
应用案例:快手是如何利用「生存分析」?
导读:随着互联网的发展,一些常规北极星指标不能准确反映业务现状,例如DAU只体现了一定时间窗口内用户留存的结果,而用户行为是随时间推移陆续发生的,发生时间的快慢包含许多业务决策信息。本文将介绍快手数据科学家是如何利用生存分析对用户活跃进行全新的解读,在关注事件结果的同时,也将事件发生的时间纳入日常分析框架,有效刻画事件随时间变化的规律。
具体将从以下几部分展开:
为什么选择生存分析描述用户活跃度
生存分析概述
使用生存分析理解用户活跃表现
生存分析业务应用举例
Kwai Survival:基于深度学习的生存分析模型
1. DAU的局限性

DAU经常被互联网公司用作衡量活跃用户的北极星指标。它的计算非常简单,在某天24小时内,如果有一个用户曾访问过app,则计为1个DAU。
然而,用户的行为是随时间推移陆续发生的,发⽣时间的快慢和发生的频次都能为分析决策提供重要的信息;而DAU只体现了一定时间窗口内用户留存的结果,是个binary的结果,并未描述出重要的时间信息。
举一个具体的例子:快手app在A城市和B城市均有100万DAU;但A城市的⽤户每隔4⼩时使⽤⼀次快手(即每天6个sessions),而B城市的⽤户每隔6⼩时使⽤⼀次快手(即每天4个sessions)。那么,A、B两个城市谁的⽤户活跃度更⾼呢?如果使用DAU作为衡量指标,A、B的活跃度是一样的;如果将时间维度考虑进去的话,可以看出两个城市的用户访问app的频次强度,也就是活跃度,是存在显著差别的。
2. 为什么选择⽣存分析
一般的回归模型处理的是截面数据,只关注事件的结果(例如用户是否打开了我们的APP);但生存分析不仅关注事件的结果,还将事件发⽣的时间纳入了模型的分析框架,能够有效刻画事件的发生时间,以及事件随时间变化的规律。
生存分析有别于传统的数据分析方法论,对于很多数据科学家、算法工程师来说,生存分析可能会是个比较陌生的概念。接下来会着重对生存分析做一个概述。
1. ⽣存分析基本概念
