
AI | 聊聊决策树模型
目前决策树领域,已由原本单一的决策树模型演变成了级联学习树、随机森林模型的天下。
主要使用的就是Boosting和Bagging的思想。
Boosting和Bagging方法本质上都是组合学习,增强了树模型的准确率和鲁棒性
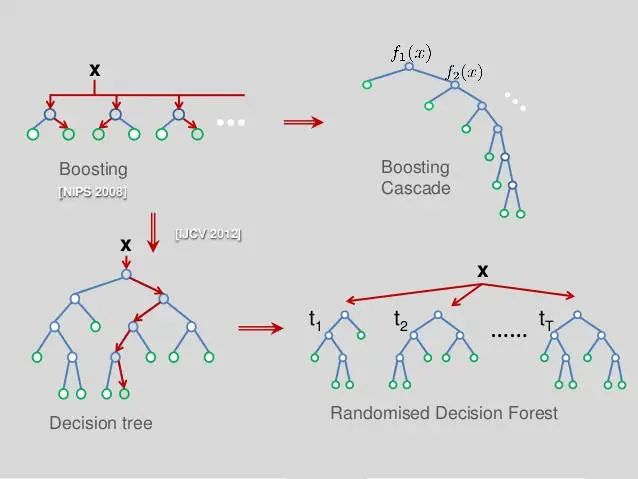
如上图所示:
Boosting侧重于纵向组合,代表模型为Xgboost
Bagging侧重于横向组合,代表模型为Random Forest
姑且我们就叫这些树模型统一为集成决策树模型吧
但是不管树模型如何组合,它的本质没有变,最基础的单元还是cart决策树
(你也可以说还有C4.5等,不过我觉得这不是重点,它们已经不是最优的基础单元,该退出历史舞台了)
相比深度学习算法
实现相对简单,效率更高,训练速度快,训练周期短,能更充分的利用机器资源
为什么说决策树模型的效率要高于神经网络模型?
如上图所示,就是一个典型的深度学习模型
1.从节点的计算量:
神经网络模型中全连接层节点的数量都是预估的
而决策树模型的节点则是根据信息熵或者基尼系数生成的,所以在计算规模上决策树模型就会明显小于神经网络模型
2.从训练原理上:
神经网络模型首先会将输入的数据进行一次激活函数的洗礼,然后再不断调整各节点的权重(也即学习率),通过多次计算输出的残差得到梯度反过来去影响节点的权重,这种节点整体权重的变化,相比决策树模型计算代价也高了n个数量级
所以,神经网络模型所需要的计算资源相比决策树来说就非常大了
相比其他传统机器学习算法
再来看看另一个引人注目的机器学习算法:支持向量机 SVM
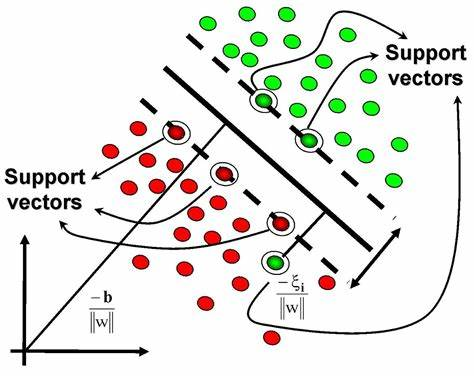
相比SVM,决策树模型的普适性更强,为什么?
因为SVM更侧重于对可分割数据的分割超平面的寻找和确定,现实中各种数据混杂噪音,是否恰好就有这样的超平面还两说,如果没有这样的超平面,支持向量点的寻找就变得异常困难,尤其是数据量变大的情况下,支持向量机的计算大概率会走向崩溃
小结
我们不妨做这样的假设对比:
如果把所有机器学习模型看作是核机器
那么集成决策树模型核函数可以用数学公式简化为:
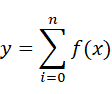
神经网络模型核函数可以简化为:
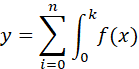
其他传统机器学习模型的核函数可以简化为:
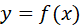
所以,这样可以一目了然的发现,集成决策树模型相比神经网络计算规模小,效率高,相比其他传统机器学习模型,模型复杂度又恰到好处,模型的表达能力强于一般模型
聊了这么多决策树模型的优势,我们再来看看决策树模型有哪些弊端?
