
聊聊page cache与Kafka之间的事儿
 来源 | https://www.jianshu.com/p/92f33aa0ff52
来源 | https://www.jianshu.com/p/92f33aa0ff52
前言
关于Kafka的一个灵魂拷问:它为什么这么快?或者说,为什么它能做到如此大的吞吐量和如此低的延迟?
有很多文章已经对这个问题给出了回答,但本文只重点研究其中的一个方向,即对page cache的使用。先简单地认识一下Linux系统中的page cache(顺便也认识一下buffer cache)。
page cache & buffer cache
执行free命令,注意到会有两列名为buffers和cached,也有一行名为“-/+ buffers/cache”。
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001
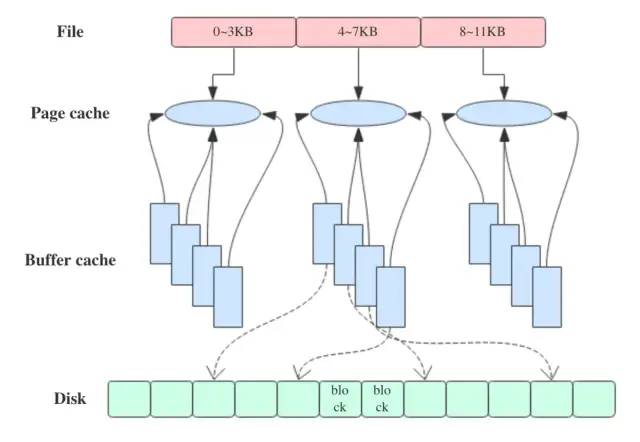
其中,cached列表示当前的页缓存(page cache)占用量,buffers列表示当前的块缓存(buffer cache)占用量。用一句话来解释:**page cache用于缓存文件的页数据,buffer cache用于缓存块设备(如磁盘)的块数据。**页是逻辑上的概念,因此page cache是与文件系统同级的;块是物理上的概念,因此buffer cache是与块设备驱动程序同级的。
page cache与buffer cache的共同目的都是加速数据I/O:写数据时首先写到缓存,将写入的页标记为dirty,然后向外部存储flush,也就是缓存写机制中的write-back(另一种是write-through,Linux未采用);读数据时首先读取缓存,如果未命中,再去外部存储读取,并且将读取来的数据也加入缓存。操作系统总是积极地将所有空闲内存都用作page cache和buffer cache,当内存不够用时也会用LRU等算法淘汰缓存页。
在Linux 2.4版本的内核之前,page cache与buffer cache是完全分离的。但是,块设备大多是磁盘,磁盘上的数据又大多通过文件系统来组织,这种设计导致很多数据被缓存了两次,浪费内存。所以在2.4版本内核之后,两块缓存近似融合在了一起:如果一个文件的页加载到了page cache,那么同时buffer cache只需要维护块指向页的指针就可以了。只有那些没有文件表示的块,或者绕过了文件系统直接操作(如dd命令)的块,才会真正放到buffer cache里。因此,我们现在提起page cache,基本上都同时指page cache和buffer cache两者,本文之后也不再区分,直接统称为page cache。
下图近似地示出32-bit Linux系统中可能的一种page cache结构,其中block size大小为1KB,page size大小为4KB。
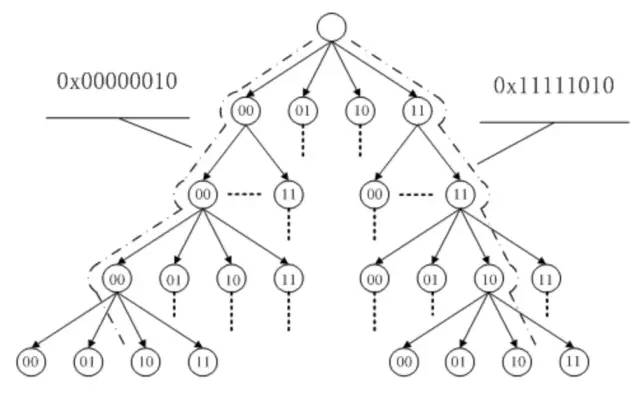
page cache中的每个文件都是一棵基数树(radix tree,本质上是多叉搜索树),树的每个节点都是一个页。根据文件内的偏移量就可以快速定位到所在的页,如下图所示。关于基数树的原理可以参见英文维基,这里就不细说了。
接下来就可以把Kafka扯进来了。
Kafka对page cache的利用
Kafka为什么不自己管理缓存,而非要用page cache?原因有如下三点:
JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间; 如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量; 一旦程序崩溃,自己管理的缓存数据会全部丢失。
Kafka三大件(broker、producer、consumer)与page cache的关系可以用下面的简图来表示。
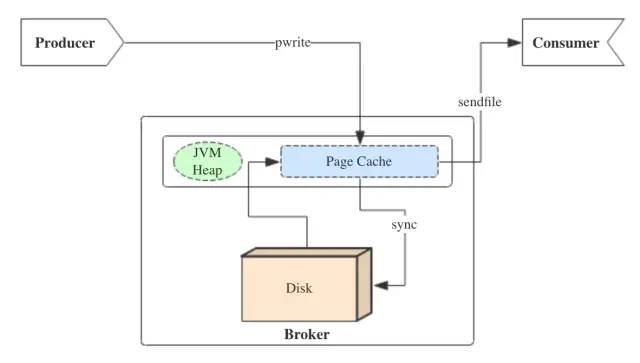
producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
图中没有画出来的还有leader与follower之间的同步,这与consumer是同理的:只要follower处在ISR中,就也能够通过零拷贝机制将数据从leader所在的broker page cache传输到follower所在的broker。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。这个结论俗称为“读写空中接力”。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
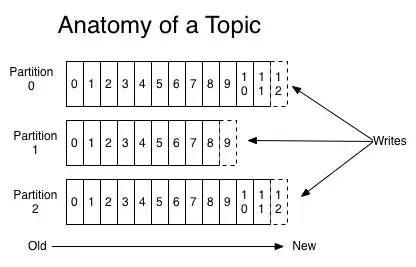
关于Kafka的磁盘存储机制,可以参见美团技术团队的大作 https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html。
注意事项与相关参数
对于单纯运行Kafka的集群而言,首先要注意的就是为Kafka设置合适(不那么大)的JVM堆大小。从上面的分析可知,Kafka的性能与堆内存关系并不大,而对page cache需求巨大。根据经验值,为Kafka分配6~8GB的堆内存就已经足足够用了,将剩下的系统内存都作为page cache空间,可以最大化I/O效率。
另一个需要特别注意的问题是lagging consumer,即那些消费速率慢、明显落后的consumer。它们要读取的数据有较大概率不在broker page cache中,因此会增加很多不必要的读盘操作。比这更坏的是,lagging consumer读取的“冷”数据仍然会进入page cache,污染了多数正常consumer要读取的“热”数据,连带着正常consumer的性能变差。在生产环境中,这个问题尤为重要。
前面已经说过,page cache中的数据会随着内核中flusher线程的调度写回磁盘。与它相关的有以下4个参数,必要时可以调整。
/proc/sys/vm/dirty_writeback_centisecs:flush检查的周期。单位为0.01秒,默认值500,即5秒。每次检查都会按照以下三个参数控制的逻辑来处理。 /proc/sys/vm/dirty_expire_centisecs:如果page cache中的页被标记为dirty的时间超过了这个值,就会被直接刷到磁盘。单位为0.01秒。默认值3000,即半分钟。 /proc/sys/vm/dirty_background_ratio:如果dirty page的总大小占空闲内存量的比例超过了该值,就会在后台调度flusher线程异步写磁盘,不会阻塞当前的write()操作。默认值为10%。 /proc/sys/vm/dirty_ratio:如果dirty page的总大小占总内存量的比例超过了该值,就会阻塞所有进程的write()操作,并且强制每个进程将自己的文件写入磁盘。默认值为20%。
由此可见,调整空间比较灵活的是参数2、3,而尽量不要达到参数4的阈值,代价太大了。
- END -