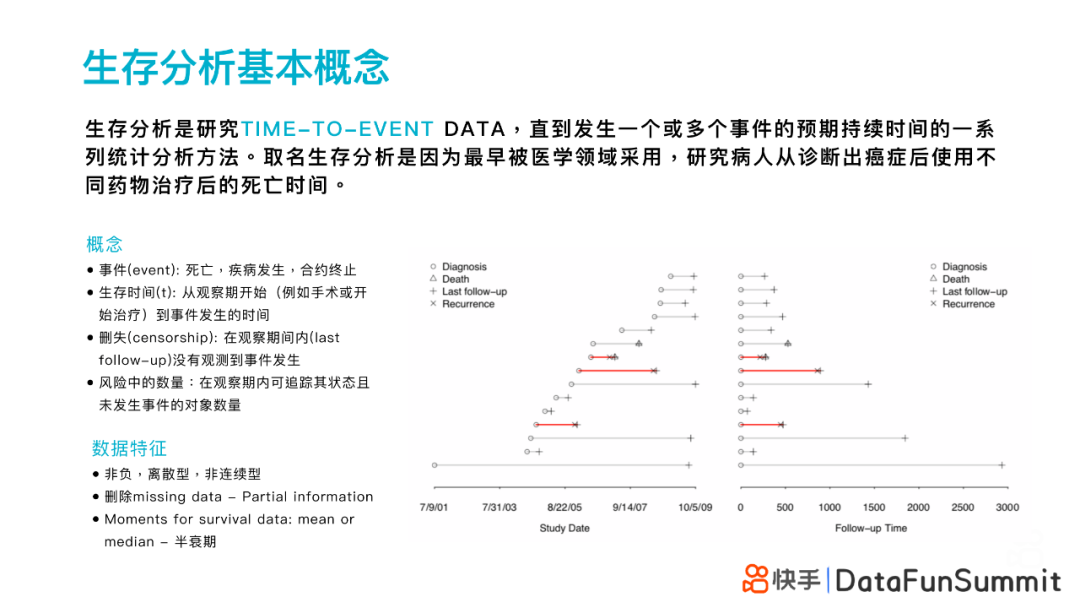
生存分析最早被医学领域采⽤,研究病⼈从诊断出癌症后使⽤不同药物治疗后的死亡时间;⽣存分析主要是研究直到发⽣⼀个或多个事件的预期持续时间的⼀系列统计分析⽅法,处理的是TIME-TO-EVENT DATA(sequential event data)。
生存分析基本概念汇总:
事件(event):例如死亡、疾病发⽣、合约终止等;本文中提到的事件是指用户活跃,例如用户是否打开APP。
⽣存时间(t):从观察期开始到事件发⽣的时间。例如⼿术或开始治疗的时间、上次到下次打开APP的时间等。
删失(censorship):在观察期间内(last follow-up)没有观测到事件发⽣。
⻛险中的数量:在观察期内可追踪其状态且未发⽣事件的对象数量。
生存分析的数据特征:
非负,离散型,非连续型变量
不包含missing data
Moments for survival data:mean or median - 半衰期
右图展示的是典型的生存分析研究:病人诊断出癌症是在不同的时间段,发生死亡或者删失也是在不同的时间段,但经过生存分析基本概念的变化能够把所有事件开始的时间拉到一个统一的基准线,从而进行下一步的研究。
2. 生存分析几个重要函数
接下来我们来学习几个生存分析中的重要函数。

3. 生存函数的刻画
生存函数一般有两种刻画方法:参数方法与非参数法。参数法假定⽣存时间符合某种分布(如指数分布、威布尔分布、对数正态分布等),根据样本观测值来估计假定分布模型中的参数,以获得⽣存时间的概率密度模型;非参数法即不对数据分布做任何假设,直接用概率乘法定理估计生存率,常见的方法包括KaplanMeier曲线、NelsonAalen累计⻛险曲线等。本文重点介绍非参数方法,并主要使用KM曲线描述生存函数。
前文所述的概念、函数等可能太过抽象,不易理解;接下来我们举几个具体的例子来形象化地理解生存函数。
