一、Producer 的网络模型
我们前面几篇有说 Producer 发送流程的源码分析,但那个是大的轮廓,涉及到发送很多相关的内容,比如:
获取 topic 的 metadata 信息
key 和 value 的序列化
获取该 record 要发送到的 partition
向 RecordAccmulator 中追加 record 数据
唤醒 sender 线程发送 RecordBatch
那这篇老周主要来说下 Producer 的网络模型,这里直接给出 Producer 的网络模型图,如下:
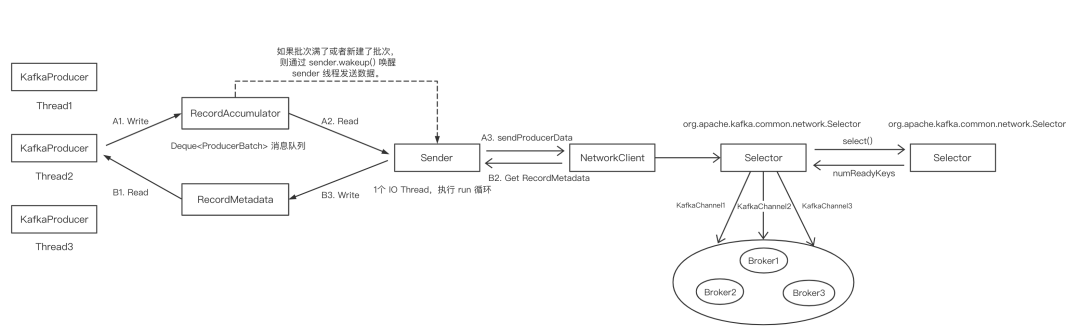
从图中可以看出,KafkaProducer 相当于客户端,与 Sender 调用层交互,Sender 调用 NetworkClient,NetworkClient 调用 Selector,而 Selector 底层封装了 Java NIO 的相关接口。心中有了 Producer 的网络模型大致轮廓后,我们接下来就可以来分析 Producer 的网络模型。
二、Producer 与 Broker 的交互流程
我们在业务代码通过生产者 producer 调用 send 方法来发送消息,不难发现都是通过走 Producer 的实现类 KafkaProducer 的 send 方法:
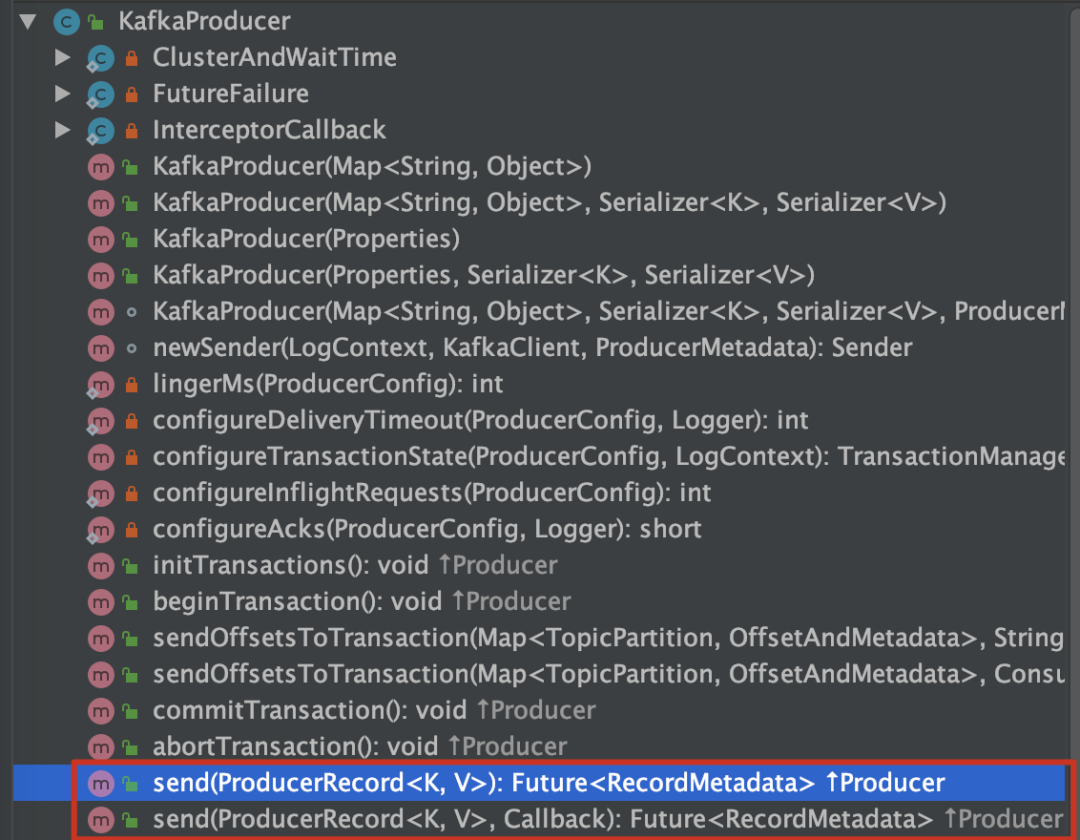