决策树的规模预判
我们在使用XGBoost设计和训练一个集成决策树模型时,通常会对下列参数给出一个经验数值:
num_parallel_tree
num_boost_round
max_depth
但其实我们心里也没谱,不知道以上参数是否真的恰当,只能使用GridSearch等参数搜索工具逐步定位到最优参数范围
以上参数代表的含义不难理解:并行树的数量、boost次数、树最大深度
决策树的训练过程
我们知道决策树在进行节点分裂前时,会遍历训练集计算一个最优分裂点,这就要求决策树模型必须遍历完所有训练集,尽管这个操作可以不必完全在内存中完成(例如XGBoost的大规模训练解决方案),但是当面对日益增长的海量数据时,这种必须遍历完所有数据的缺陷也彰显出来
同时,我们也会清楚的了解,目前的决策树的最优权重都是基于目前的训练集的,一旦目标数据集发生了变化,这样的树模型就不再适用(想想是不是距离智能还很遥远?)
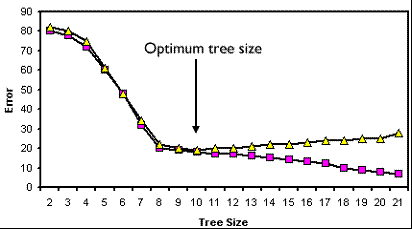
决策树的迁移学习
我们知道神经网络是具备迁移学习能力的,而决策树模型则不具备这些优点,单独将决策树的某些层拿出来,硬塞到一个新的数据集下,非但起不到加速训练的效果,反而破坏了模型的整体性,导致模型效果变差,所以决策树模型几乎无法进行迁移,只能集成学习
当然,对于以上问题,业界的AI专家们也没有闲着,想尽一切办法去让模型变得更智能和强大
决策树的规模预判问题
首先我们来看第一个问题,决策树规模的预判
我们在做决策树模型的设计时,往往会面临参数初始化的问题,很多人往往凭经验给出一组数值后,再反复尝试对比各参数从而找到一组合适的数值。
但该组参数是否是最优的也无从验证,只能是通过对照比较得到效果是已知最好的
目前有两种策略解决该问题:
1.将决策树看作组合优化问题,使用SAT求解器求解
这里有一篇2020年的代表论文:Efficient Inference of Optimal Decision Trees
论文地址:http://florent.avellaneda.free.fr/dl/AAAI20.pdf
该论文的主要思想在于:分割训练集,并简化决策树的分层问题,使得求解的规模变小,能够应对更大规模的数据集
分而治之的思想在运筹问题求解中简直是万金油,因此该论文发表在了AAAI上
