
用 Python 分析领导讲话,原来隐藏了 "这些" 重要信息......
这是「进击的Coder」的第 486 篇技术分享作者:黄伟呢来源:快学 Python“
阅读本文大概需要 8 分钟。
如何用 Python 分析领导讲话呢?正好庆祝中国共产党成立 100 周年大会,7 月 1 日上午在北京天安门广场隆重举行。中共中央总书记、国家主席、中央军委主席习近平发表重要讲话。
这段讲话,共 14 页 word 排版,7297 个字。你全程观看了直播吗?关于这场重要讲话,习总书记主要传达了那些精神,你知道吗?今天我就带着大家来学习一下本次大会的精神。大家可以学习后用来分析自己的领导讲话哦~ 这段话的 word 版本,是我无意中在某个微信群里面发现的,是以
这段话的 word 版本,是我无意中在某个微信群里面发现的,是以.doc结束老版本的 word 文档格式,截个图给大家看看: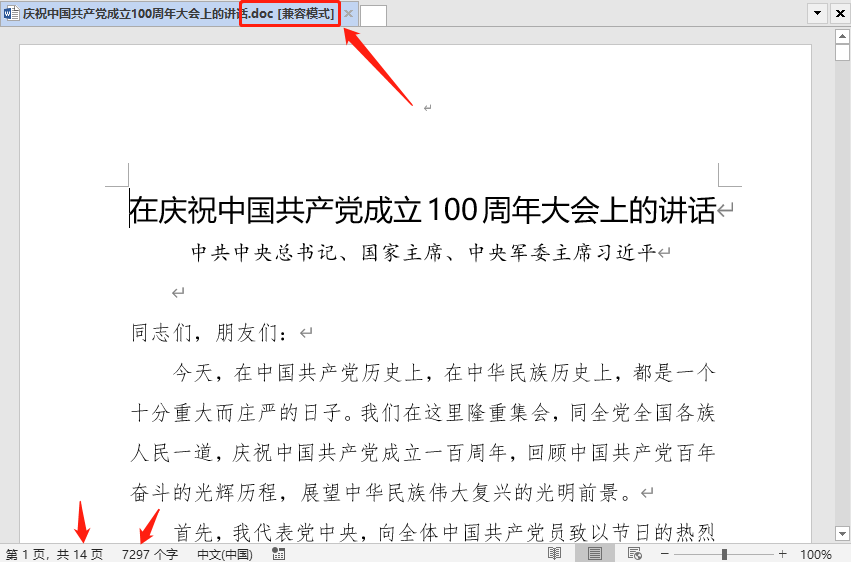 我们今天的任务就是:读取这段文字,对文字做一个关键词统计,看看这次大会主要传达了哪些重要精神。当然,这篇文章一共涉及到如下三方面重要的知识,分别是:
我们今天的任务就是:读取这段文字,对文字做一个关键词统计,看看这次大会主要传达了哪些重要精神。当然,这篇文章一共涉及到如下三方面重要的知识,分别是:- ① doc 文章格式转换为 docx 格式;
- ② Python 自动化操作 word 文档相关操作;
- ③ jieba 中文分词库的应用;
PS:不要单纯只学习某个知识点,带着应用学习;
1. doc 文档格式转 docx 格式
后面读取 word 文档中的文字,会用到一个叫做python-docx的库,它只能读取.docx格式的 word 文档。但是你不要企图,直接修改文档后缀,那样的话,你打开文档,会提示格式错误。因此,在正式获取 word 文档中的内容之前,必须要进行一下格式转换。import os结果如下:
import time
import win32com
from win32com.client import Dispatch
def doc_to_docx(path):
w = win32com.client.Dispatch('Word.Application')
w.Visible = 0
w.DisplayAlerts = 0
doc = w.Documents.Open(path)
# 这里必须要绝对地址,保持和doc路径一致
newpath = allpath+'\\转换后的文档_庆祝中国共产党成立100周年大会上的讲话.docx'
time.sleep(3) # 暂停3s,否则会出现-2147352567,错误
doc.SaveAs(newpath,12,False,"",True,"",False,False,False,False)
# doc.Close() 开启则会删掉原来的doc
w.Quit()# 退出
return newpath
allpath = os.getcwd()
print(allpath)
doc_to_docx(allpath+'\\庆祝中国共产党成立100周年大会上的讲话.doc')
 下面两行代码的意思,了解就行。
下面两行代码的意思,了解就行。# 调用word程序
WordApp = win32com.client.Dispatch("Word.Application")
# 后台运行,不显示,不警告
WordApp.Visible = 0
WordApp.DisplayAlerts = 0
2. python-docx 读取 word 文档内容
在使用 Python 读取 word 文档内容之前,我们首先需要对 word 文档结构有一个清楚的认识,在没有图表的情况写,word 文档主要由文档 - 段落 - 文字块三部分构成。 读取 word 文档内容的大致思路是这样的:
读取 word 文档内容的大致思路是这样的:- ① 获取 word 文档,就是得到一个 Document 对象;
- ② 调用 Document 对象的 paragraphs 方法,获取 Paragraph 段落对象列表;