2.1 org.apache.kafka.clients.producer.KafkaProducer#doSend
上面的两个 send 方法最终会走到 doSend 方法里来:
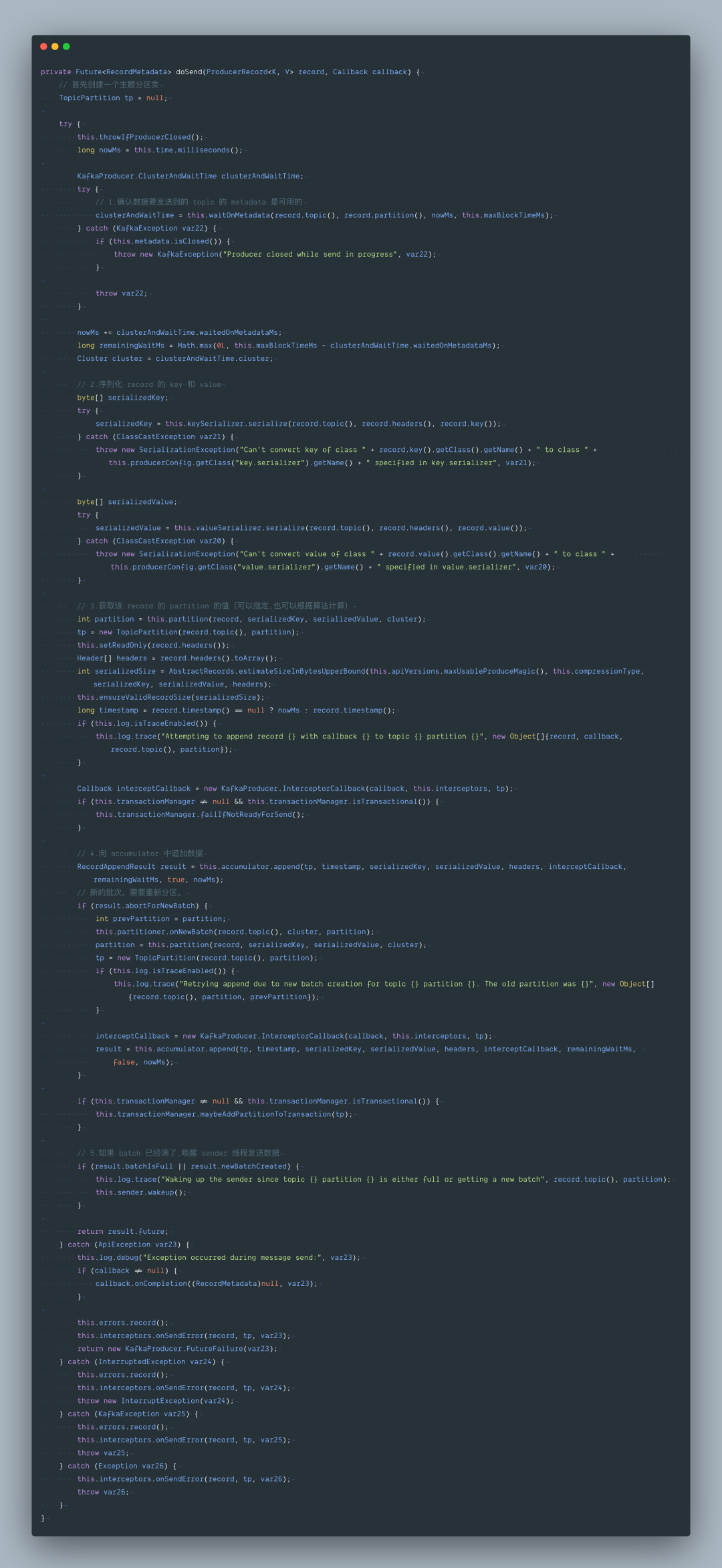
这块的源码老周在前两篇的 Producer 源码解析那一篇分析了的哈,这里主要说下与 Broker 通信的交互分析。主要有两点:
主要看下 sender.wakeup() 方法,主要作用就是将 Sender 线程从阻塞中唤醒。
2.2 org.apache.kafka.clients.producer.internals.Sender#wakeup
/**
* Wake up the selector associated with this send thread
*/
public void wakeup() {
this.client.wakeup();
}
/**
* Interrupt the client if it is blocked waiting on I/O.
*/
@Override
public void wakeup() {
this.selector.wakeup();
}
/**
* Interrupt the nioSelector if it is blocked waiting to do I/O.