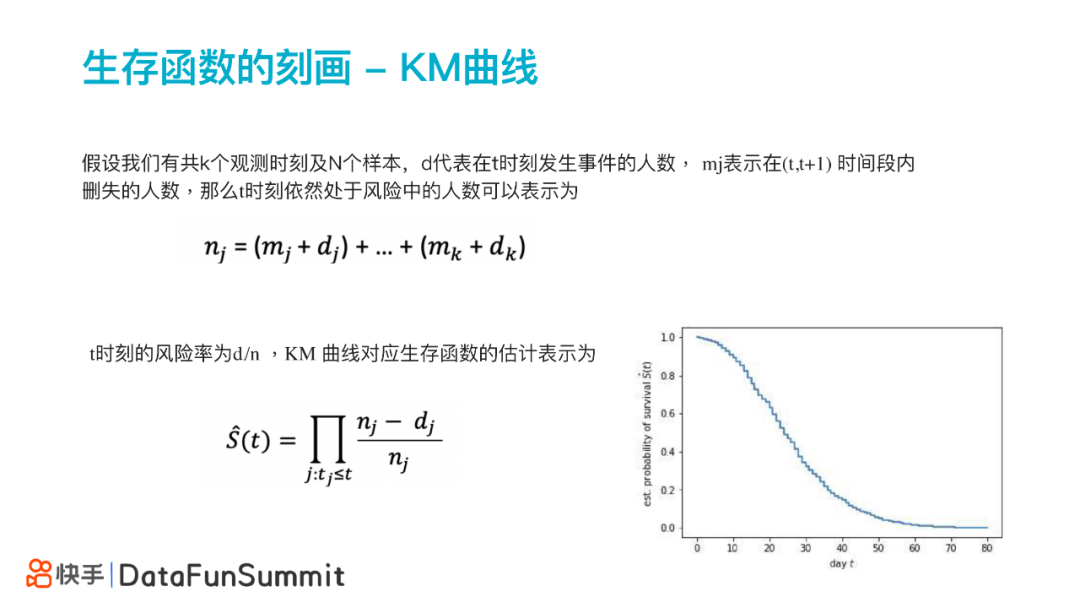
假设我们有共k个观测时刻及N个样本,d代表在t时刻发⽣事件的⼈数,mj表示在(t,t+1)时间段内删失的⼈数,那么t时刻依然处于⻛险中的⼈数等于删失的人数+t时刻发生事件的人数;可以表示为:
nj=(mj+dj)+...+(mk+dk)
这样,t时刻的风险率为dj/n,KM曲线对应⽣存函数的估计表示为:
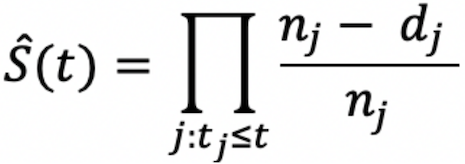
即样本总数减去t时刻发⽣事件的⼈数d,再除以样本总数;最后基于此做累乘而得,形状如右图曲线所示。
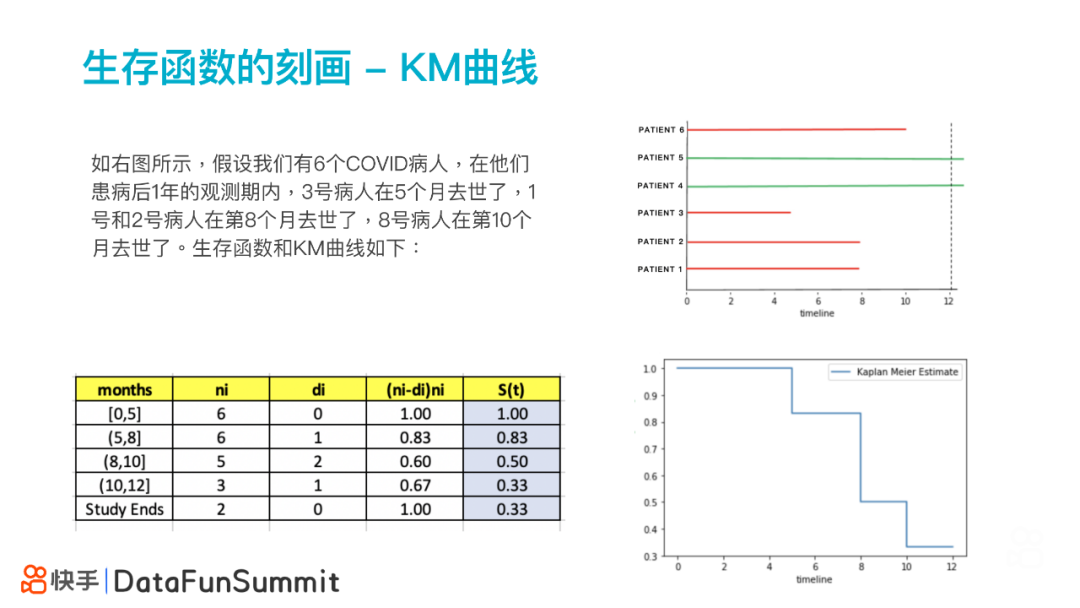
进一步具体化地描述一个case:目前疫情正在肆虐全球,假设初始时刻我们共有6个COVID病⼈,在他们患病后1年的观测期内,3号病⼈在5个⽉去世了,1号和2号病⼈在第8个⽉去世了,8号病⼈在第10个⽉去世了,有2个人存活(即删失)。如右图所示。
将以上case具体化,可以得到上图下方的生存函数表和KM曲线。
以上是对生存分析的大致介绍以及几个简单的使用案例,相信读者们已经对生存分析的核心概念有了初步的理解。接下来我们会结合快手的具体应用场景,详细介绍如何使用生存分析帮助数据分析师和业务决策者理解用户的活跃表现。
1. 主要应用场景
在快手,数据科学家和分析师们利用生存分析做深入研究的应用场景主要包括以下4类:

2. 使用KM曲线刻画用户群体的活跃度
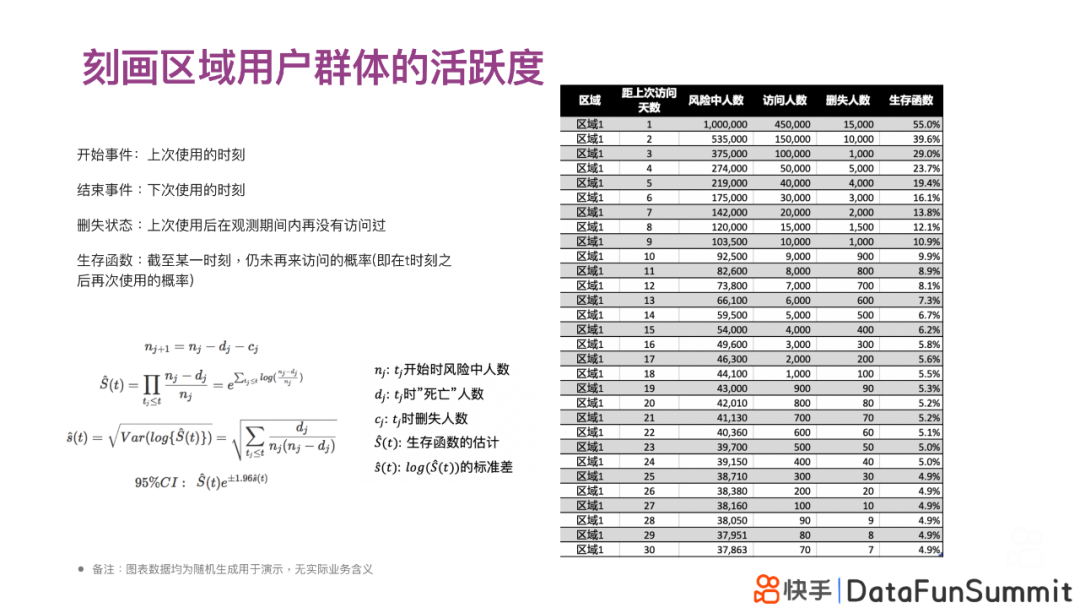
在介绍基于KM曲线刻画用户群体活跃度之前,我们首先将刚才介绍的生存分析基本概念和与描述用户群体活跃度的相关状态做一一映射:
开始事件:某用户上次使用快手app的时刻;
结束事件:该用户再次使用快手app的时刻;
删失状态:上次使用后,在观测期间再没有访问过;
生存函数:截止某时刻,该用户仍未再次访问的概率。