笔者也对其作了复现,论文中的开源代码地址:
https://github.com/FlorentAvellaneda/InferDT
笔者复现的版本(支持CentOS7):
https://github.com/showkeyjar/InferDT
结果发现,在处理1-4k个数量级的数据样本时,InferDT还能游刃有余
一旦数据量超过了5k,InferDT运行的开始变得吃力,最终直接导致崩溃
这也是我们发现InferDT的示例中并没有超过1w数据量的样本
所以该论文方法虽然是一种显著的进步,但还不能应用到实际场景中
2.使用分支定界法搜索,然后缓存搜索结果
同样有一代表论文:Learning Optimal Decision Trees Using Caching Branch-and-Bound Search
论文地址:
https://dial.uclouvain.be/pr/boreal/fr/object/boreal%3A223390/datastream/PDF_01/view
该论文的主要思想在于:将复杂难以求解的组合优化问题分解为分段(分支定界)的组合优化问题,并缓存了计算结果,避免重复的从头计算,加快计算速度
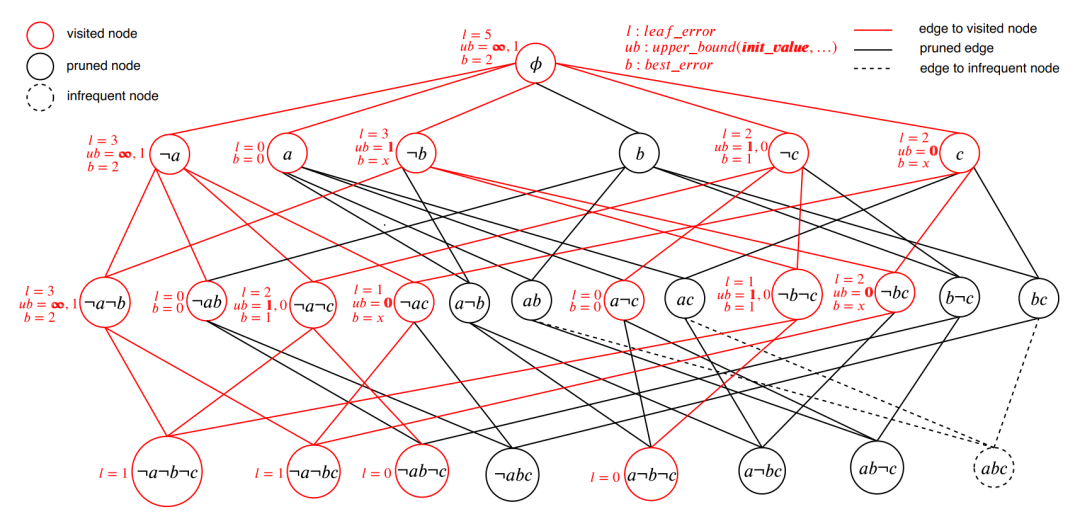
并由此设计出DL8.5算法,并兼容了sklearn
本质上也是一种分而治之的思想,和方法1有异曲同工之妙
如果大家有兴趣,也可以仔细研究研究这两篇论文
决策树的训练问题
目前业界大神们一直在想办法克服决策树训练过程中的一些缺陷
神经网络的解决方案:
这其中最优代表性的作品,就属2019年诞生的 tabnet :
https://github.com/dreamquark-ai/tabnet
论文地址:https://arxiv.org/pdf/1908.07442v5
tabnet号称自己是 xgboost + 神经网络的组合体,即具备神经网络反向传播的特点,又具备了集成决策树的高效和准确
那么tabnet如何解决决策树训练时必须遍历整个训练集的问题呢?
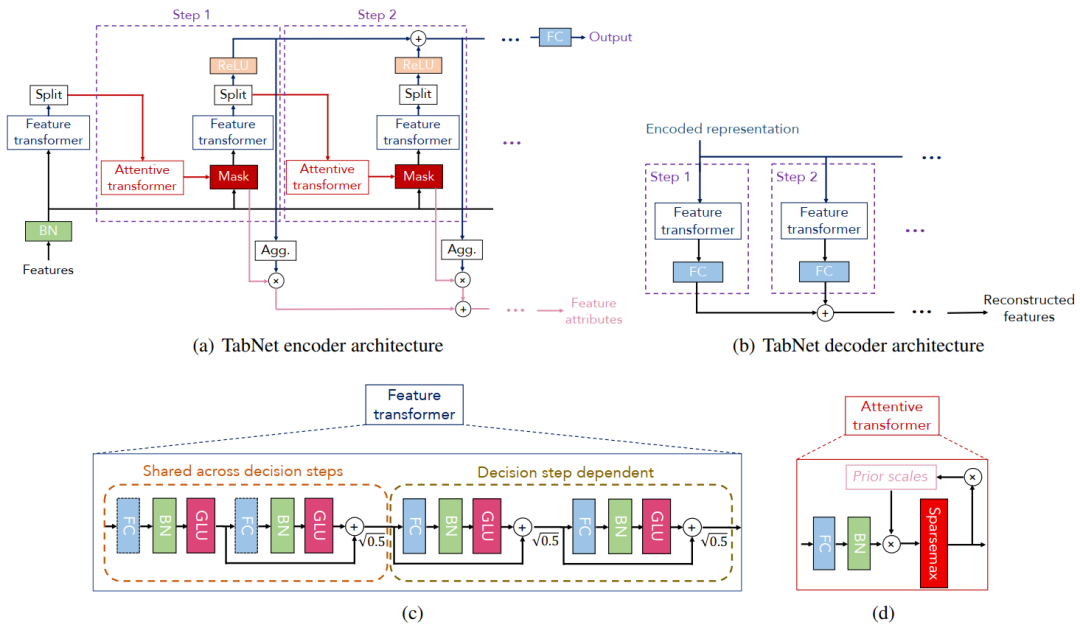
看到上图中tabnet的网络结构,是不是感觉和LSTM很类似?