*/
@Override
public void wakeup() {
this.nioSelector.wakeup();
}
不难发现,调用链是:
Sender -> NetworkClient -> Selector(Kafka 封装的)-> Selector(java.nio.channels.Selector Java NIO)
wakeup() 的主要作用就是唤醒阻塞在 select()/select(long) 上的线程,为什么要唤醒?因为注册了新的 channel 或者事件。
再回到 Kafka 这里,KafkaProducer 中 dosend() 方法调用 sender.wakeup() 方法作用就很明显了。作用就是:当有新的 RecordBatch 创建后,旧的 RecordBatch 就可以发送了,如果线程阻塞在 select() 方法中,就将其唤醒,Sender 重新开始运行 run() 方法,在这个方法中,旧的 RecordBatch 将会被选中,进而可以及时将这些请求发送出去。
2.3 org.apache.kafka.clients.producer.internals.Sender#run
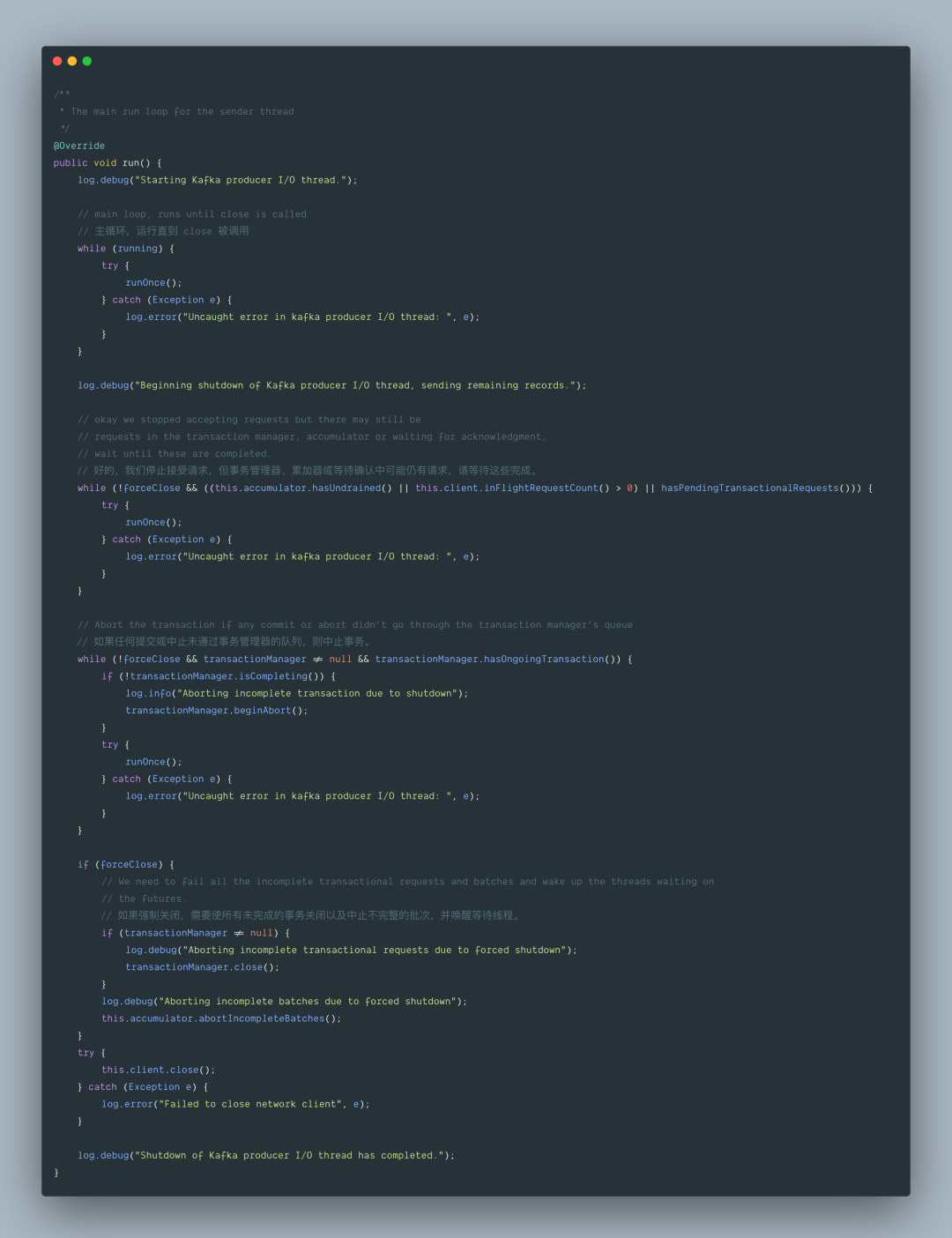
跟到 runOnce 方法里去:
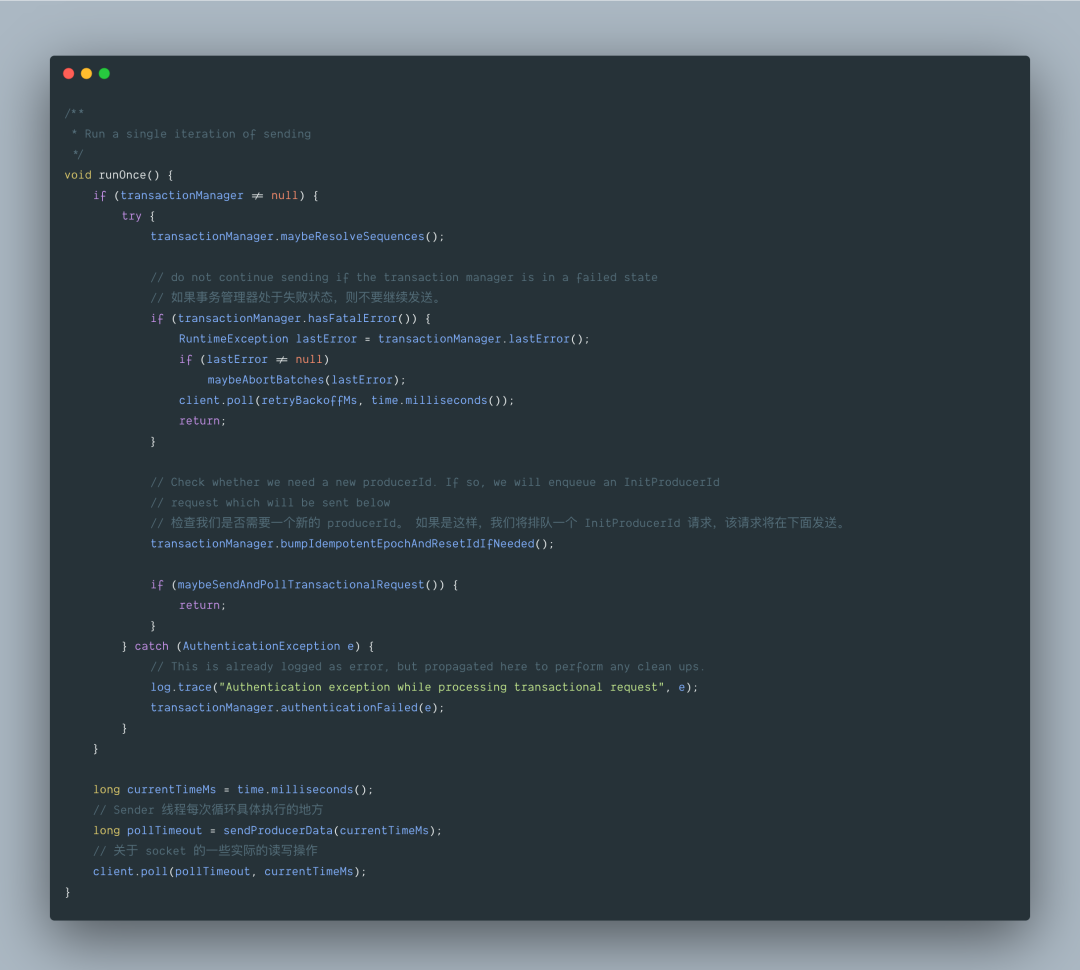
继续跟,核心是 Sender 线程每次循环具体执行的地方,即 sendProducerData() 方法:

最后调用 client.poll() 方法,关于 socket 的一些实际的读写操作。
我们来小结一下 Sender.run() 方法的大致流程,主要分为以下五步:
accumulator.ready():遍历整个 batches(key:TopicPartition,value: Deque>),如果 ProducerBatch 不为空,就将其对应的 leader 选出来,最后会返回一个可以发送 ReadyCheckResult 实例,readyNodes 是主要的成员变量。
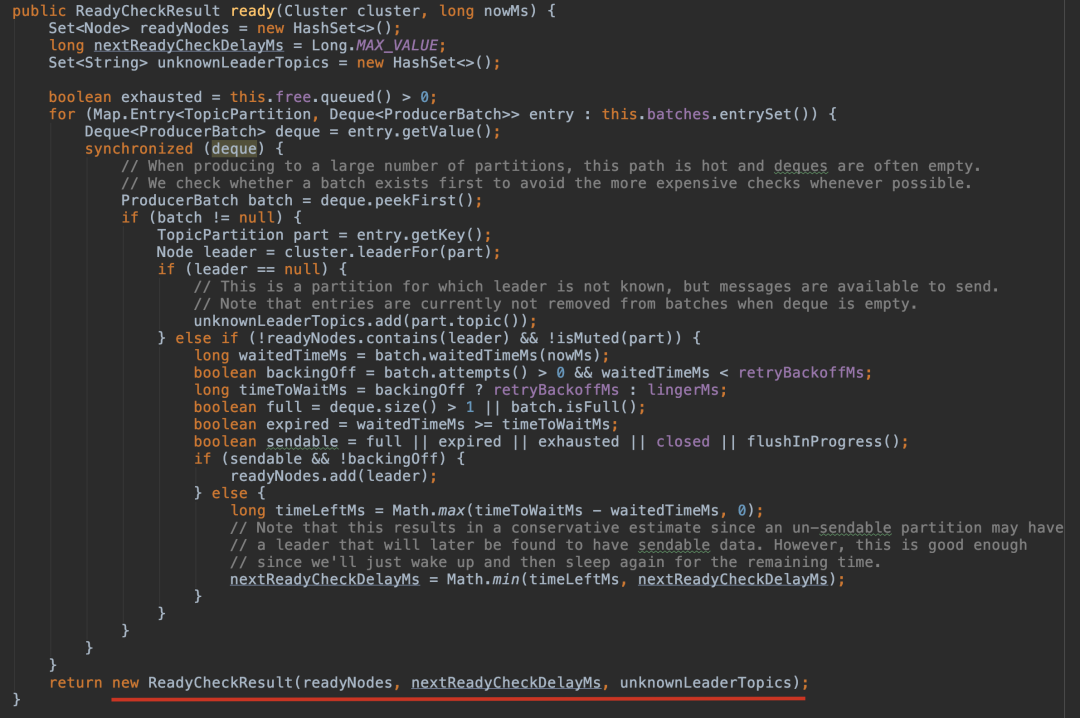
如果有 tp 的 leader 是未知的,就强制 metadata 更新。遍历未知 leader 的主题(包含 leader 选举未决的主题以及可能已经过期的主题),再次将主题添加到元数据以确保它被包含并请求元数据更新,因为有消息要发送到该主题,调用 requestUpdate() 方法来更新。
accumulator.drain():遍历每个 leader (第一步中选出)节点,获取该节点上所有的 tp,如果该 tp 对应的 ProducerBatch 不在 backoff 期间(没有重试过或者重试了但是间隔已经达到了 retryBackoffMs),并且 ProducerBatch 的大小不大于 maxSize(一个 request 的最大限制默认 1 MB)或 ProducerBatch 的集合是空的,那么就把这个 ProducerBatch 添加 list 中,最终返回的类型为 Map,key 为 leader.id,value 为要发送的 ProducerBatch 的列表。
sendProduceRequests():发送 Producer 请求,这个方法会调用 NetworkClient.send() 来发送 clientRequest。