为了更直观地理解,我们模拟并虚构了某个区域用户的活跃数据(风险中人数、访问人数、删失人数等),并计算了随时间变化该区域的生存函数变化,如右图表格所示。
在上表中,“再次访问”代表事件,“未再次访问”代表删失;该区域研究的初始风险中人数为1,000,000,随后每次观测得到的风险中人数,可以通过前一观测时刻的风险中人数,减去该次观测的访问人数,再减去删失人数而最终得到。也就是根据如下公式:
nj+1=nj-dj-cj
式中,nj代表tj时的风险中人数;dj代表tj时“死亡”(即发生再次访问)的人数;cj代表tj时“删失”(即未发生再次访问)的人数。
类似地,生存函数的计算公式为:
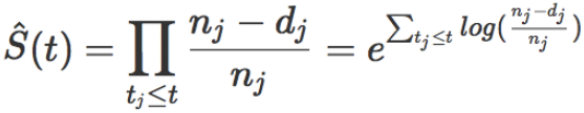
有了生存函数,我们就可以很容易地通过几个函数间的关系换算得到用户的留存曲线、风险曲线等。
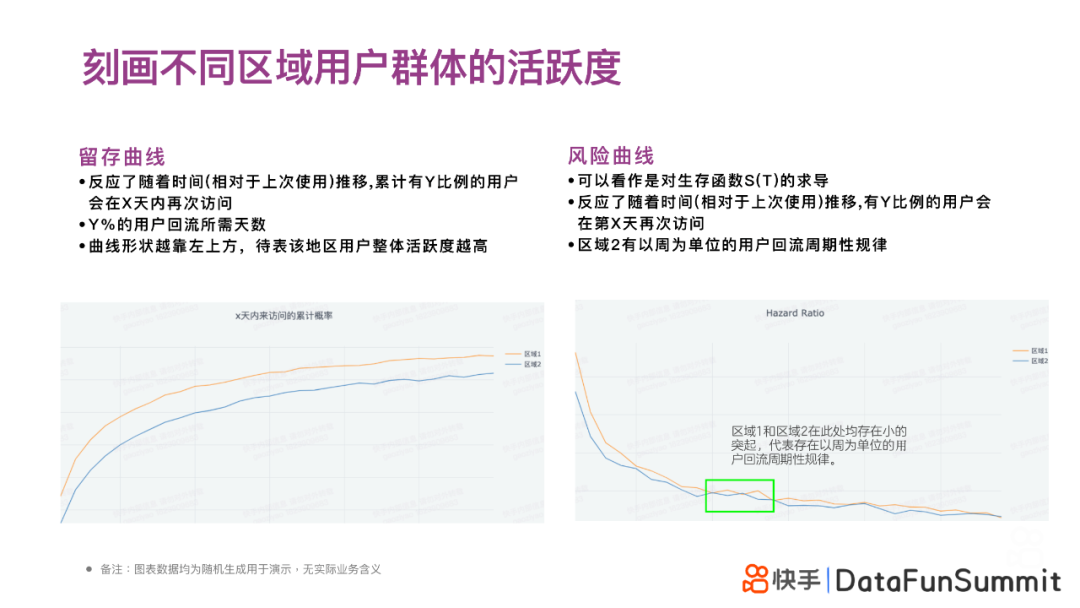
留存曲线反映了随着时间推移,累计有Y比例的用户会在X天内再次访问;换一个角度解读,也可以理解为Y%的用户回流需要多少天。曲线形状越靠近左上方,代表该地区用户整体活跃度越高。
风险曲线可以看做是生存函数S(t)的求导,能反映出随着时间推移,有Y比例的用户会在第X天再次访问;风险曲线可以帮助发现用户活动的周期规律,下图中区域2体现了以周为单位的用户回流周期性。和留存曲线相似,风险曲线也是越靠近左上方,该区域的的用户整体活跃度越高。
3. 刻画区域用户群体的活跃度
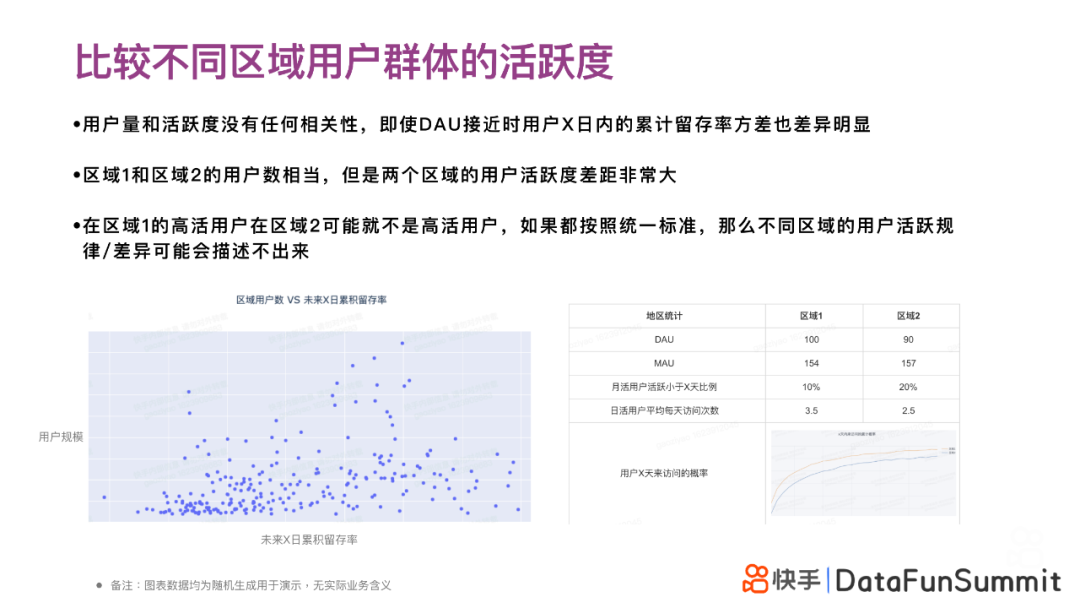
下面我们看一个通过生存分析比较不同区域用户群体活跃度的例子。在左下这个散点图中,纵坐标“用户规模”体现的是用户量(DAU),横坐标“未来X日累计留存率”体现的是用户的活跃度。从图上看,用户量和用户活跃度几乎没有明显的相关性。实际上,即使两个区域的DAU规模比较接近,用户在X日内的累计留存率的差异也许是非常大的。