elasticsearch血泪史之没禁用的_source
多图预警
现状
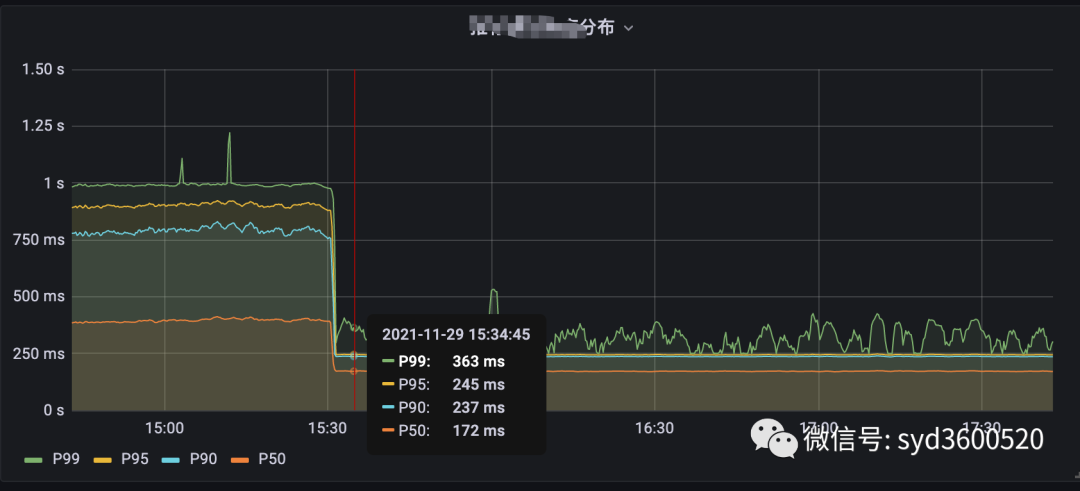
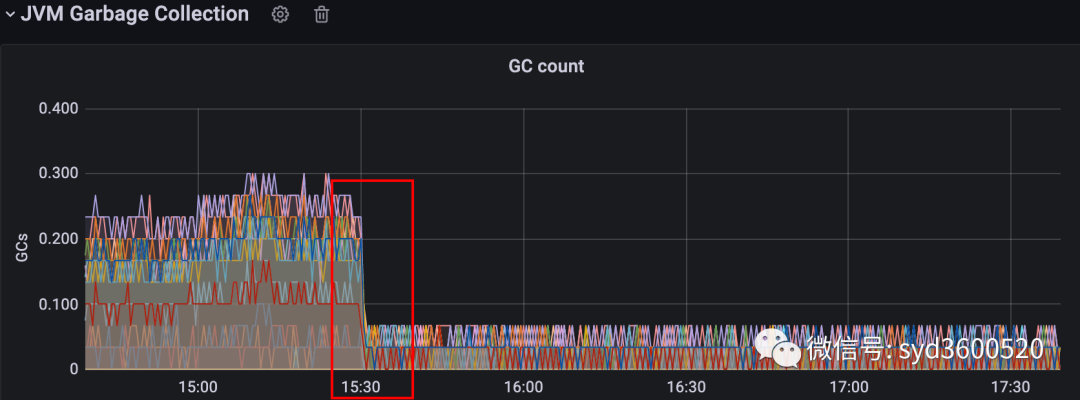
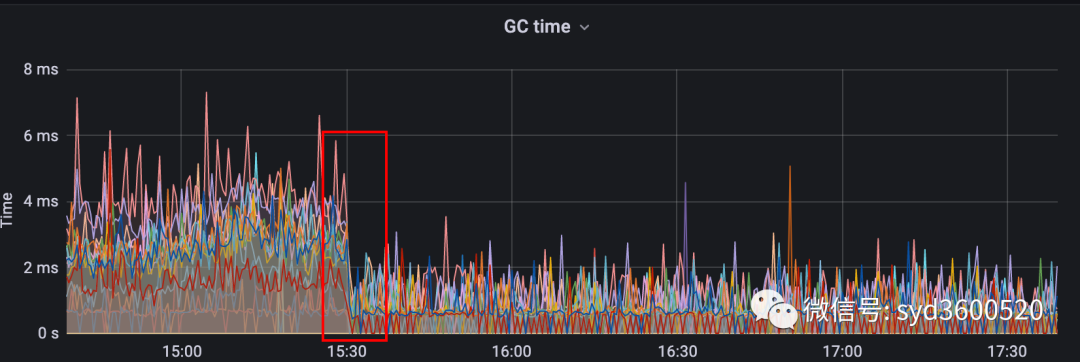
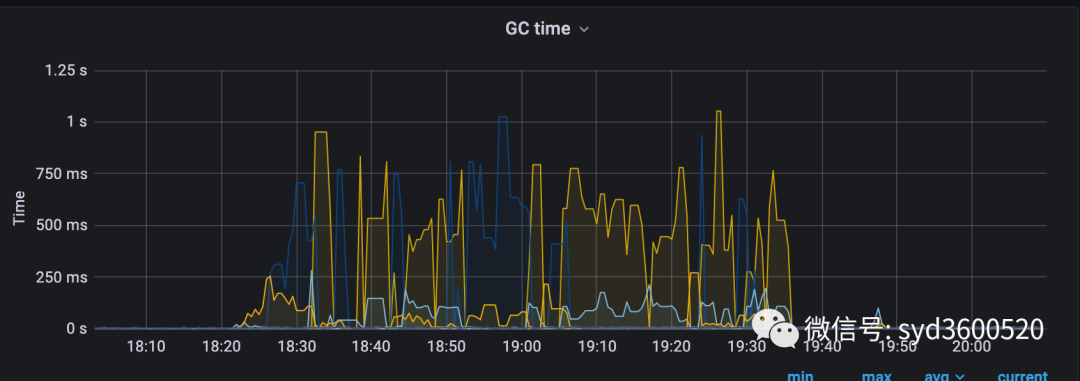
生产上某个服务使用了ElasticSearch作为检索引擎,但是偶发性出现gc明显抖动,进而导致接口响应超时
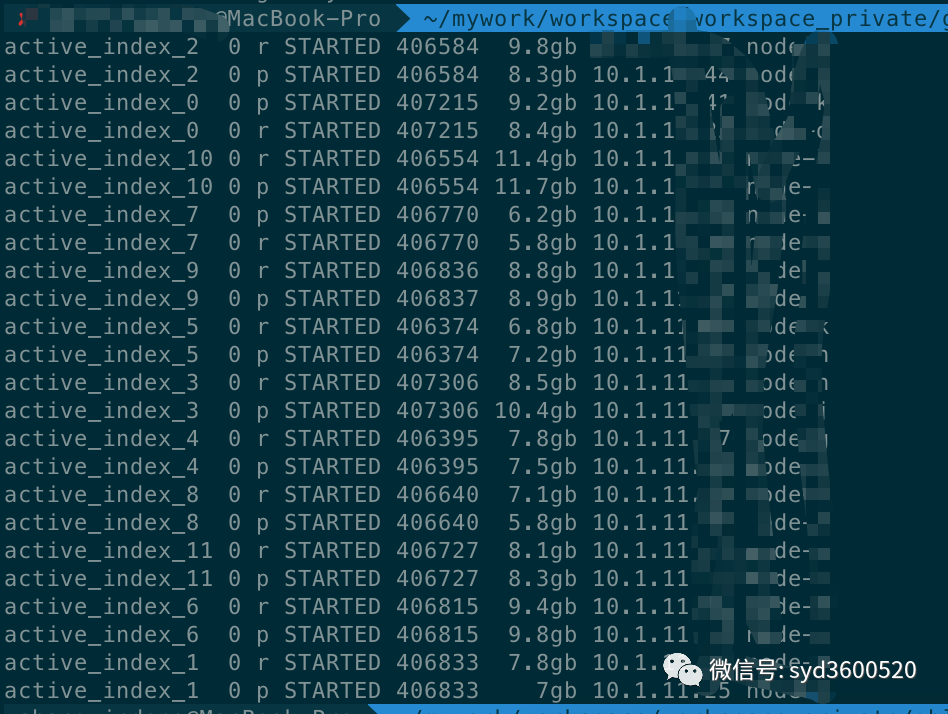
分析了一下我们的es集群规模并不大 ,以下是各个索引的情况
虽然我们是单服务器多节点部署data node但是机器配置的CPU、Memory都很高,在流量没有激增的情况下,出现这种GC问题,有点儿说不过去。。。
解决这个问题,中间绕了很多弯路,看到GC问题就一门心思想着优化GC参数,虽然确实也收到了一定疗效,(毕竟我们之前都是ES默认的GC参数配置)但是并没解决根本问题。最后还是运维同学帮忙分析指明了方向,茅塞顿开。
总结一句话:
查询的问题还是得从查询找起。
类似于MySQL、Postgresql查询分析器explain,es也有自己的查询分析器---profile
es查询大杀器profile
profile的用法比较简单,eg
curl -XGET 'localhost:9200/_search?pretty' -H 'Content-Type: application/json' -d'
{
"profile": true,
"query" : {
"match" : { "message" : "message number" }
}
}
只需要在任意_search请求添加一个顶级的profile参数即可。
我们选择生产上一个慢查询,profile执行如下
{
"took": 113,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"max_score": null,
"hits":[...]
