
实操教程|详细记录solov2的ncnn实现和优化
极市导读
由于目前solo系列在GitHub中没有转ncnn的项目,作者详细记录了自己solov2的ncnn实现以及后处理后处理优化的一些策略,给需要的人一点借鉴。附有代码地址。
SOLOV2简介
solo大家都知道,核心思想是:将分割问题转化为位置分类问题,从而做到不需要anchor,不需要normalization,不需要bounding box detections的实例分割。
https://github.com/Epiphqny/SOLOv2
缘由
目前solo系列在github中没有转ncnn的项目
solov2的思想比较简单明了,但是转ncnn还是需要很多比较复杂操作,想在用ncnn实现更加了解solov2内部的算法流程,也熟悉ncnn的一些其他op操作
文字有很多干货:param手动修改、动态op、加速技巧等等
1 、torch导出onnx
在导出onnx之前有几部操作:
修改split_feats: onnx不支持F.interpolate() 中 scale_factor < 1 ;因此对split_feats做了修改为nn.Maxpool 卷积,后面转ncnn手动修改;
def split_feats(self, feats):return [self.maxpool(feats[0]),# F.interpolate(feats[0],scale_factor=0.5,mode='bilinear'),feats[1],feats[2],feats[3],F.interpolate(feats[4], size=feats[3].shape[-2:], mode='bilinear')]
添加输入参数:
添加onnx参数,金生coord改为手动输入
def forward(self, feats, eval=False,onnx=False):if onnx:feats,p3_input,p4_input,p5_input = featsnew_feats = self.split_feats(feats)featmap_sizes = [featmap.size()[-2:] for featmap in new_feats]if onnx:new_feats[0] = [new_feats[0],p3_input]new_feats[1] = [new_feats[1],p3_input]new_feats[2] = [new_feats[2],p4_input]new_feats[3] = [new_feats[3],p5_input]new_feats[4] = [new_feats[4],p5_input]
实现转换代码
实现转换代码,并onnxsim优化,这里需要注意的是输入尽量小一点,因为solo的四个输出头的size比较小(40,36,24,16,12),输入较大时会使F.interpolate() 中 scale_factor < 1 ,input_size = 256时fpn最后一层上采样的scale_factor刚好可以等于2(256%64=0)
from torch import nnimport torchfrom mmcv import Configfrom mmdet.models.builder import build_backbone,build_head,build_neckclass SOLOV2(nn.Module):def __init__(self,confg):super(SOLOV2,self).__init__()self.cfg = Config.fromfile(confg)self.cfg = self.cfg["model"]self.backbone = build_backbone(self.cfg["backbone"])self.neck = build_neck(self.cfg["neck"])self.bbox_head = build_head(self.cfg["bbox_head"])def forward(self,x,p3_input,p4_input,p5_input):x = self.backbone(x)x = self.neck(x)feature_pred,kernel_pred,cate_pred = self.bbox_head([x,p3_input,p4_input,p5_input],eval=True,onnx=True)return feature_pred,kernel_pred,cate_predcfg = "./configs/solov2/solov2_r101_3x.py"pretrained = "./weights/solov2.pth"#net = SOLOV2(cfg)state_dict = torch.load(pretrained, map_location=lambda storage, loc: storage)["state_dict"]res = net.load_state_dict(state_dict,strict=False)net.eval()input_size = 256dummy_input1 = torch.randn(1, 3, input_size, input_size)dummy_input2 = torch.randn(1, 2, input_size//8, input_size//8)dummy_input3 = torch.randn(1, 2, input_size//16, input_size//16)dummy_input4 = torch.randn(1, 2, input_size//32, input_size//32)input_names = ["input","p3_input","p4_input","p5_input"]output_names = ["feature_pred","kernel_pred1","kernel_pred2","kernel_pred3","kernel_pred4","kernel_pred5","cate_pred1","cate_pred2","cate_pred3","cate_pred4","cate_pred5" ]save_name = "./onnx/solov2.onnx"# torch.onnx.export(model, (dummy_input1, dummy_input2, dummy_input3), "C3AE.onnx", verbose=True, input_names=input_names, output_names=output_names)torch.onnx.export(net, (dummy_input1,dummy_input2,dummy_input3,dummy_input4),save_name , verbose=False, input_names=input_names,output_names=output_names)import osos.system("python -m onnxsim {0} {0}".format(save_name))
2、onnx转ncnn
onnx2ncnn
./onnx2ncnn solov2.onnx solov2.param solov2.bin
ncnn 参数手工优化
将之前转onnx时的maxpool改为上采样操作:

改为

2、将所有的kernel_pred和cate_pred之前的Interp参数改为对用的w和h:
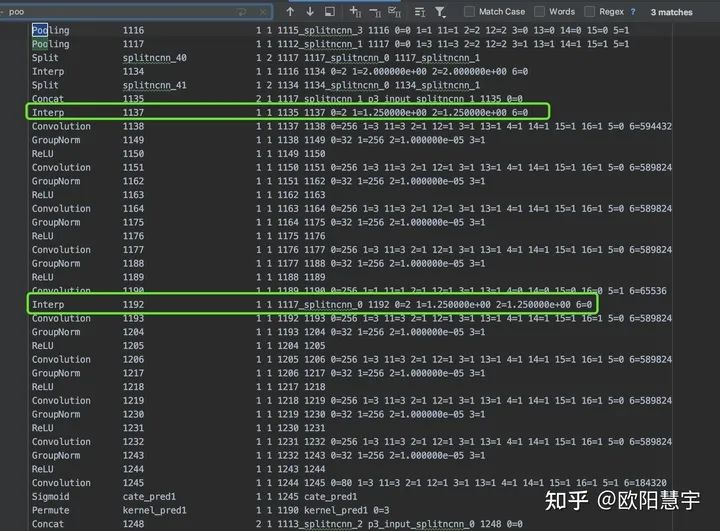
改为
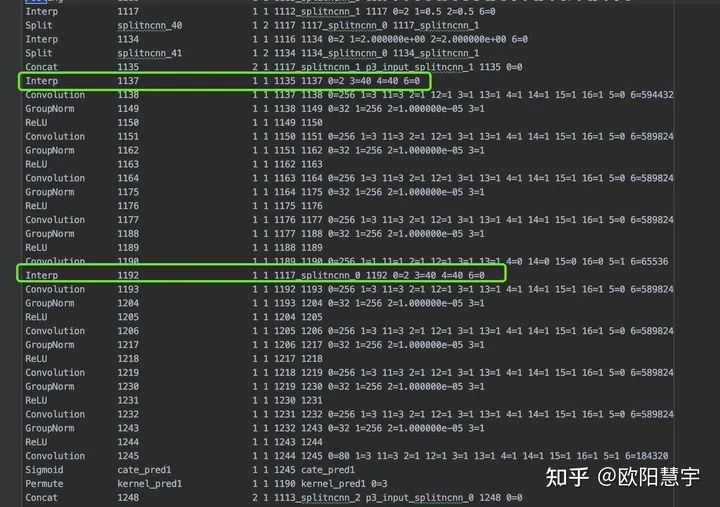
对应40尺寸的改好了,后面32、24、26、12也是类似的;
3、ncnn推理实现
coord输入实现
对比torch半的coord实现:
x_range = torch.linspace(-1, 1, kernel_feat.shape[-1], device=kernel_feat.device)y_range = torch.linspace(-1, 1, kernel_feat.shape[-2], device=kernel_feat.device)x = torch.meshgrid(y_range, x_range)y = y.expand([kernel_feat.shape[0], 1, -1, -1])x = x.expand([kernel_feat.shape[0], 1, -1, -1])coord_feat = torch.cat([x, y], 1)
因为对应stride只有8、16、32,因此ncnn需要生成3个对应尺寸的Mat:
size_t elemsize = sizeof(float);ncnn::Mat x_p3;ncnn::Mat x_p4;ncnn::Mat x_p5;// coord convint pw = int(target_w / 8);int ph = int(target_h / 8);x_p3.create(pw, ph, 2, elemsize);float step_h = 2.f / (ph - 1);float step_w = 2.f / (pw - 1);for (int h = 0; h < ph; h++) {for (int w = 0; w < pw; w++) {x_p3.channel(0)[h * pw + w] = -1.f + step_w * (float) w;x_p3.channel(1)[h * pw + w] = -1.f + step_h * (float) h;}}pw = int(target_w / 16);ph = int(target_h / 16);x_p4.create(pw, ph, 2, elemsize);step_h = 2.f / (ph - 1);step_w = 2.f / (pw - 1);for (int h = 0; h < ph; h++) {for (int w = 0; w < pw; w++) {x_p4.channel(0)[h * pw + w] = -1.f + step_w * (float) w;x_p4.channel(1)[h * pw + w] = -1.f + step_h * (float) h;}}pw = int(target_w / 32);ph = int(target_h / 32);x_p5.create(pw, ph, 2, elemsize);step_h = 2.f / (ph - 1);step_w = 2.f / (pw - 1);for (int h = 0; h < ph; h++) {for (int w = 0; w < pw; w++) {x_p5.channel(0)[h * pw + w] = -1.f + step_w * (float) w;x_p5.channel(1)[h * pw + w] = -1.f + step_h * (float) h;}}
将其作为输入:
ncnn::Extractor ex = solov2.create_extractor();ex.input("input", in);ex.input("p3_input", x_p3);ex.input("p4_input", x_p4);ex.input("p5_input", x_p5);
抽取feature_pred、kernerl_pred、cate_pred特征:
ncnn::Mat feature_pred, cate_pred1, cate_pred2, cate_pred3, cate_pred4, cate_pred5, kernel_pred1, kernel_pred2, kernel_pred3, kernel_pred4, kernel_pred5;ex.extract("cate_pred1", cate_pred1);ex.extract("cate_pred2", cate_pred2);ex.extract("cate_pred3", cate_pred3);ex.extract("cate_pred4", cate_pred4);ex.extract("cate_pred5", cate_pred5);ex.extract("kernel_pred1", kernel_pred1);ex.extract("kernel_pred2", kernel_pred2);ex.extract("kernel_pred3", kernel_pred3);ex.extract("kernel_pred4", kernel_pred4);ex.extract("kernel_pred5", kernel_pred5);ex.extract("feature_pred", feature_pred);
生成分割mask图
前面已经有了kernel_pred和feature_pred,接下来就是生成mask图,这就用到了low-level op api<这里说一句ncnn真灵活,谁用谁知道>,目的是实现torch中的动态conv2d,对应torch实现为:
ins_i = F.conv2d(feature_pred, kernel, groups=N).view(N, self.seg_num_grids[i] ** 2, h, w)ncnn的low-level op api使用wiki:
https://github.com/Tencent/ncnn/wiki创建ncnn::Option
ncnn::Option opt;opt.num_threads = num_threads;opt.use_fp16_storage = false;opt.use_packing_layout = false;
实现分割的预测功能函数
static void ins_decode(const ncnn::Mat &kernel_pred, const ncnn::Mat &feature_pred, ncnn::Mat *ins_pred, int c_in, int c_out,ncnn::Option &opt) {ncnn::Layer *op = ncnn::create_layer("Convolution");ncnn::ParamDict pd;pd.set(0, c_out);pd.set(1, 1);pd.set(6, c_in * c_out);op->load_param(pd);ncnn::Mat weights[1];weights[0].create(c_in * c_out);float *kernel_pred_data = (float *) kernel_pred.data;for (int i = 0; i < c_in * c_out; i++) {weights[0][i] = kernel_pred_data[i];}op->load_model(ncnn::ModelBinFromMatArray(weights));op->create_pipeline(opt);ncnn::Mat temp_ins;op->forward(feature_pred, temp_ins, opt);*ins_pred = temp_ins;op->destroy_pipeline(opt);delete op;}