如右下图所示,区域1和区域2的用户数相当,而且DAU、MAU相差也不大,用户粘性因子(DAU/MAU)数值也相近。但是如果使用生存函数去分析两个区域用户的活跃度,就会发现两者的差距非常大:例如计算月活用户活跃小于X天的比例,发现区域1只有10%,而区域2达到20%;同样,计算日活用户平均访问次数,发现区域1的平均访问次数为3.5,而区域2的平均访问次数仅有2.5。这就意味着,区域2的高活用户在区域1可能就不是高活用户;如果按照统一标准,那么不同区域的用户活跃规模的异质性就难以描述出来。
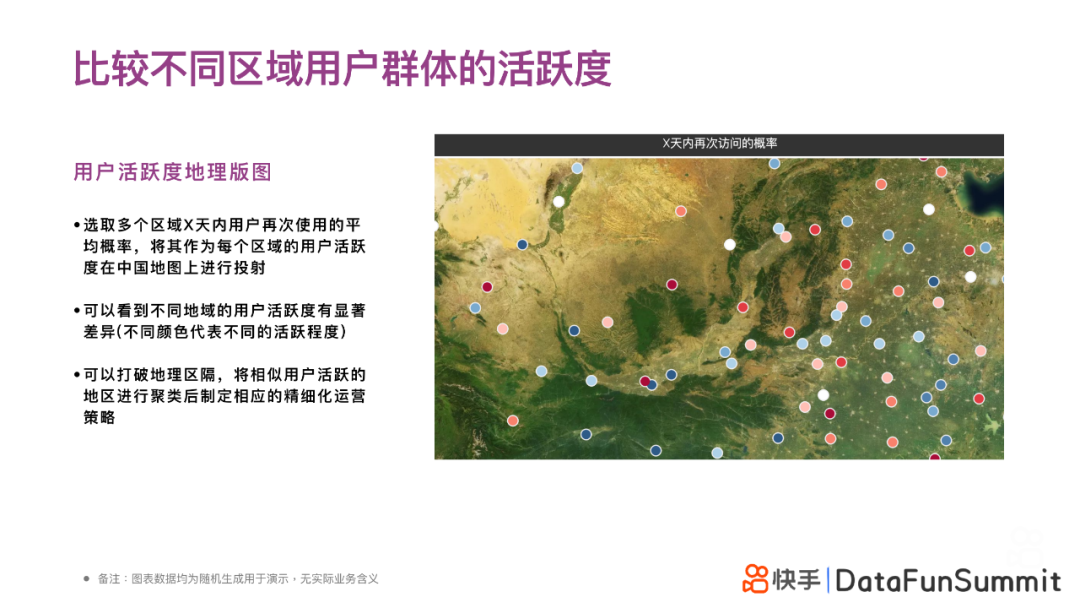
为了更直观地体现不同地理区域用户活跃度差异,我们引入了⽤户活跃度地理版图,把基于生存分析框架下计算得出的用户生存概率在地图上进行投射。图中,不同的颜色标识X天内再次访问的概率的大小,可以看出,在不同区域的用户活跃是有显著差异和地理聚集性的。对于业务决策者来说,如果想要整体提升用户的活跃度,可以尝试打破地理区域的间隔,将相似用户活跃的地区进行聚类后制定相应的精细化运营策略。
4. 用户活跃度影响因⼦建模
① 回归模型:
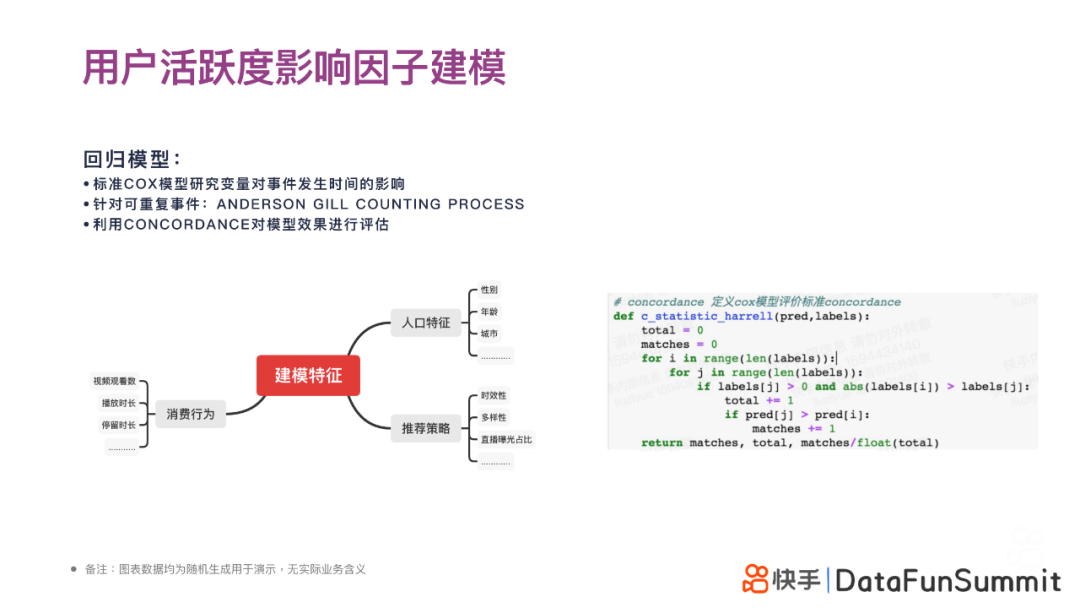
接下来着重介绍生存函数的建模,探索用户活跃度的影响因子。这里首先介绍标准COX回归模型,该模型主要研究变量对事件发⽣时间的影响。针对一些可重复的事件,可使用ANDERSON GILL COUNTING PROCESS(安德森-吉尔计数法)。
对于模型效果的评估,这里不能采用分类模型常用的AUC方法;本文采⽤CONCORDANCE对模型效果进⾏评估,具体定义如右图所示。
对于建模特征,主要引入人口特征、消费行为特征和推荐策略特征3大类别。
② 影响⽤户活跃度的贡献度排序
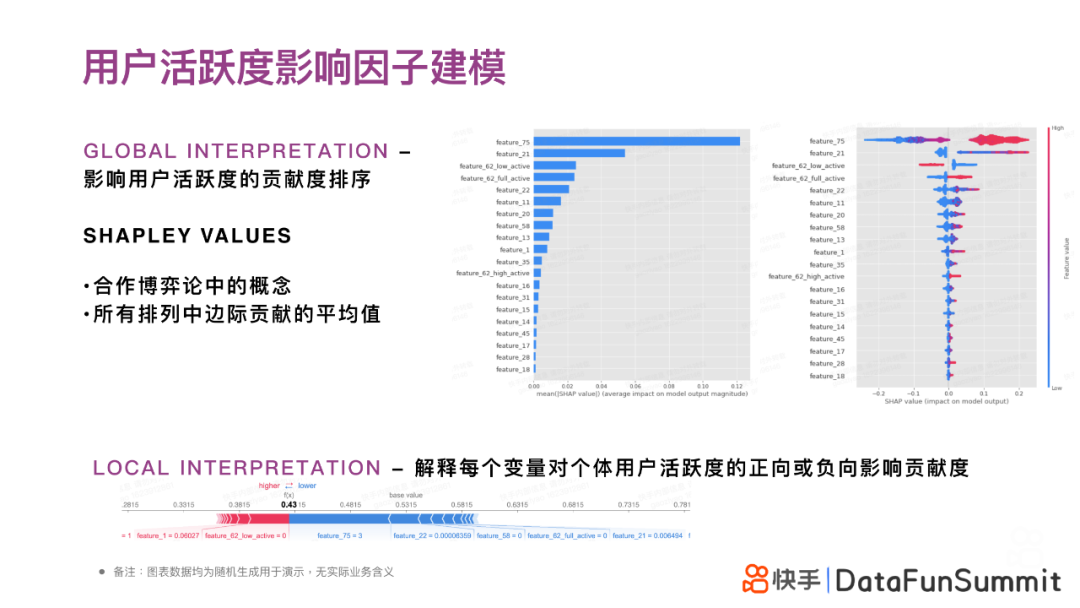