我认为实际上可以把tabnet看作一种LSTM的变体,也使用到了transformer单元,而transformer技术也是2020年度最热门的一种深度学习技术,本质上是对输入数据的“主成分”自动分析和提取的过程
所以tabnet试图通过神经网络模拟决策树寻找分裂点的过程,从而让神经网络具备较好的可解释性
另外还有一个笔者注意到的项目QuantumForest:
https://github.com/closest-git/QuantumForest
论文地址:https://arxiv.org/pdf/2010.02921v1
QuantumForest针对决策树训练过程中信息熵和基尼系数的计算进行了改造,改变了一种思维方式,使用神经网络使得树模型具有了可微性(differentiability)
笔者理解是决策树的输出结果是离散的,不具备可微性,通过神经网络将树模型分裂点的信息熵变更为量子状态,使得决策树具备了连续可微的条件
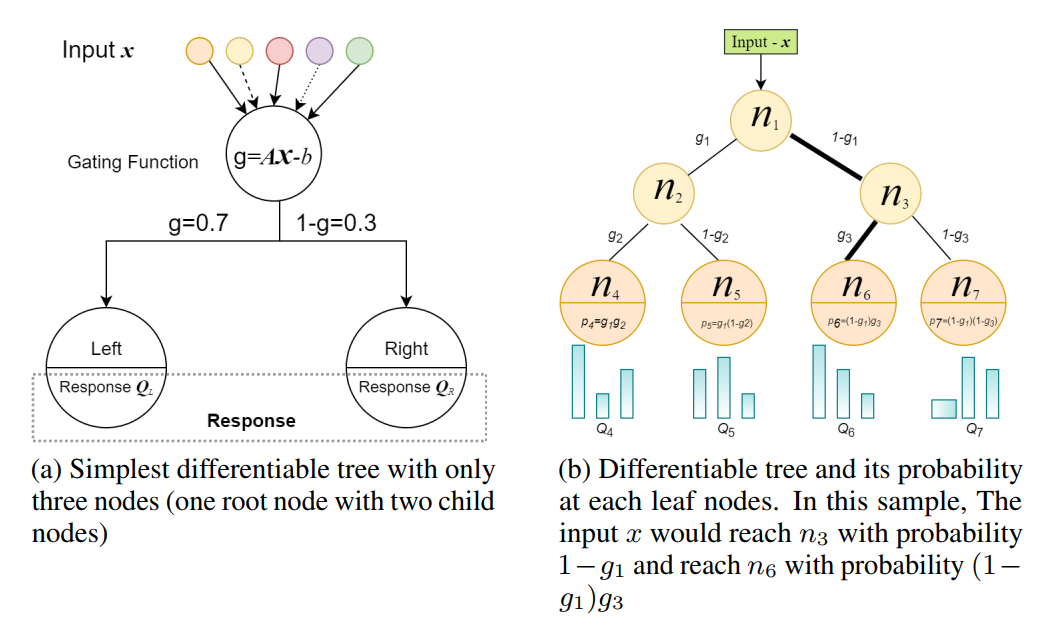
如图所示,传统的决策树模型在分裂节点时,得到的是一个确定的信息增益,而在QF里得到则
是一个浮点数(量子态概率)
QF项目的思想还是挺不错的,不过作者好像很懒,开源出来的作品工业化程度并不高,需要自己去解决易用性问题
决策树的迁移问题
也有大神在决策树的迁移领域放大招:
有对应的开源项目:https://github.com/atiqm/Transfer_DT
不过竟然没人关注,貌似没搞起来,有兴趣的同学也可以研究下,不妨也给笔者分享一下你的奇思妙想,期待你的创意
总之决策树模型领域是一个正在茁壮成长而又活力四射的领域,不断有人在为其发展添砖加瓦,而决策树+集成学习+神经网络正逐渐向我们走来,相信未来的决策树算法会更加强大而高效。真正的可解释性人工智能也会不断突破现有的技术障碍和缺陷,变得更加完美。希望我们能共同挖掘和分享出决策树的无穷魅力,谢谢阅读!
---------------------------End---------------------------
10000+人已加入矩阵司南
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
非常感谢对我们的支持! 