本文约1700字,建议阅读5分钟
mask-and-predict 的方法可能会成为计算机视觉领域的新流派。
自监督预训练在自然语言处理方面取得了惊人的成功,其基本思路中包含着掩码预测任务。前段时间,何恺明一作的论文《Masked Autoencoders Are Scalable Vision Learners》提出了一种简单实用的自监督学习方案 MAE,将 NLP 领域的掩码预测(mask-and-predict)方法用在了视觉问题上。现在来自 Facebook AI 研究院(FAIR)的研究团队又提出了一种自监督视觉预训练新方法 MaskFeat。
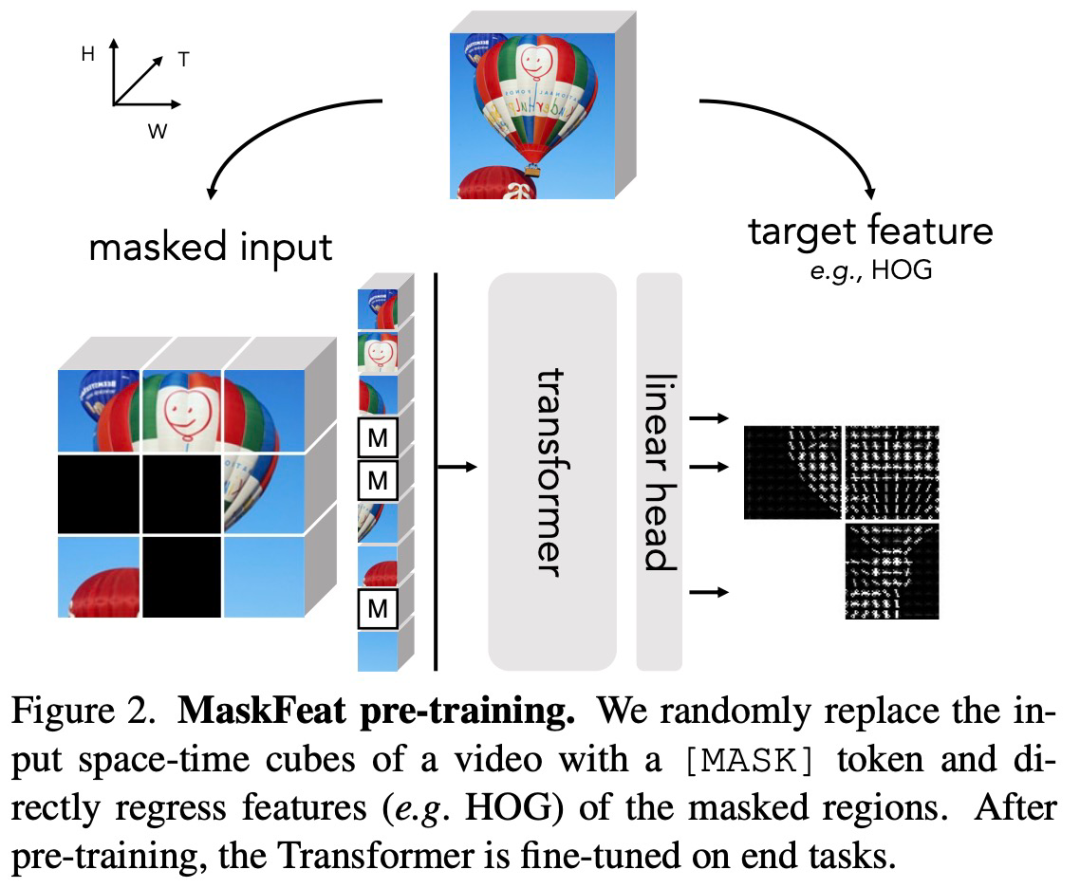
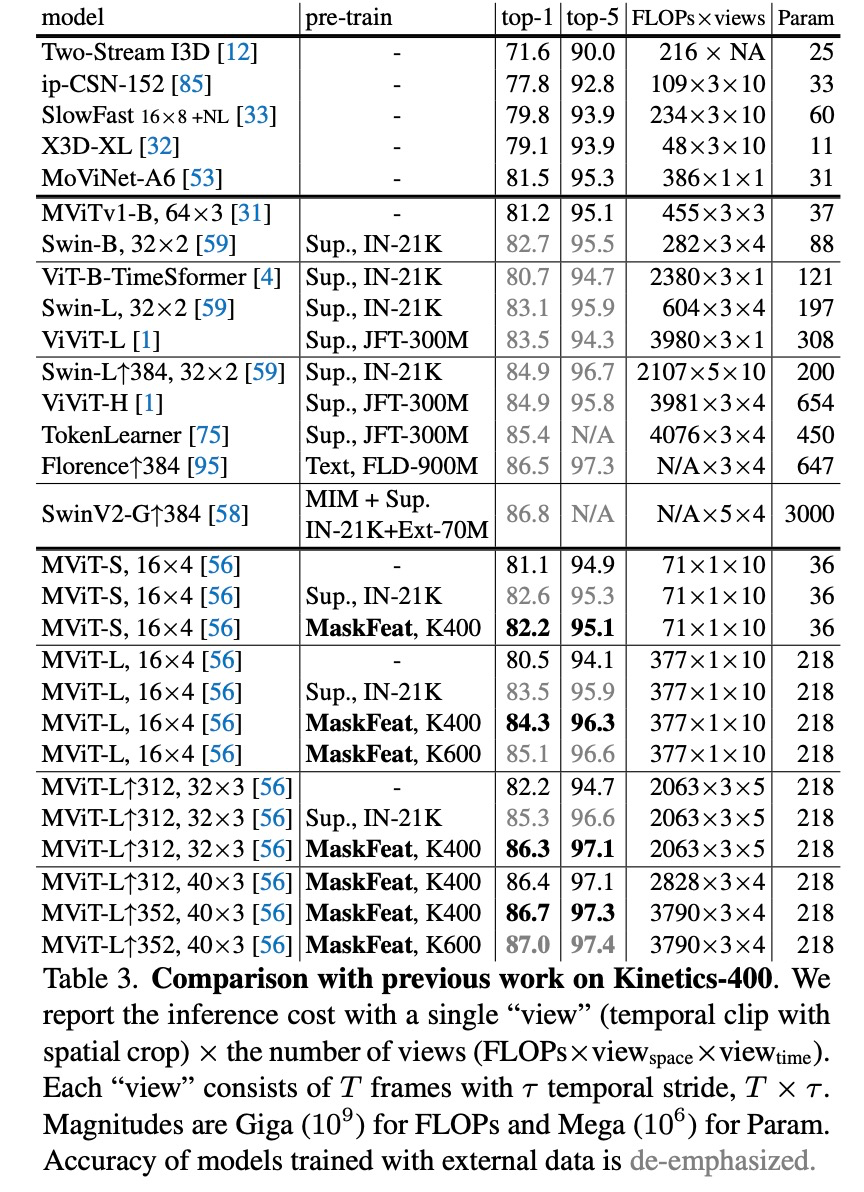
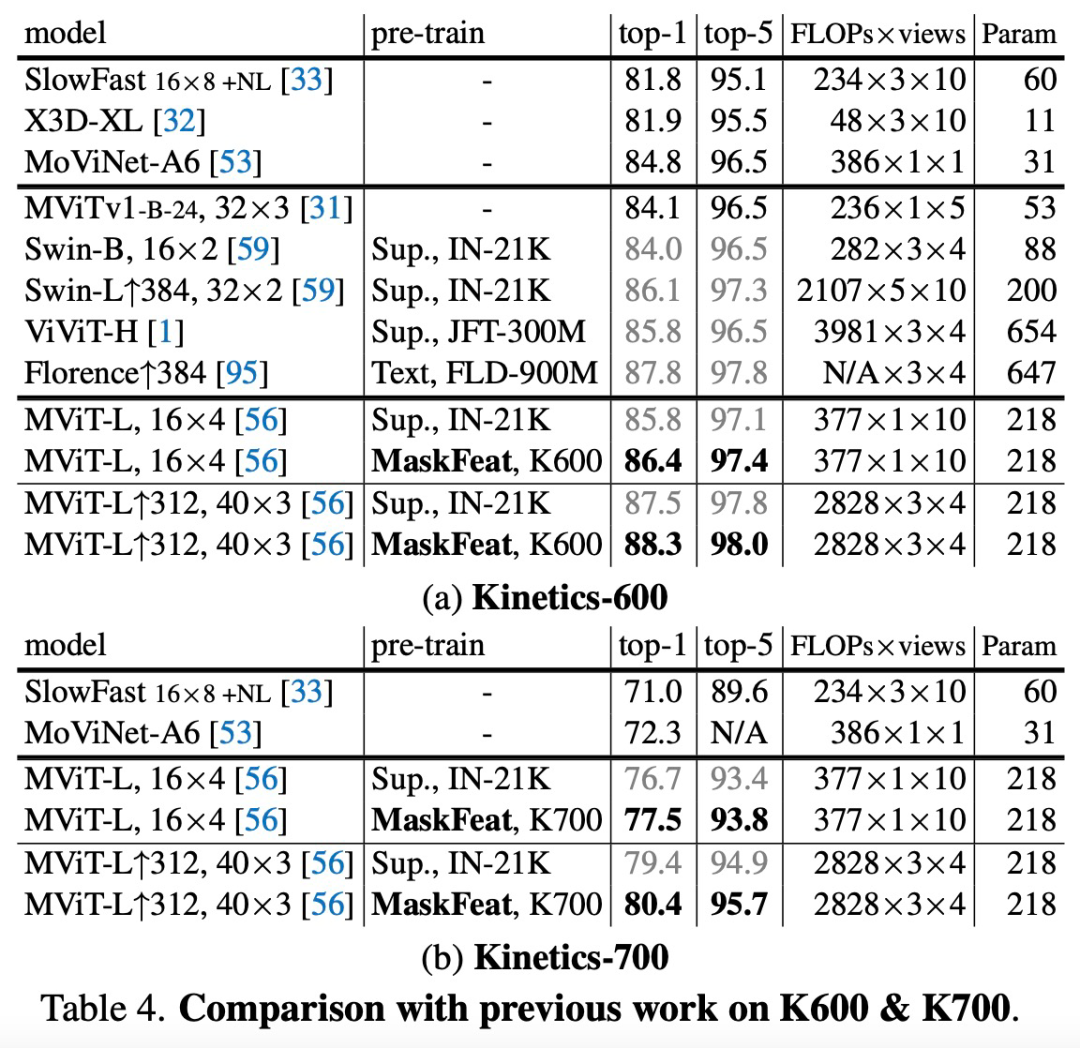
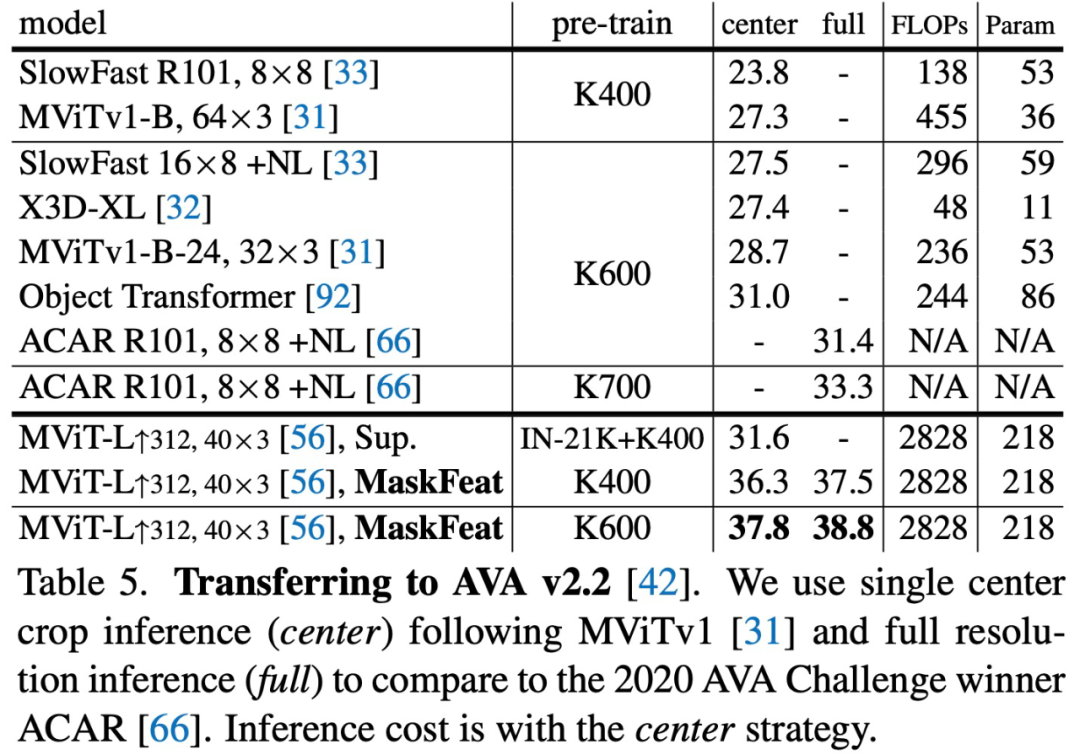
论文地址:https://arxiv.org/pdf/2112.09133.pdfMaskFeat 首先随机掩码一部分输入序列,然后预测被掩码区域的特征。通过研究 5 种不同类型的特征,研究者发现方向梯度直方图 (HOG) 是一种很好的特征描述方法,在性能和效率方面都表现优异。