NetworkClient.poll():关于 socket 的一些实际的读写操作,这个方法会继续调用 Kafka 封装的 Selector.poll(),跟进去底层是调用的 Java NIO 的 Selector.poll()。
2.4 org.apache.kafka.clients.NetworkClient#poll
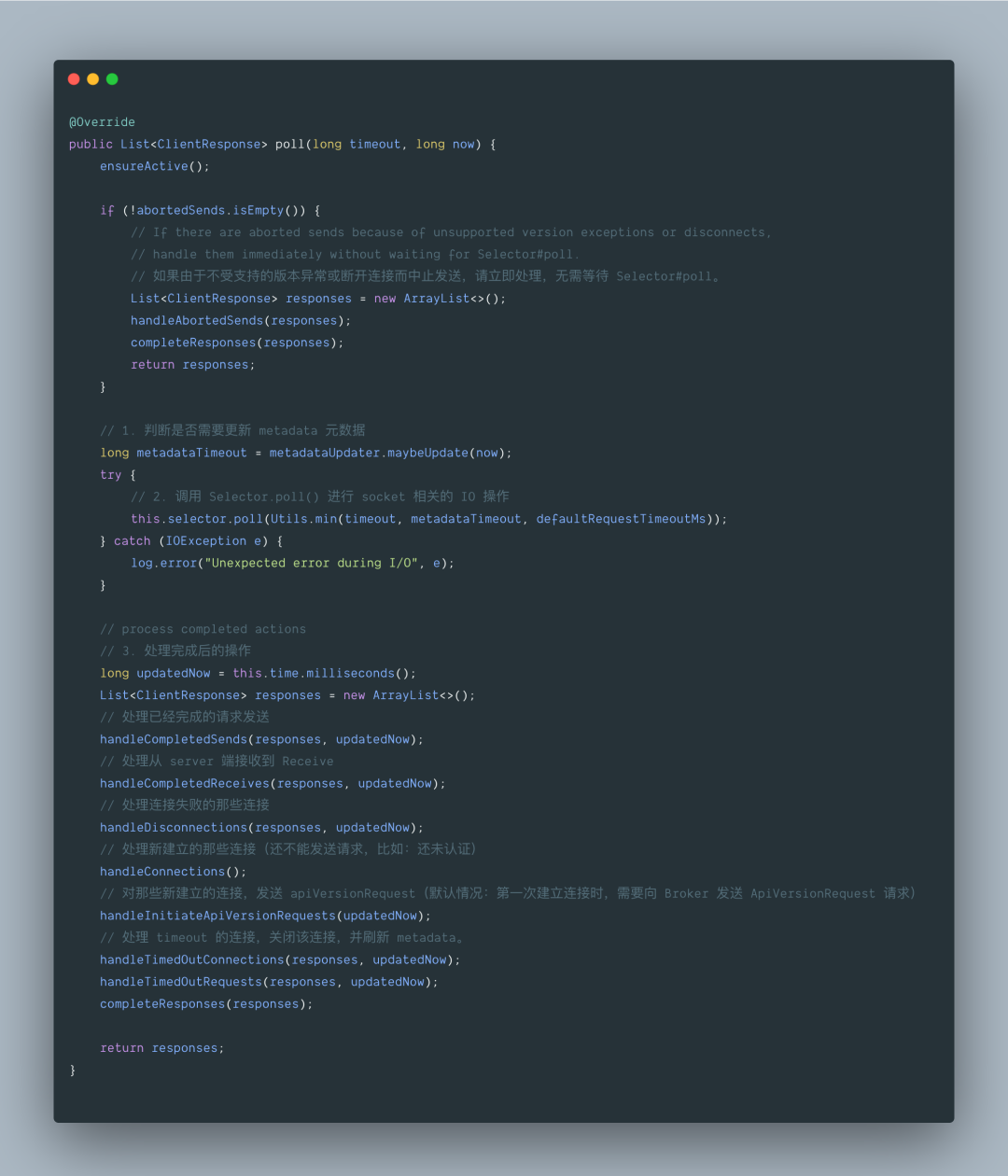
主要分为以下三步:
metadataUpdater.maybeUpdate():判断是否需要更新 metadata 元数据。选择具有最少未完成请求且至少符合连接条件的节点。此方法将更喜欢具有现有连接的节点,但如果所有现有连接都在使用,则可能会选择我们还没有连接的节点。如果不存在连接,则此方法将首选最近连接尝试最少的节点。这种方法永远不会选择一个没有现有连接的节点,并且我们在重新连接回退期间断开了连接,或者选择了一个被限制的活动连接。
selector.poll():进行 socket 相关的 IO 操作。
处理完成后的操作:在一个 select() 过程之后的相关处理
handleAbortedSends(responses):如果由于不受支持的版本异常或断开连接而中止发送,请立即处理,无需等待 Selector#poll。
handleCompletedSends(responses, updatedNow):处理任何已完成的请求发送。特别是如果预期没有响应,则认为请求已完成。
handleCompletedReceives(responses, updatedNow):处理任何已完成的接收并使用接收到的响应更新响应列表。(MetadataResponse、ApiVersionsResponse 都是在这处理的)