可以使用COX模型结合SHAPLEY VALUES来对影响用户活跃的特征贡献度进行排序,从而直观展示哪些些特征对用户的活跃影响更大。例如,从左下图可以看出,feature_75是最影响用户活跃度的,其次是feature_21)。右下图SHAPLEY VALUES是博弈论中的一个概念,是解释所有排列中特征边际贡献的平均值。
我们不仅可以把SHAPLEY VALUES中每个特征边际贡献的平均值作为GLOBAL INTERPRETATION来解释特征对所有用户的平均效用,同时SHAPLEY VALUES也可以输出下图中的LOCAL INTERPRETATION,用来解释每个特征对不同⽤户活跃度的正向或负向影响贡献度。
接下来我们分享几个快手数据科学家是如何由把生存分析应用到业务策略的具体实例。
1. 用户活跃度分层和聚类
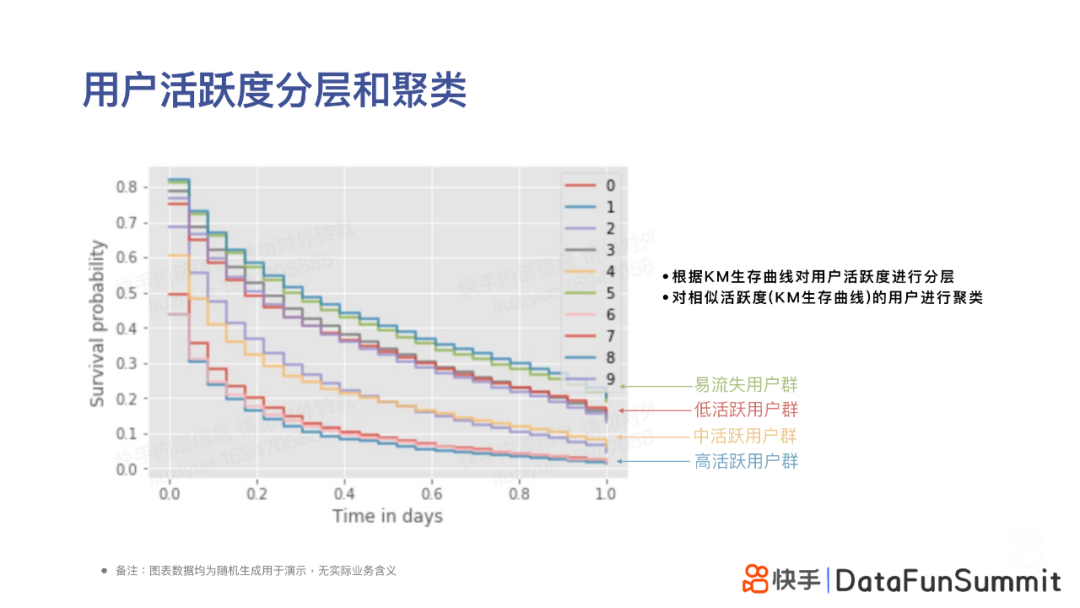
第一个业务应用案例,是基于KM生存曲线对用户活跃度进行分层,对相似活跃度(KM生存曲线)的用户进行聚类。以下图为例,DS对9条生存曲线进行合并和聚类,最终划分为4类用户群。针对不同的具有相同特质的群体,业务部门将更有策略去制定相应的产品运营策略。在用户活跃度分析中,前文提到的传统的聚类特征(包括人口属性特征、消费者偏好特征、时长统计特征等)包含的信息量不够多,而基于用户行为模式的聚类能够更加精细地、生动地刻画和还原用户与产品间的交互。
2. 利用生存曲线进行防流失干预
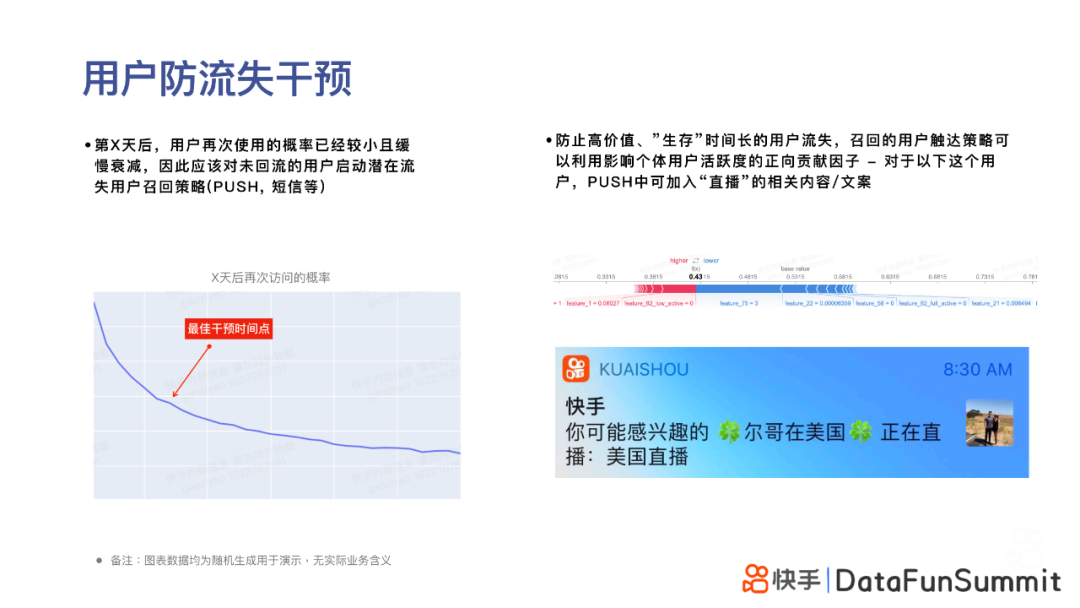
第二个业务应用案例是利用生存曲线做用户的防流失干预。左图是某群用户的生存曲线;可以明显看到,在第X天,生存曲线有一个明显的拐点 - 这表明在该时间点后,当用户再次使用产品的概率较小且呈现缓慢衰减时,最佳流失预警干预时机其实就是这个时间点。如果对该用户进行一些有效的防流失干预(如PUSH、短信等潜在流失⽤户召回策略),我们是有可能bend the curve的。