将每个kernel_pre转换为分割图:
ncnn::Mat ins_pred1, ins_pred2, ins_pred3, ins_pred4, ins_pred5;int c_in = feature_pred.c;ins_decode(kernel_pred1, feature_pred, &ins_pred1, c_in, 40 * 40,opt);ins_decode(kernel_pred2, feature_pred, &ins_pred2, c_in, 36 * 36,opt);ins_decode(kernel_pred3, feature_pred, &ins_pred3, c_in, 24 * 24,opt);ins_decode(kernel_pred4, feature_pred, &ins_pred4, c_in, 16 * 16,opt);ins_decode(kernel_pred5, feature_pred, &ins_pred5, c_in, 12 * 12,opt);
后处理
有了这一切后就是后处理啦,贴代码:
功能函数
void generate_res(ncnn::Mat &cate_pred, ncnn::Mat &ins_pred, std::vector <std::vector<Object>> &objects, float cate_thresh,float conf_thresh, int img_w, int img_h, int num_class, float stride) {int w = cate_pred.w;int h = cate_pred.h;int w_ins = ins_pred.w;int h_ins = ins_pred.h;for (int q = 0; q < num_class; q++) {const float *cate_ptr = cate_pred.channel(q);for (int i = 0; i < h; i++) {for (int j = 0; j < w; j++) {int index = i * w + j;float cate_socre = cate_ptr[index];if (cate_socre < cate_thresh) {continue;}const float *ins_ptr = ins_pred.channel(index);cv::Mat mask(h_ins, w_ins, CV_32FC1);float sum_mask = 0.f;int count_mask = 0;{mask = cv::Scalar(0.f);float *mp = (float *) mask.data;for (int m = 0; m < w_ins * h_ins; m++) {float mask_score = sigmoid(ins_ptr[m]);if (mask_score > 0.5) {mp[m] += mask_score;sum_mask += mask_score;count_mask++;}}}if (count_mask < stride) {continue;}float mask_score = sum_mask / (float(count_mask) + 1e-6);// float socre = mask_score * cate_socre;float socre = mask_score * cate_socre;if (socre < conf_thresh) {continue;}cv::Mat mask2;cv::resize(mask, mask2, cv::Size(img_w, img_h));Object obj;obj.mask = cv::Mat(img_h, img_w, CV_8UC1);float sum_mask_y = 0.f;float sum_mask_x = 0.f;int area = 0;{obj.mask = cv::Scalar(0);for (int y = 0; y < img_h; y++) {const float *mp2 = mask2.ptr<const float>(y);uchar *bmp = obj.mask.ptr<uchar>(y);for (int x = 0; x < img_w; x++) {if (mp2[x] > 0.5f) {bmp[x] = 255;sum_mask_y += (float) y;sum_mask_x += (float) x;area++;} else bmp[x] = 0;}}}obj.cx = int(sum_mask_x / area);obj.cy = int(sum_mask_y / area);obj.label = q + 1;obj.prob = socre;objects[q].push_back(obj);}}}}