handleDisconnections(responses, updatedNow):处理连接失败的那些连接,重新请求 metadata。
handleConnections():处理新建立的那些连接(还不能发送请求,比如:还未认证)
handleInitiateApiVersionRequests(updatedNow):对那些新建立的连接,发送 apiVersionRequest(默认情况:第一次建立连接时,需要向 Broker 发送 ApiVersionRequest 请求)
handleTimedOutRequests(responses, updatedNow):处理 timeout 的连接,关闭该连接,并刷新 metadata。
2.5 org.apache.kafka.common.network.Selector#poll
Kafka 中的 Selector 类主要是 Java NIO 相关接口的封装,Socket 相关 IO 操作都是在这个类中完成的。主要操作都是在下面这个方法中调用的:
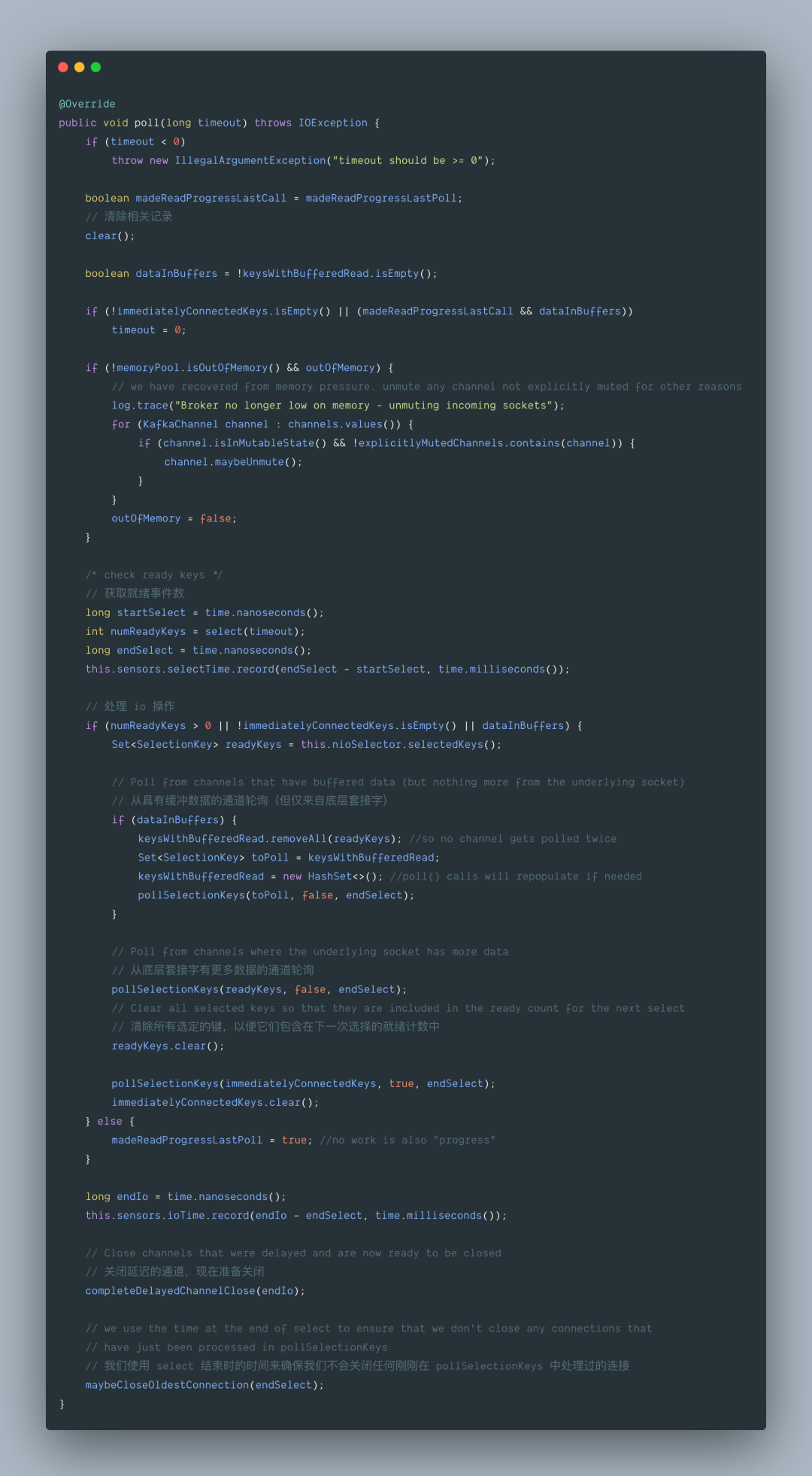
2.5.1 org.apache.kafka.common.network.Selector#clear
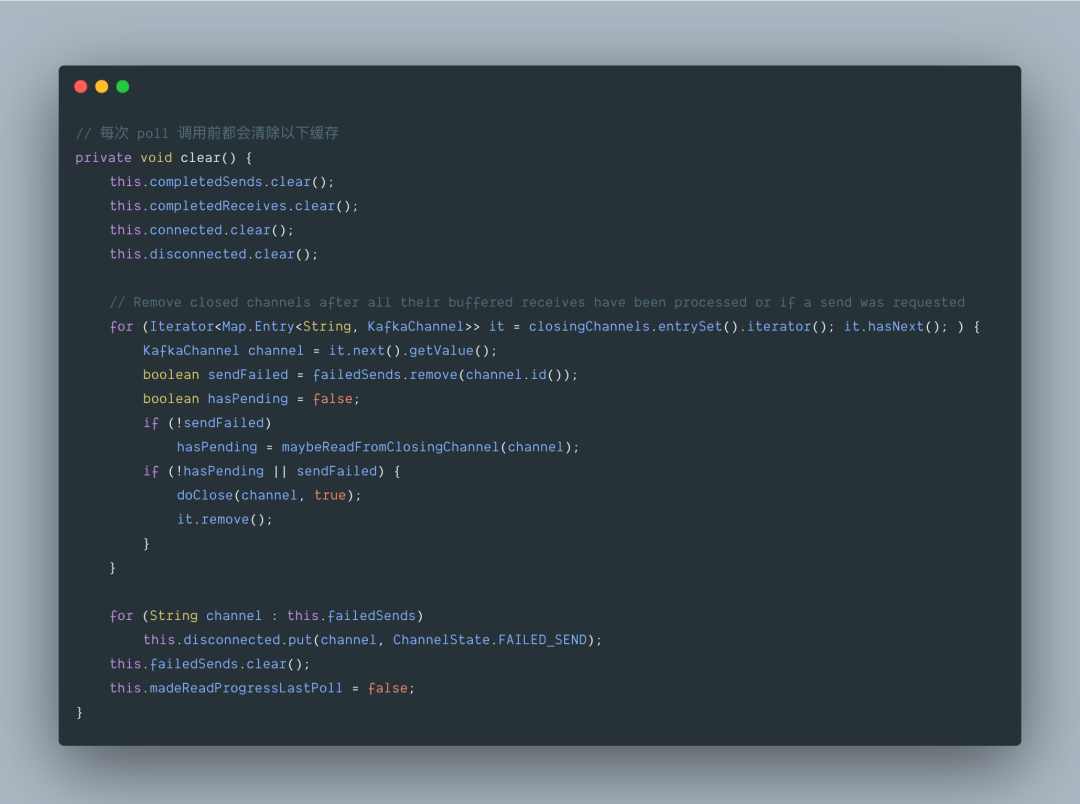
2.5.2 org.apache.kafka.common.network.Selector#select