生存分析除了可预测最佳的防止用户流失干预点,还对具体的防流失干预方式(即召回的⽤户触达策略)提供了充分的信息。例如基于前文提到的SHAPLEY VALUES的LOCAL INTERPRETATION,可以找出影响该用户的活跃度的正向贡献因⼦等。例如,对于某用户,“是否看直播”这一特征对于用户活跃度是一个非常大的正向贡献因子,那么在PUSH中可加⼊“直播”的相关内容或⽂案,将用户感兴趣的直播内容推送给他,可大大提升用户的点击PUSH的ctr,从而加大用户重回快手APP消费的概率。
3. 推荐策略的优化
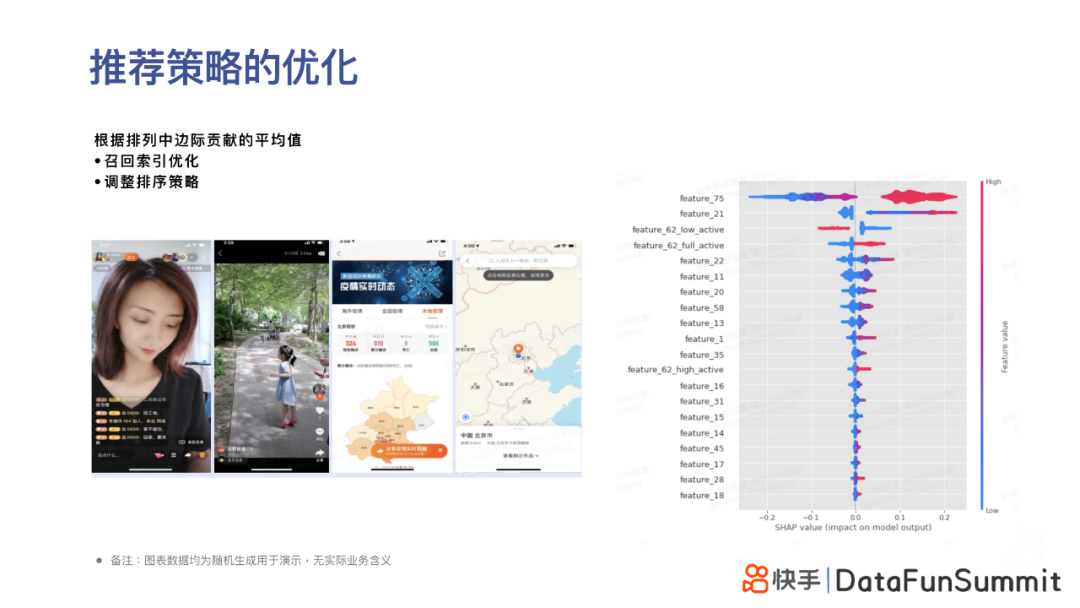
最后分享的业务应用案例是推荐策略的优化。这个应用也和前文提到的SHAPLEY VALUE相关。我们可以根据各特征边际贡献的平均值排序,有针对性地调整召回和索引的相关策略,并优化推荐模型在粗排或者精排阶段的不同特征的权重。
1. KwaiSurvival简介
本部分将重点分享和介绍快手自主开发的基于深度学习的生存分析模型——KwaiSurvival。KwaiSurvival 是快⼿DA⾃主开发的基于深度学习框架的集成⽣存分析软件,帮助使⽤者在Python编程环境下⾼效地使⽤⽣存分析模型实现⼤规模的数据分析。
2. KwaiSurvival的软件功能
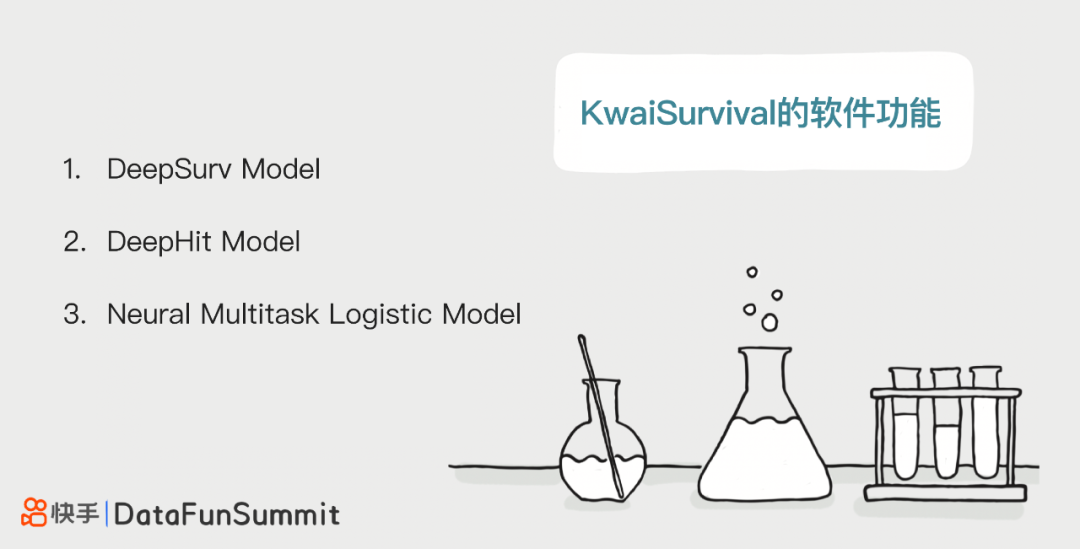
KwaiSurvival目前集成了3种基于深度学习模型框架的生存模型。分别是DeepSurv Model ;DeepHit Model ;Neural Muyltitask Logistic Model。对于这3个模型框架,在此对相关的参考文献做简要介绍,供参考:
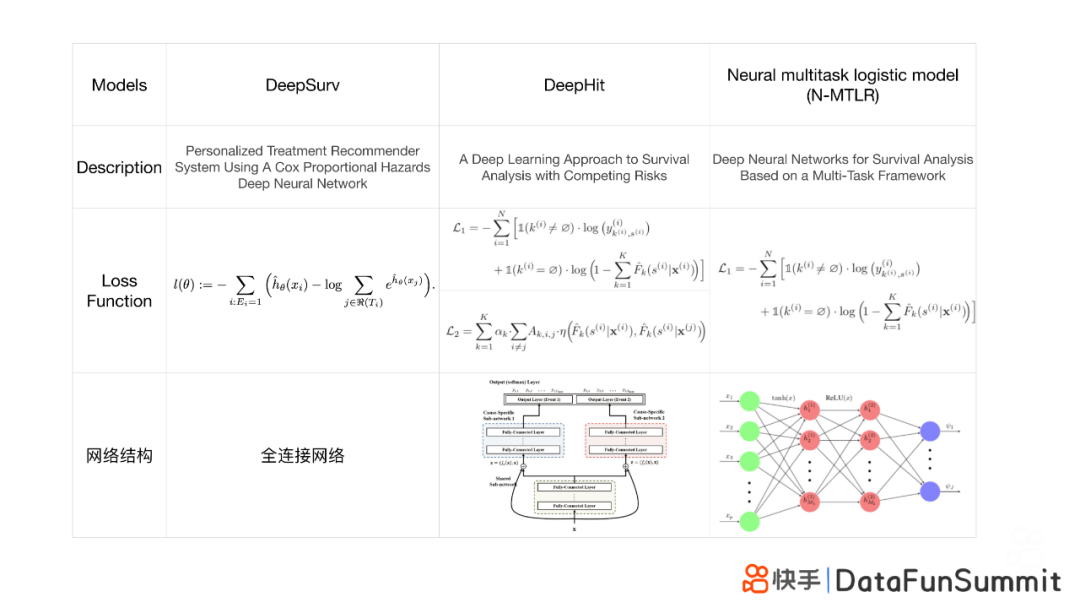
① DeepSurv Model
DeepSurv模型是基于Cox回归模型的神经网络版本,其损失函数定义和Cox模型相似,都是负对数似然函数。主要区别在于,DeepSurv模型将风险函数非线性化,采用全连接网络进行多层感知,进而对风险函数进行预估。