每个head的解码:
std::vector <std::vector<Object>> class_candidates;class_candidates.resize(num_class);generate_res(cate_pred1,ins_pred1,class_candidates,cate_thresh,confidence_thresh,img_w,img_h,num_class,8.f);generate_res(cate_pred2,ins_pred2,class_candidates,cate_thresh,confidence_thresh,img_w,img_h,num_class,8.f);generate_res(cate_pred3,ins_pred3,class_candidates,cate_thresh,confidence_thresh,img_w,img_h,num_class,16.f);generate_res(cate_pred4,ins_pred4,class_candidates,cate_thresh,confidence_thresh,img_w,img_h,num_class,32.f);generate_res(cate_pred5,ins_pred5,class_candidates,cate_thresh,confidence_thresh,img_w,img_h,num_class,32.f);
最后就是nms了,nms实现的比较低效:
objects.clear();for (int i = 0; i < (int) class_candidates.size(); i++) {std::vector <Object> &candidates = class_candidates[i];qsort_descent_inplace(candidates);std::vector<int> picked;nms_sorted_segs(candidates, picked, nms_threshold,img_w,img_h);for (int j = 0; j < (int) picked.size(); j++) {int z = picked[j];objects.push_back(candidates[z]);}}qsort_descent_inplace(objects);
至此,已经基本完成了所有工作啦:来预测一张图看看:

可以看出来结果还是非常好的QAQ
速度优化
重中之重来啦,本人针对SOLO的特点做了一处优化,就是kernel_pred的部分,在kernel_pred1部分输出特征图为256x40x40,转换为cond2d的核就为1600x256,1600的通道在stride=4的特征图上耗时巨大,那怎么来优化呢。
SOLO预测的cate_pred1分支预测了40x40=1600个网格,但并不是所有网格都是需要的,只有大于预值得才需要,那么在kernel_pred1的输出部分仅仅只需要cate_pred1大于阈值对应的核就好,基于这个思想就能减少非常多的通道,进而减少计算量。
话不多说,具体这样实现:
首先获取cate_pred大于阈值的index:
功能函数为:
static void kernel_pick(const ncnn::Mat &cate_pred, std::vector<int> &picked, int num_class, float cate_thresh){int w = cate_pred.w;int h = cate_pred.h;for (int q = 0; q < num_class; q++) {const float *cate_ptr = cate_pred.channel(q);for (int i = 0; i < h; i++) {for (int j = 0; j < w; j++) {int index = i * w + j;float cate_score = cate_ptr[index];if (cate_score < cate_thresh) {continue;}else picked.push_back(index);}}}}
获取每个cate_pred分支的index结果:
std::vector<int> kernel_picked1, kernel_picked2, kernel_picked3, kernel_picked4, kernel_picked5;kernel_pick(cate_pred1, kernel_picked1, num_class, cate_thresh);kernel_pick(cate_pred2, kernel_picked2, num_class, cate_thresh);kernel_pick(cate_pred3, kernel_picked3, num_class, cate_thresh);kernel_pick(cate_pred4, kernel_picked4, num_class, cate_thresh);kernel_pick(cate_pred5, kernel_picked5, num_class, cate_thresh);