},
"profile": {
"shards": [
{
"id": "[o2lxbK6lQ6-z2X3UDvAh8w][active_index_1][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "-RecommendTags:[1 TO 1] -InitiativeRelationUIds:[15911945 TO 15911945] -PassiveRelationUIds:[15911945 TO 15911945] #Gender:female #ActiveTime:[1637754 TO 2147483647] #Birthdate:[722864543 TO 1290858142] #AgeRangeSetting: #IncomeRange: #IncomeRangeSetting: #Height:[120 TO 250] #HeightRangeSetting: #Education:[0 TO 7] #EducationRangeSetting: #HouseSetting:{0 1} #ConstantScore(HometownSetting: HometownSetting:120000000000) #ConstantScore(MaritalStatusSetting:0 MaritalStatusSetting:1)" ,
"time_in_nanos": 12468368,
"breakdown": {
"set_min_competitive_score_count": 0,
"match_count": 3187,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"next_doc": 2306828,
"match": 190778,
"next_doc_count": 3187,
"score_count": 0,
"compute_max_score_count": 0,
"compute_max_score": 0,
"advance": 569941,
"advance_count": 28,
"score": 0,
"build_scorer_count": 56,
"create_weight": 76451,
"shallow_advance": 0,
"create_weight_count": 1,
"build_scorer": 9317911
},
...略
}
],
"rewrite_time": 32084,
"collector": [
{
"name": "SimpleFieldCollector",
"reason": "search_top_hits",
"time_in_nanos": 1182060
}
]
}
],
"aggregations": []
}
]
}
}
上面结果咋一看比较懵,核心参数如下
took 表示本次查询耗时 id 对于每个参与查询影响的shard都将会返回一个分析报告,并由唯一的ID标识 query 显示对应shard上查询的详细分析内容 rewrite_time 每个profile都包含一个单独的累计的重写时间 (Lucene 中的所有查询都经过重写过程。查询(及其子查询)可能会被重写一次或多次,并且该过程会一直持续到查询停止更改为止。这个过程允许 Lucene 进行优化,比如去除多余的子句,替换一个查询以获得更高效的执行路径等。例如一个 Boolean → Boolean → TermQuery 可以重写为一个 TermQuery,因为在这种情况下所有的布尔值都是不必要的.) collector 关于运行搜索的Lucene收集器的分析,收集器负责协调匹配文档的遍历、评分和收集。 aggregations 聚合分析的详细信息
此查询不存在聚合所以aggregations空,故而我们着重关注下query部分:
query部分包含了Lucene在特定分片上执行的查询树的详细计时。
其中query中的breakdown罗列出了有关低级别Lucene执行的详细计时统计信息。breakdown只是为了给你一些感知:
Lucene 中的哪些机器在实际消耗时间 不同组件之间时间差异的大小
详细细节可以阅读官方文档(https://www.elastic.co/guide/en/elasticsearch/reference/current/search-profile.html)
我们主要来看下time_in_nanos它表示此查询耗时12468368(~12ms)且包含了其子查询的耗时。
那么问题来了,这个耗时跟took的113ms差了100+ms,Why?
基本原理
es查询包括两个phase,query phase 和 fetch phase,
其中 query phase 遍历所有分片,拿到 _id 和 score,fetch phase 再根据 id 第二次查询分片获取 _source不返回_source 可以避免第二次分片内的查询
上面我们看到查询总共耗时113ms,其中query phase部分耗时12ms,那么就是fetch phase的问题,难道我们使用了_source?
检查代码发现
req := esapi.SearchRequest{
Index: []string{"active_index"},
Body: strings.NewReader((*buf).String()),
Size: &querySize,
TrackTotalHits: false,
Source: []string{"_id"},
}
es的req请求构建初始化过程加了一行Source:[]string{_id},_id其实并不在_source中,傻乎乎跑去_source中去查,还没查到。。。
解决办法:
禁用掉_source,因为我们并不需要除了_id以外的数据。
req := esapi.SearchRequest{
Index: []string{"active_index"},
Body: strings.NewReader((*buf).String()),
Size: &querySize,
TrackTotalHits: false,
Source: []string{"false"},
}
这么小小一个改动,优化后结果如图Orz