② Neural Multitask Logistic Model(N-MTLR)
N-MTLR模型是DeepSurv模型的改进版,主要对网络结构和损失函数做了一系列改进。经过多层网络连接,最终通过softmax输出事件在时间s上发生的概率(即风险函数),进而求得生存函数。
③ DeepHit Model
DeepHit模型是基于N-MTLR模型做的进一步改进,仍然是对网络结构和损失函数进行的调整。基于N-MTLR模型,通过softmax输出事件发生的概率之后,特别采用了ResNet结构,在share层结束后可再次输入信息。该模型的损失函数包括两个:一个是类似Cox模型的负对数似然函数,另一个是类似于前文所述CONCORDANCE的rank loss。基于这两个损失函数,可大幅提升模型的一致性效果。
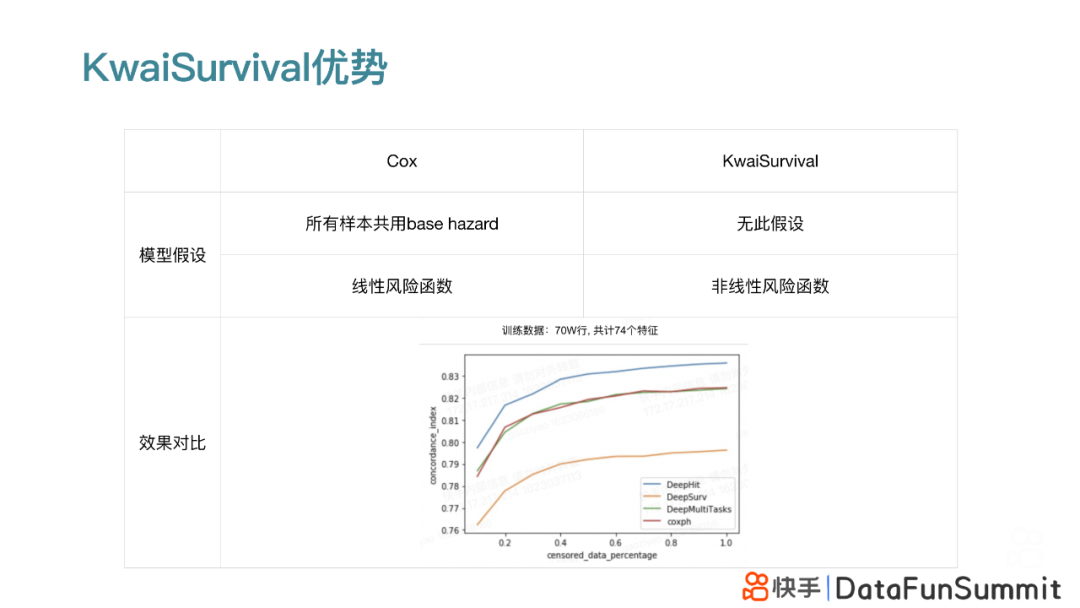
3. KwaiSurvival的优势
为了对比传统Cox模型和KwaiSurvival的模型表现,我们使用包含74个特征共计70W条数据作为训练数据进行测试,可以明显看出:
① KwaiSurvival包含的3种模型的训练效果都比较良好,其中DeepHit的模型表现比传统的Cox模型要更加优异;
② 在KwaiSurvival包含的3种模型中,DeepHit的模型表现也显著优于另外两种模型。
③ 从模型计算时间角度看,这几种模型的计算时间接近。
下表简单地汇总了传统Cox模型和KwaiSurvival模型之间的优劣势:
目前我们已经将KwaiSurvival的几个基础模型上传分享到GitHub,欢迎对生存分析感兴趣的同学能够把其他的生存分析框架、模型进行上传和整合。我们的模型还在初期迭代阶段,希望大家多给我们提宝贵的意见,谢谢。
GitHub地址:
https://github.com/kwaiDA/KwaiSurvival/tree/kwaiDA-liuziyue

推荐阅读
欢迎长按扫码关注「数据管道」