- ③ 循环遍历段落对象列表,调用 text 方法,获取每个段落中的整段文字;
from docx import Document部分截图如下:
doc = Document(r"转换后的文档_庆祝中国共产党成立100周年大会上的讲话.docx")
text = ""
for parapraph in doc.paragraphs:
text += parapraph.text
 这里定义了一个字符串 text,将读取到的内容,拼接成一个字符串,是为了方便我们后续使用
这里定义了一个字符串 text,将读取到的内容,拼接成一个字符串,是为了方便我们后续使用jieba库进行分词操作。3. jieba中文分词库的应用
前面我们将word文档中所有的内容,全部转换为一个超长的字符串了,接下来就是应用jieba库,进行中文分词,做一个词频统计。下面直接一步步带着大家做吧!
① 导入相关库
在这里,你需要什么库,就导入什么库。import jieba
from wordcloud import WordCloud
import pandas as pd
import matplotlib.pyplot as plt
from imageio import imread
import warnings
warnings.filterwarnings("ignore")
② 使用 jieba 库中的 lcut() 方法进行分词
短短的一行代码,很简单。text_list = list(jieba.cut(text))在进行分词之前,我们可以
动态修改词典,让某些特定词语不被强制性分开。我这里介绍一下,大家下去自己学习。- jieba.add_word() 方法,只能一个个动态添加词语;
- 假如我们需要动态添加多个词语的时候,就需要使用 jieba.load_userdict() 方法。也就是说:将所有的自定义词语,放到一个文本中,然后使用该方法,一次性动态修改词典集;
③ 读取停用词,添加额外停用词,并去除停用词
读取停用词,采用 split() 函数切分后,会得到一个停用词列表。接着,采用+号将额外停用词,添加到列表中即可。with open(r"stoplist.txt",encoding="utf-8") as f:
stop = f.read()
stop = stop.split()
stop = [" "] + stop
final_text = [i for i in text_list if i not in stop]
④ 词频统计
这里使用Pandas库中 series 序列的 value_counts() 函数,进行词频统计。word_count = pd.Series(final_text).value_counts()[:30]部分截图 如下:
⑤ 词云图的绘制
# 1、读取背景图片结果如下:
back_picture = imread(r"aixin.jpg")
# 2、设置词云参数:这些参数,大家看英文单词的含义,应该可以猜出来!
wc = WordCloud(font_path="simhei.ttf",
background_color="white",
max_words=2000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
# 3、绘制词云图
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
 仔细观察词云图,相信很多有过考研经历的同学,应该都能背诵出,那一段很长的话。
仔细观察词云图,相信很多有过考研经历的同学,应该都能背诵出,那一段很长的话。好了,本文就讲述到这里,关于文中三个重要的知识点,你都学会了吗?

End
「进击的Coder」专属学习群已正式成立,搜索「CQCcqc4」添加崔庆才的个人微信或者扫描下方二维码拉您入群交流学习。
及时收看更多好文
↓↓↓
崔庆才的「进击的Coder」知识星球已正式成立,感兴趣的可以查看《我创办了一个知识星球》了解更多内容,欢迎您的加入:
评论