
我用 Python 分析了一波热卖年货,原来大家都在买这些东西?

源 / 杰哥的IT之旅 文 / Cherich_sun
今年不知道有多少小伙伴留在原地过年,虽然今年过年不能回老家,但这个年也得过,也得买年货,给家人长辈送礼。于是我出于好奇心的想法利用爬虫获取某宝数据,并结合 Python 数据分析和第三方可视化平台来分析一下大家过年都买了哪些东西,分析结果大屏如下:
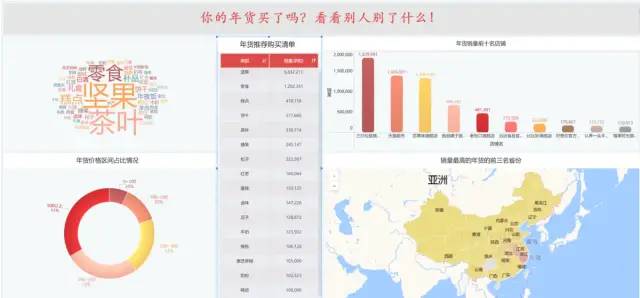
上面使用清洗好的数据后用 finebi 第三方可视化工具完成的。接下来是用 Python 的实现过程,对于本文的叙述,主要分为以下五步:
分析思路
爬虫部分
数据清洗
数据可视化及分析
结论与建议

1. 分析思路
其实就今天的数据来讲,我们主要做的是探索性分析;首先梳理已有的字段,有标题(提取出品类)、价格、销量、店铺名、发货地。下面来做一下详细的维度拆分以及可视化图形选择:
品类:
品类销量的 TOP 10 有哪些?(表格或者横向条形图)
热门(出现次数最多)品类展示;(词云)
价格:年货的价格区间分布情况;(圆环图,观察占比)
销量、店铺名:
店铺销量最高的 TOP 10 有哪些?(条形图)
结合品类做联动,比如点坚果,对应展示销量排名的店铺;(联动,利用三方工具)
发货地:销量最高的城市有哪些?(地图)
2. 爬取数据
爬取主要利用 selenium 模拟点击浏览器,前提是已经安装 selenium 和浏览器驱动,这里我是用的 Google 浏览器,找到对应的版本号后并下载对应的版本驱动,一定要对应浏览器的版本号。
pip install selenium
安装成功后,运行如下代码,输入关键字"年货",进行扫码就可以了,等着程序慢慢采集。
# coding=utf8
import re
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
import csv
# 搜索商品,获取商品页码
def search_product(key_word):
# 定位输入框
browser.find_element_by_id("q").send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element_by_class_name('btn-search').click()
# 最大化窗口:为了方便我们扫码
browser.maximize_window()
# 等待15秒,给足时间我们扫码
time.sleep(15)
# 定位这个“页码”,获取“共100页这个文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。
page = re.findall("(\d+)", page_info)[0]
return page
# 获取数据
def get_data():
# 通过页面分析发现:所有的信息都在items节点下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 参数信息
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 价格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人数
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 旗舰店
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 发货地
address = item.find_element_by_xpath('.//div[@class="location"]').text
# print(pro_desc, pro_price, buy_num, shop, address)
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("*" * 100)
print("正在爬取第{}页".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num * 44))
browser.implicitly_wait(25)
get_data()
page_num += 1
print("数据爬取完毕!")
if __name__ == '__main__':
key_word = input("请输入你要搜索的商品:")
option = Options()
browser = webdriver.Chrome(chrome_options=option,
executable_path=r"C:\Users\cherich\AppData\Local\Google\Chrome\Application\chromedriver.exe")
main()
采集结果如下:

数据准备完成,中间从标题里提取类别过程比较耗时,建议大家直接用整理好的数据。
大概思路是对标题进行分词,命名实体识别,标记出名词,找出类别名称,比如坚果、茶叶等。
3. 数据清洗
这里的文件清洗几乎用 Excel 搞定,数据集小,用 Excel 效率很高,比如这里做了一个价格区间。到现在数据清洗已经完成(可以用三方工具做可视化了),如果大家爱折腾,可以接着往下看用 Python 如何进行分析。
4. 可视化分析
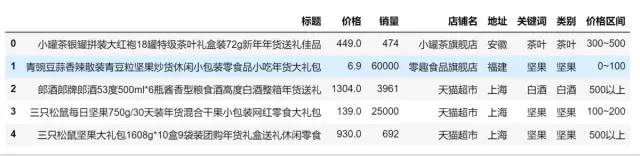
1、读取文件
import pandas as pd
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
from wordcloud import WordCloud
from ast import literal_eval
import matplotlib.pyplot as plt
datas = pd.read_csv('./年货.csv',encoding='gbk')
datas
2、可视化:词云图
li = []
for each in datas['关键词'].values:
new_list = str(each).split(',')
li.extend(new_list)
def func_pd(words):
count_result = pd.Series(words).value_counts()
return count_result.to_dict()
frequencies = func_pd(li)
frequencies.pop('其他')
plt.figure(figsize = (10,4),dpi=80)
wordcloud = WordCloud(font_path="STSONG.TTF",background_color='white', width=700,height=350).fit_words(frequencies)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