Selector.select() 方法底层还是调用的 Java NIO 的原生接口,这里的 nioSelector 其实就是 java.nio.channels.Selector 的实例对象,这个方法最坏情况下,会阻塞 ms 的时间,如果在一次轮询,只要有一个 Channel 的事件就绪,它就会立马返回。
/**
* Check for data, waiting up to the given timeout.
*
* @param timeoutMs Length of time to wait, in milliseconds, which must be non-negative
* @return The number of keys ready
*/
private int select(long timeoutMs) throws IOException {
if (timeoutMs < 0L)
throw new IllegalArgumentException("timeout should be >= 0");
if (timeoutMs == 0L)
return this.nioSelector.selectNow();
else
return this.nioSelector.select(timeoutMs);
}
2.5.3 org.apache.kafka.common.network.Selector#pollSelectionKeys
这部分代码是 socket IO 的主要部分,发送 Send 及接收 Receive 都是在这里完成的,在 poll() 方法中,这个方法会调用三次:
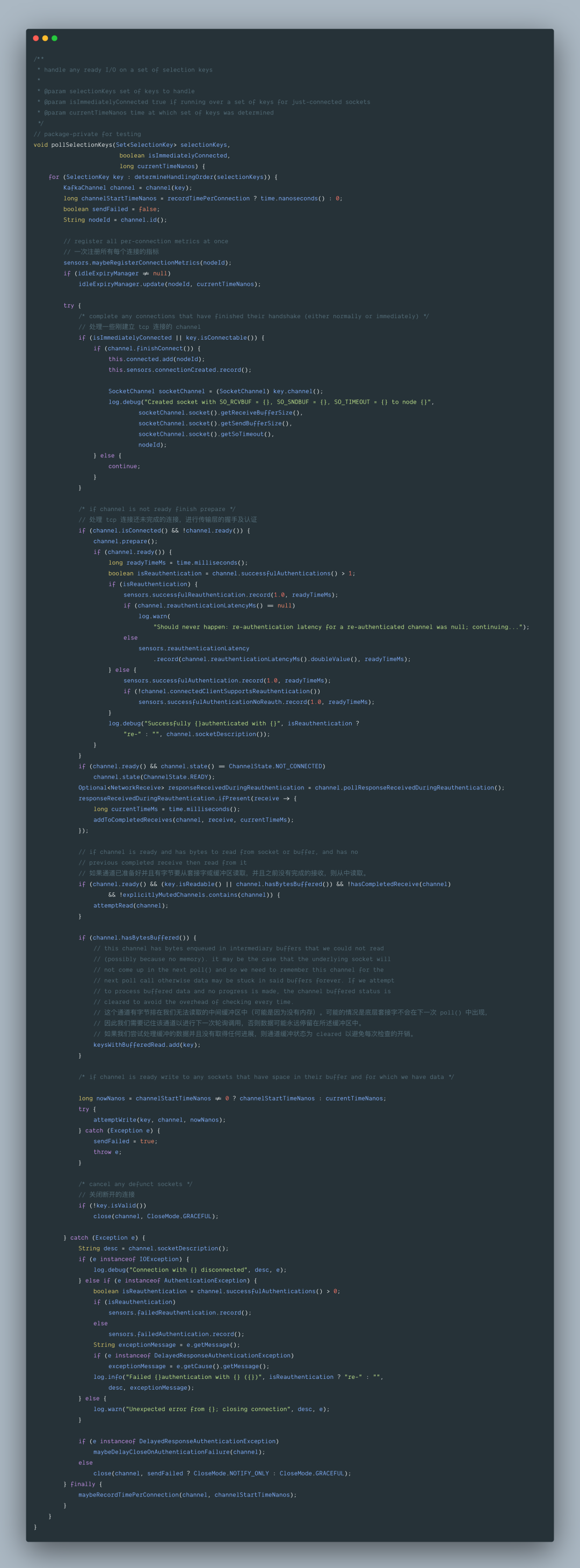