并且研究者还观察到 HOG 中的局部对比归一化对于获得良好结果至关重要,这与之前使用 HOG 进行视觉识别的工作一致。该方法可以学习丰富的视觉知识并驱动基于 Transformer 的大规模模型。在不使用额外的模型权重和监督的情况下,MaskFeat 在未标记的视频上进行预训练,使用 MViT-L 在 Kinetics-400 上实现了前所未有的 86.7% top-1 准确率。此外,MaskFeat 还能进一步推广到图像输入,并在 ImageNet 上获得了有竞争力的结果。掩码视觉预测任务旨在修复被掩码的视觉内容。通过建模掩码样本,该模型从识别物体的部位和运动的意义上实现了视频理解。例如,要补全下图中的图像,模型必须首先根据可见区域识别对象,还要知道对象通常的形态和移动方式,以修复缺失区域。该任务的一个关键组成部分是预测目标。在自然语言处理任务中,掩码语言建模使用词表 tokenize 语料库作为目标。而在视觉领域,原始视觉信号是连续的、高维的,并且没有可用的自然「词表」。因此,MaskFeat 提出将预测被掩码区域的特征。借助从原始完整样本中提取的特征进行监督。目标特征的选择在很大程度上影响了预训练模型的属性,该研究对特征进行了广泛的解释,并主要考虑了 5 种不同类型的目标特征。