图表说明:我们可以看到词云图,热门(出现次数最多)品类字体最大,依次是:坚果、茶叶、糕点等。
3、可视化:绘制圆环图
# plt.pie(x,lables,autopct,shadow,startangle,colors,explode)
food_type = datas.groupby('价格区间').size()
plt.figure(figsize=(8,4),dpi=80)
explodes= [0,0,0,0,0.2,0.1]
size = 0.3
plt.pie(food_type, radius=1,labels=food_type.index, autopct='%.2f%%', colors=['#F4A460','#D2691E','#CDCD00','#FFD700','#EEE5DE'],
wedgeprops=dict(width=size, edgecolor='w'))
plt.title('年货价格区间占比情况',fontsize=18)
plt.legend(food_type.index,bbox_to_anchor=(1.5, 1.0))
plt.show()
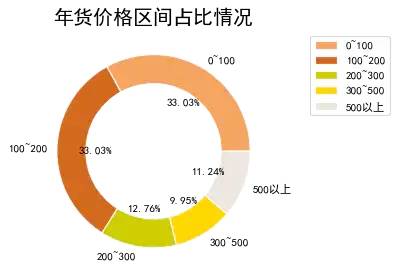
图表说明:圆环图和饼图类似,代表部分相对于整体的占比情况,可以看到0 ~ 200元的年货大概33%左右,100 ~ 200元也是33%。说明大部分的年货的价格趋于200以内。
4、可视化:绘制条形图
data = datas.groupby(by='店铺名')['销量'].sum().sort_values(ascending=False).head(10)
plt.figure(figsize = (10,4),dpi=80)
plt.ylabel('销量')
plt.title('年货销量前十名店铺',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.bar(data.index,data.values, color=colors)
plt.xticks(rotation=45)
plt.show()
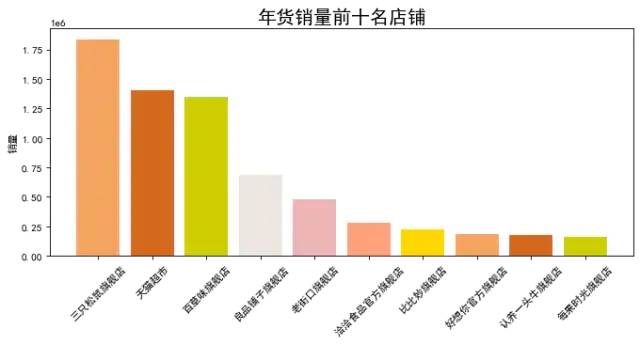
图表说明:以上是店铺按销量排名情况,可以看到第一名是三只松鼠旗舰店,看来过年大家都喜欢吃干货。
5、可视化:绘制横向条形图
foods = datas.groupby(by='类别')['销量'].sum().sort_values(ascending=False).head(10)
foods.sort_values(ascending=True,inplace=True)
plt.figure(figsize = (10,4),dpi=80)
plt.xlabel('销量')
plt.title('年货推荐购买排行榜',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#CD96CD','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.barh(foods.index,foods.values, color=colors,height=1)
plt.show()
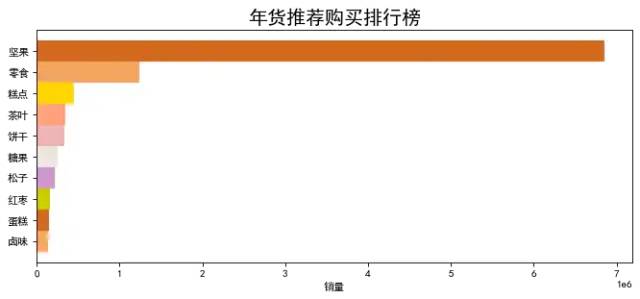
图表说明:根据类别销量排名,排名第一是坚果,验证了上面的假设,大家喜欢吃坚果。
5.结论与建议
淘宝热卖年货: 坚果,茶叶,糕点,饼干,糖果,白酒,核桃,羊肉,海参,枸杞;
年货推荐清单(按销量):坚果、零食、糕点、饼干、茶叶、糖果、松子、红枣、蛋糕、卤味、瓜子、牛奶、核桃;
年货价格参考:66%以上的年货价格在0~200元之间;
热门店铺:三只老鼠、天猫超市、百草味、良品铺子;
— 完 —
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~