2.5.4 org.apache.kafka.common.network.Selector#addToCompletedReceives
/**
* adds a receive to completed receives
*/
private void addToCompletedReceives(KafkaChannel channel, NetworkReceive networkReceive, long currentTimeMs) {
if (hasCompletedReceive(channel))
throw new IllegalStateException("Attempting to add second completed receive to channel " + channel.id());
// 添加到 completedReceives 中
this.completedReceives.put(channel.id(), networkReceive);
sensors.recordCompletedReceive(channel.id(), networkReceive.size(), currentTimeMs);
}
接收到的所有 Receive 都会被放入到 completedReceives 的集合中等待后续处理。
三、总结
总结的话我就不复述了,上面的源码流程说的很清楚了。最后再来一张 Producer 网络模型的时序图:
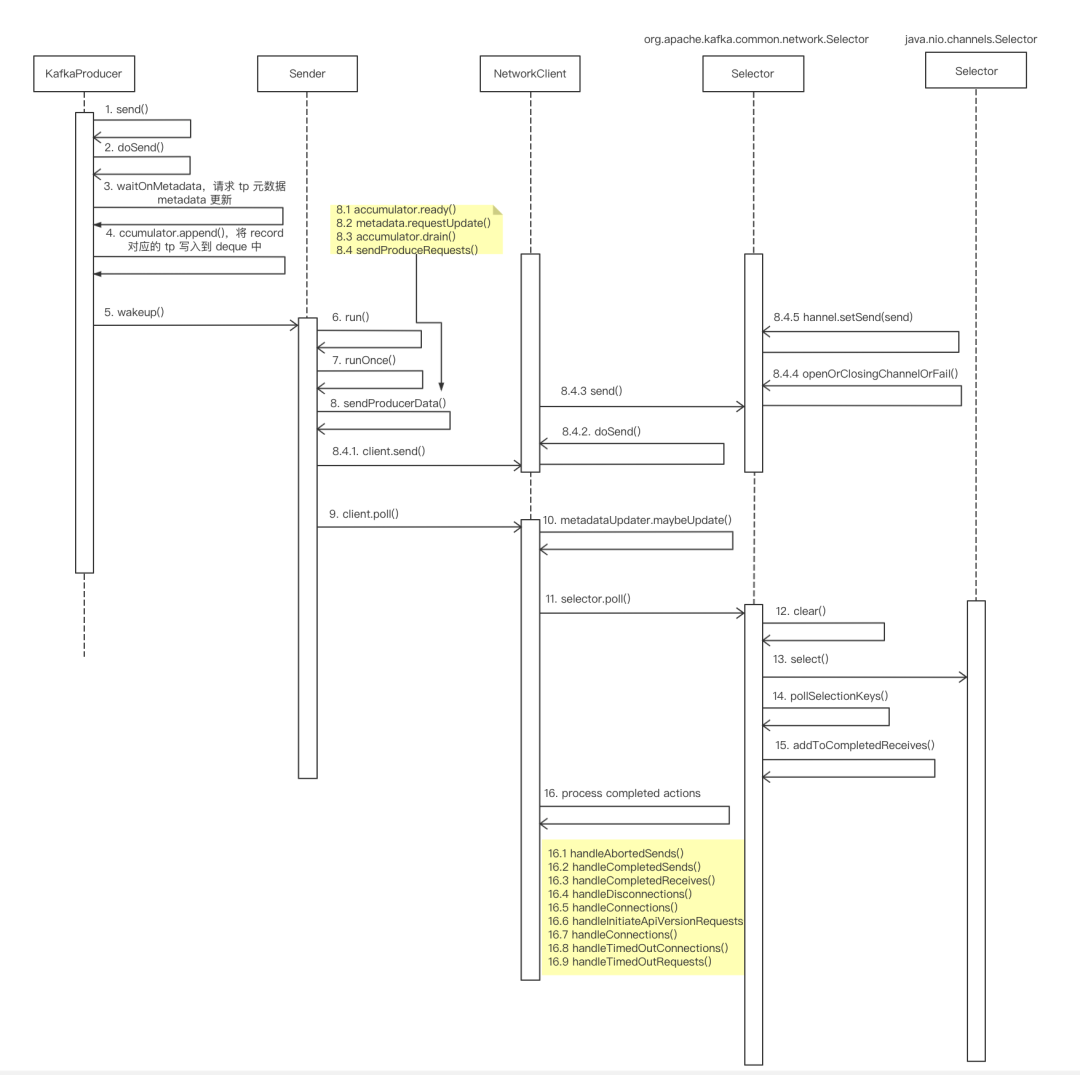
希望对你有所帮助,我们下期再见。
欢迎大家关注我的公众号【老周聊架构】,Java后端主流技术栈的原理、源码分析、架构以及各种互联网高并发、高性能、高可用的解决方案。