在ins_decode功能函数中加入map,来保存index和ins_pred的通道索引的映射关系
static void ins_decode(const ncnn::Mat &kernel_pred, const ncnn::Mat &feature_pred, std::vector<int> &kernel_picked,std::map<int, int> &kernel_map, ncnn::Mat *ins_pred, int c_in,ncnn::Option &opt) {std::set<int> kernel_pick_set;kernel_pick_set.insert(kernel_picked.begin(), kernel_picked.end());int c_out = kernel_pick_set.size();if (c_out > 0) {ncnn::Layer *op = ncnn::create_layer("Convolution");ncnn::ParamDict pd;pd.set(0, c_out);pd.set(1, 1);pd.set(6, c_in * c_out);op->load_param(pd);ncnn::Mat weights[1];weights[0].create(c_in * c_out);float *kernel_pred_data = (float *) kernel_pred.data;std::set<int>::iterator pick_c;int count_c = 0;for (pick_c = kernel_pick_set.begin(); pick_c != kernel_pick_set.end(); pick_c++){kernel_map[*pick_c] = count_c;for (int j = 0; j < c_in; j++) {weights[0][count_c * c_in + j] = kernel_pred_data[c_in * (*pick_c) + j];}count_c++;}op->load_model(ncnn::ModelBinFromMatArray(weights));op->create_pipeline(opt);ncnn::Mat temp_ins;op->forward(feature_pred, temp_ins, opt);*ins_pred = temp_ins;op->destroy_pipeline(opt);delete op;}}
这样后面generate_res里面通过map来获取ins_pred的特征:
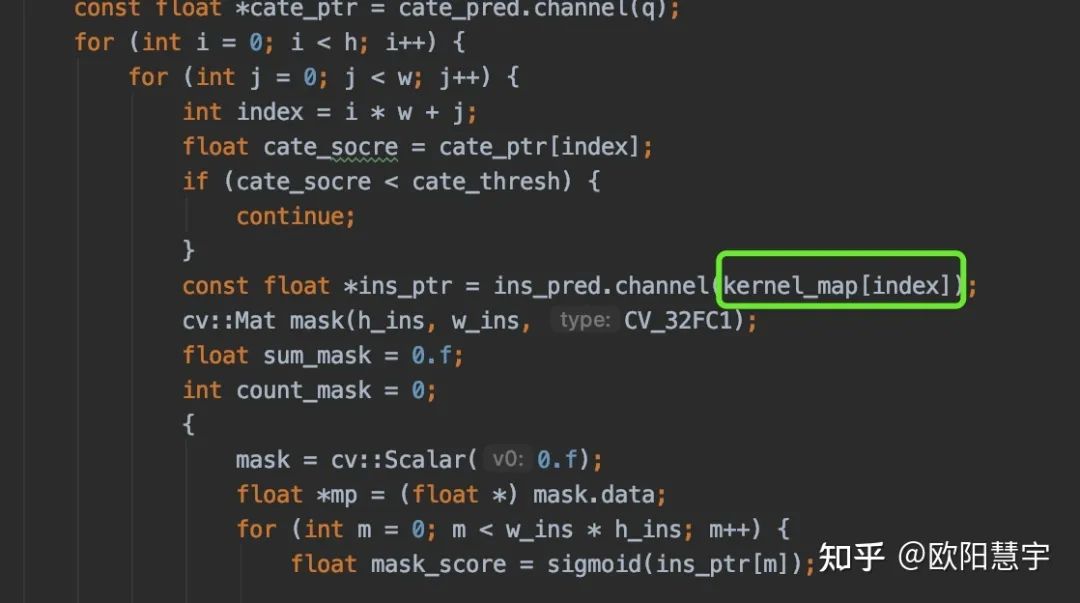
速度对比
先来打印一下ins_pred的通道
std::cout << ins_pred1.h << "," << ins_pred1.w << "," << ins_pred1.c << std::endl;std::cout << ins_pred2.h << "," << ins_pred2.w << "," << ins_pred2.c << std::endl;std::cout << ins_pred3.h << "," << ins_pred3.w << "," << ins_pred3.c << std::endl;std::cout << ins_pred4.h << "," << ins_pred4.w << "," << ins_pred4.c << std::endl;std::cout << ins_pred5.h << "," << ins_pred5.w << "," << ins_pred5.c << std::endl;
没做通道筛选之前:

做了通道筛选后:
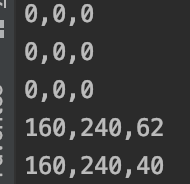
从1600+1296+576+256+144 = 3872 -> 62+40 = 102 ,对于stride=4的特征图这计算量减少了许多,如果在cate_pred的输出做maxpool的nms,通道数还会减少几倍。
resnet_r101的backbone下,耗时6825.4ms ->5226.95ms(backbone太厚了,本人训练一个mbv2版本,已经上传百度云,700ms左右的样子,14年老mac cpu单线程)
总结
实践下如何在ncnn上使用动态op和corrd_conv,以及后处理后处理优化的一些策略,给需要的人一点借鉴。
项目地址
https://github.com/DayBreak-u/SOLOV2_ncnn