首先研究者将目标特征分为两组:1) 可以直接获得的单阶段目标,包括像素颜色和 HOG;2) 由经过训练的深度网络提取的两阶段目标。由于预测两阶段目标是借助训练有素的深度网络有效学得的(类似于模型蒸馏),因此教师模型的预训练和推理的额外计算成本是不可避免的。该研究主要探究的 5 种特征类型是:该研究通过了一系列的分析探究了这 5 种特征的利弊。尽管掩码语言建模最初是在预定义词表上预测分类分布,但 BEiT 中的离散化不需要视觉信息。分析结果表明,连续的无监督特征和图像描述符是性能较好的预测目标,其中前者需要模型蒸馏,后者则不需要额外的计算开销。此外,研究者还发现监督训练的目标特征会产生较差的结果,这可能与存在于特征中的类级特定信息有关,即这种方法对于局部掩码建模来说过于全局化。总的来说,考虑性能和计算成本之间的权衡,该研究最终选择了 HOG 作为 MaskFeat 的默认特征。方向梯度直方图(HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述方法,最早是在 CVPR 2005 的一篇论文《Histograms of Oriented Gradients for Human Detection》中提出的。HOG 特征提取的过程如下:首先把样本图像分割为若干个像素单元,把梯度方向平均划分为多个区间,在每个单元里面对所有像素的梯度方向在各个方向区间进行直方图统计,得到一个多维的特征向量,每相邻的单元构成一个区间,把一个区间内的特征向量联起来得到多维的特征向量,用区间对样本图像进行扫描,扫描步长为一个单元。最后将所有块的特征串联起来,就得到了完整的特征。该研究在 K400 数据集上将 MaskFeat 和之前的工作进行了比较,结果如下表 3 所示,使用 MaskFeat 的 MViT-L 在 Kinetics-400 上实现了新的 SOTA——86.7% top-1 准确率。为了评估该方法在下游任务上的迁移学习性能,该研究在 AVA v2.2 上微调了 MViT-L↑312,40×3 Kinetics 模型,实验结果如上表 3 和下表 4 所示,在 K600 上实现了 88.3% top-1 准确率,K700 上为 80.4%,均实现了新的 SOTA。该研究在 AVA v2.2 上微调了 MViT-L↑312,40×3 Kinetics 模型,下表 5 给出了 MaskFeat 模型与现有方法相比的平均精度 (mAP)。MaskFeat 在全分辨率测试中达到了前所未有的 38.8 mAP,大大超过了以前所有方法。