
盘点4种方法处理42w行数据精确的提取到其中的年度信息
回复“ 书籍 ”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
早岁那知世事艰,中原北望气如山。大家好,我是Python进阶者。
一、前言
前几天在Python最强王者交流群【金光灿灿】问了一个Pandas处理字符串数据的问题。问题如下:亲们问个问题:现在有1列数据,约42w行,字段名为PatientID,字段内长度不一,经统计共有下列5种,示例如下,问,我该如何精确的提取到其中的年度信息。

二、实现过程
方法一
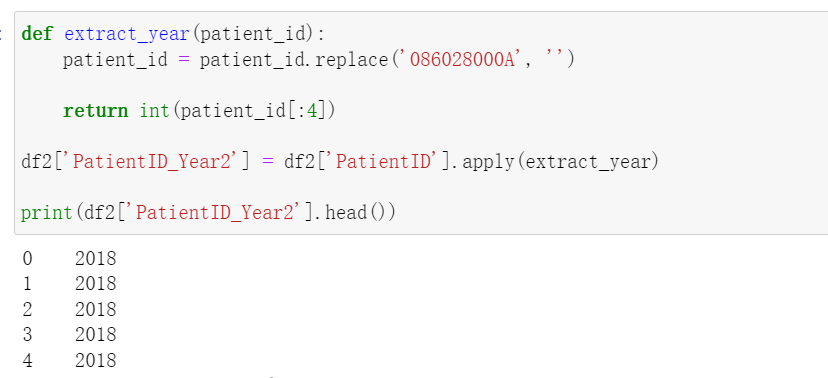
这里【吴超建】给了一个思路:086028000A 替换成'',截取前 4 位即是年份。代码如下所示:
方法二
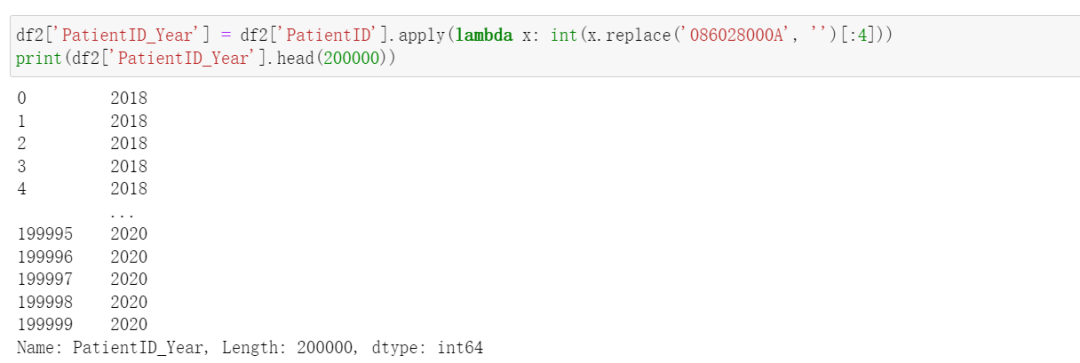
后来【FiNε_】也给了一个思路:不用定义 一行代码能否搞定。答案是肯定的,代码如下所示:
方法三
【猫药师Kelly】看完数据之后,也给了一个思路:按照字母split一下,取前4位就是年份了。代码如下所示:

方法四
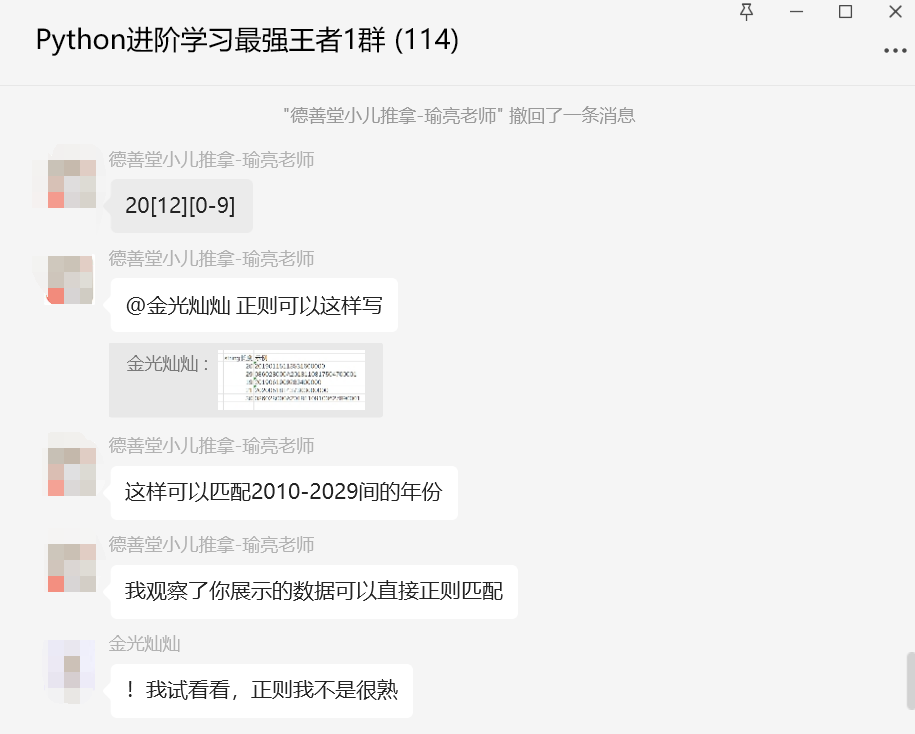
【瑜亮老师】这里还提出了正则表达式的解决办法,如下所示:
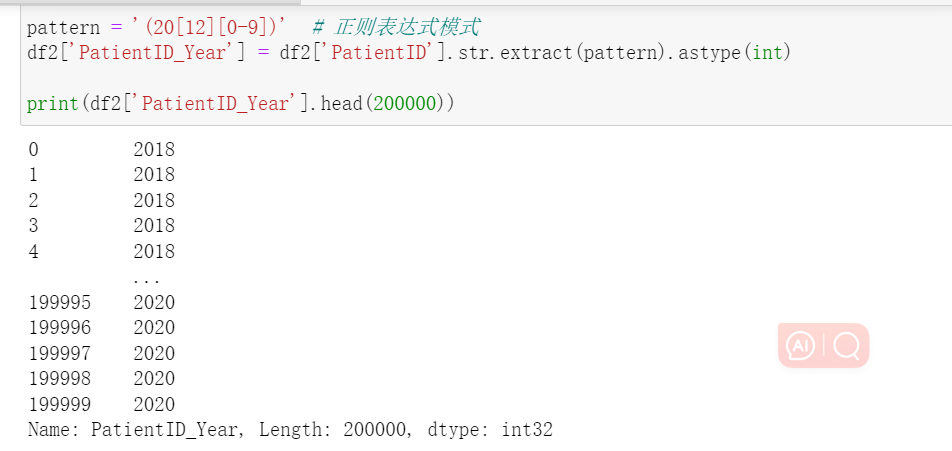
代码写完后如下所示:
思路一下子就打开了,4种方法,任君挑选!
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python库安装的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【金光灿灿】提出的问题,感谢【FiNε_】、【猫药师Kelly】、【wen】、【吴超建】、【瑜亮老师】给出的思路,感谢【莫生气】、【黑科技·鼓包】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(Python进阶者微信:2584914241),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【 入群 】
万水千山总是情,点个【 在看 】行不行
/今日留言主题/
随便说一两句吧~~