的全局感受野使本文的方法能够在低纹理区域产生密集匹配(通常情况下在低纹理区域,特征检测器通常难以产生可重复的特征点)。在室内和室外数据集上进行的实验表明,LoFTR在很大程度上优于现有技术。 ”

框架
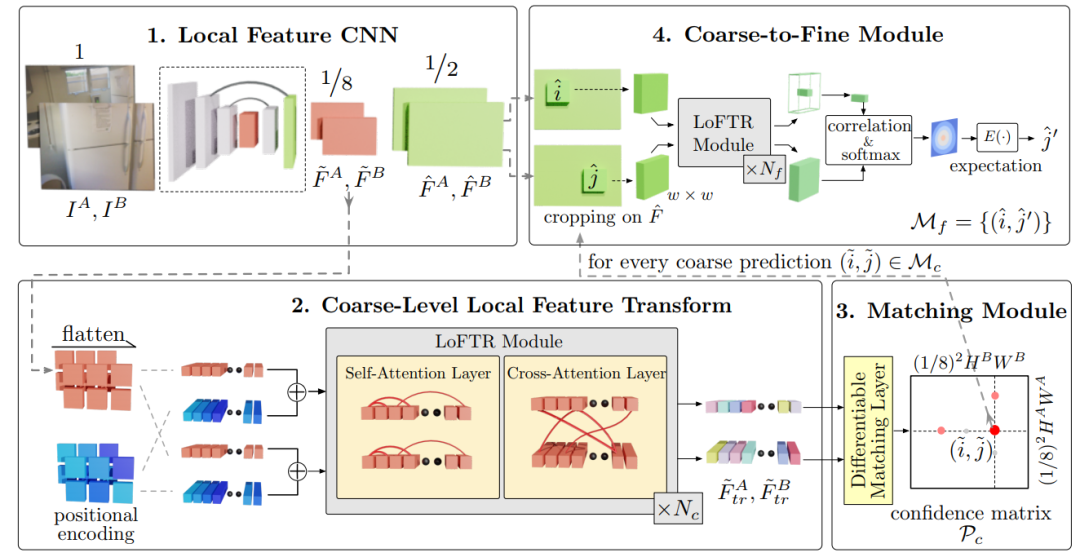
局部特征提取网络从图像以及中提取粗略特征图 和,以及精细的特征图和 。 将粗略特征图展平为一维向量,并添加位置编码;然后,将其喂给Local Feature TRansformer (LoFTR) 模块进行处理,得到个self-attention 和 cross-attention层。 可微分匹配层用于匹配上述变换后的特征,最终得到置信矩阵。根据置信度阈值和相互邻近标准选择匹配项,得到粗略的匹配预测。 对于每个选定的粗略预测,我们会从精细特征图中裁剪出具有大小为的局部窗口。粗匹配将在此局部窗口内进行细化为并达到亚像素匹配级别,作为最终的匹配预测。
实验
1. 弱纹理匹配效果
2. 与SuperGlue对比

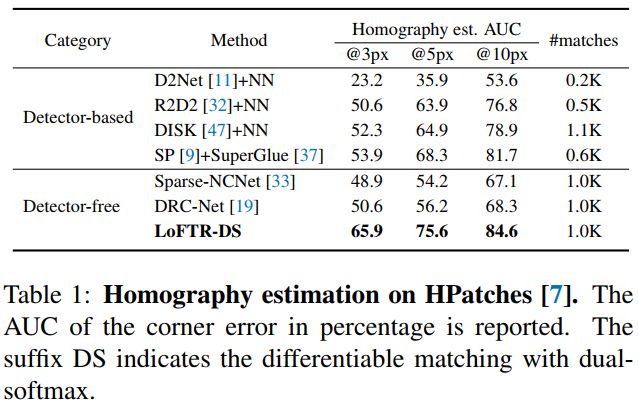
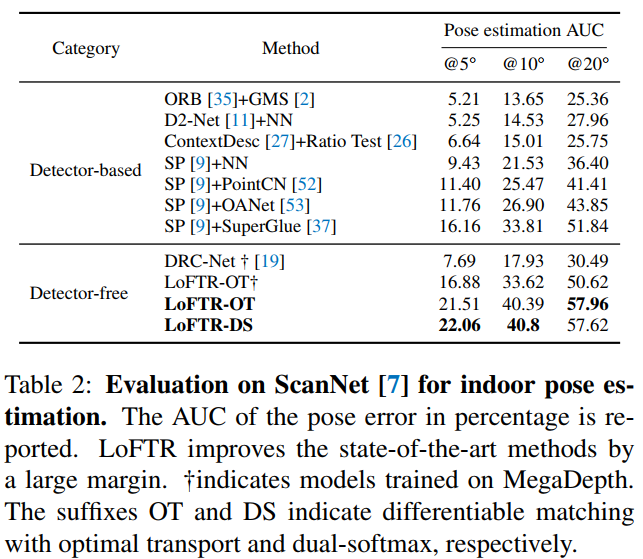
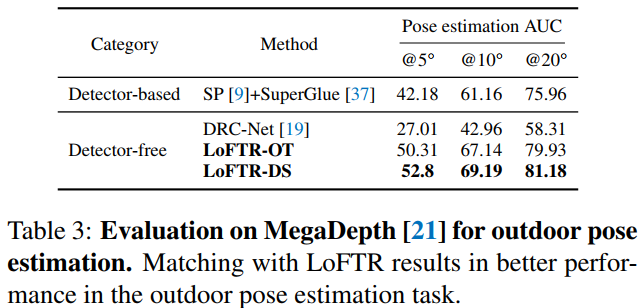
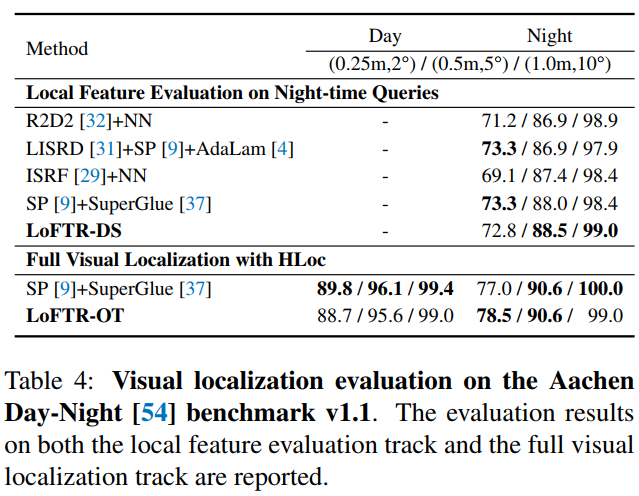
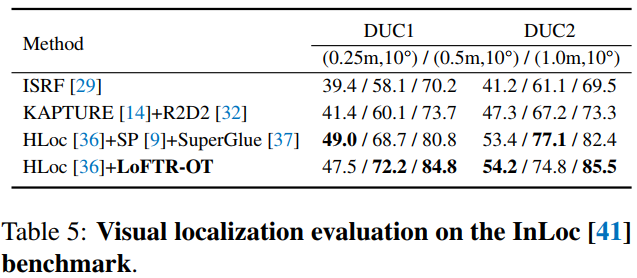
3. 定量比较
4. 可视化

总结
推荐阅读
2021-04-10
2021-04-06


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论