
什么是算法?从枚举到贪心再到启发式(上)

并且假定屏幕前的你只有大一刚学完谭浩强红本本的水平
从背包问题说起
 kg的物品。
kg的物品。现在有
 个物品摆在你面前,每个物品都有自己的重量
个物品摆在你面前,每个物品都有自己的重量 和价值
和价值 。
。好了,现在要你做成决策了:究竟选哪些物品装进背包,才能使得在不超过背包容量的情况下,获得最大的价值呢?
![]()
★好了,现在我们遇到了一个问题,得想想办法来解决它! 在此之前我们再讲一点东西,观察上面的问题,能发现什么特点呢?
![]()
一般而言,算法所需要解决的问题,都能分成两个部分:
· 目标:什么是目标呢?简单点说就是要优化的东西,比如在上述背包问题中,要优化的就是所选物品的价值,使其最大。
· 决策:顾名思义就是根据目标所作出的决策,比如在这里就是决定选取哪些物品装进我们的背包。
· 约束:那么何又为约束呢?就是说再进行决策时必须遵循的条件,比如上面的背包问题,我们所选取的物品总的重量不能超过背包的容量。要是没有容量的约束,小学生才做选择呢,我全都要!

算例
知道了问题以后就可以生成问题的算例了那么什么又是问题的算例呢?就是问题参数的具体化
比如在上述的0-1背包问题中,背包的容量
 现在问题知道了算例也有了我们再来谈谈什么是Benchmark?
现在问题知道了算例也有了我们再来谈谈什么是Benchmark?Benchmark就是求解问题算例的一个基准,比如在刚刚的背包问题算例中,最优解很容易看得出是选取第3个物品(注:本文所有序数都是从1开始,不存在什么第0个的情况。),获得的价值为7,这个最优解可以看成是该算例的一个Benchmark。
当然
Benchmark概念的引出
只是为了方便我们对算法的效果进行一个对比

定义问题实例
 算例的数据结构在代码中的表示方式倒不用我们思考太多,按照给出的样例,采用合适的数据结构表示出来就行。针对上面的背包问题算例,我们还是设计一个类来表示吧:
算例的数据结构在代码中的表示方式倒不用我们思考太多,按照给出的样例,采用合适的数据结构表示出来就行。针对上面的背包问题算例,我们还是设计一个类来表示吧:class kp_instance():def __init__(self):self.C = 0 # 背包容量self.N = 0 # 物品个数self.W_V = [] # 各个物品的重量和价值[(w_1,v_1), ..., (w_n,v_n)]def read_data(self, line):pass

这个类有几个成员变量,表示一个背包问题实例的具体参数。
它有个read_data()函数,表示从某处读取这些具体的参数保存到变量中。
这里呢我们暂时给隐藏掉(防止有些小朋友说太难了……)。
读取的算例呢是以下格式的文件⬇️
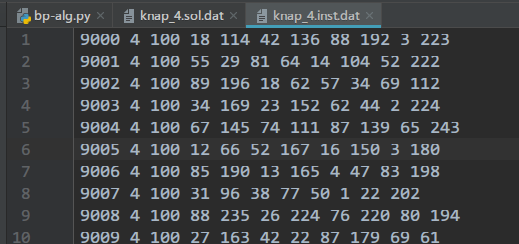
每行代表一个算例,从左到右的数字依次为:算例ID,物品个数,背包容量,物品1重量,物品1价值,物品2重量,物品2价值,……,物品n重量,物品n价值。
同时,这些算例也提供了一个benchmark⬇️
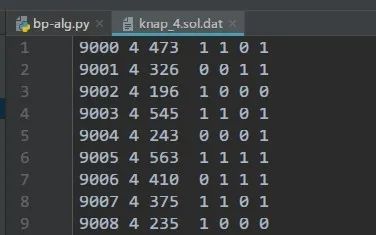
↑
从左到右依次为:算例ID,物品个数,选择物品的总价值,选择决策(1选择该物品,0不选)。
后续我们将用这个benchmark与我们设计的算法对比。
解的表示与评价

因为该问题的决策只有两种状态,所以我们可以用0表示不拿,1表示拿。N个物品我们就可以用一个N维的数组x进行表示,当:
class kp_solution():def __init__(self):self.decision = [] # 决策变量self.total_value = 0 # decision决策对应的目标值self.feasible = False # decision决策是否满足所有约束
现在解已经用计算机语言表示出来了,如何去评价一个解已经十分明了了:根据问题的参数,计算决策获得的价值,以及判断该决策是否可行。

还是再写一个评价函数吧评价时呢肯定是需要问题的具体参数,那么需要用到此前定义的kp_instance类:
def evaluate(sol: kp_solution, ins: kp_instance) -> None:total_weight = 0total_value = 0for i in range(len(sol.decision)):if sol.decision[i] == 1: # 选择了物品itotal_value += ins.W_V[i][1]total_weight += ins.W_V[i][0]if total_weight > ins.C: # 超出了背包的容量,不可行sol.feasible = Falseelse:sol.feasible = Truesol.total_value = total_value # 记录总的价值
小试牛刀:枚举
上面我们一步一步将算法需要相关数据给设计好了有了以上的基础我们就可以着手相关的算法设计求解了
先看看枚举法吧~?

枚举就不用我多说了吧,简单点说就是把问题所有的解给一一枚举出来,挨个去评价,然后选出最好的那个。
针对上面解的表示方式,很容易得出其所有的解就是N位01的全排列。
来看看代码
def enum_sol(ins: kp_instance)-> kp_solution:current_sol = kp_solution()best_sol = kp_solution()best_sol.total_value = -INF# 生成决策的全排列all_decisions = list(it.product(range(2), repeat=ins.N)) # 返回N位的01全排列for d in all_decisions:current_sol.decision = devaluate(current_sol, ins) # 评价当前解if best_sol.total_value < current_sol.total_value and current_sol.feasible: # 如果找到新的可行全局最优解best_sol = copy.deepcopy(current_sol)return best_sol
我们一开始新建两个解,当前解和全局最优解。因为我们要求的是最大值,一开始让全局最优解的价值为负无穷。然后在枚举的所有决策中挨个评价,如果找到比当前全局最优还要好的解(并且该解是可行的!),那么更新全局最优解。

可能有小伙伴对it.product(range(2), repeat=ins.N)有疑问
它的意思是生成N位的01全排列
比如:
import itertools as its = list(it.product(range(2), repeat=5))print(s)
结果如下,是不是很方便呢!
⬇️
[]评测
算法写出来了
当然还得评测一下啦
为了方便后续的测评
我们还是写个函数吧
def solver_and_compare(method, inst_file_path, solution_file_path):"""Main method that solves knapsack problem using one of the existing methods:param method: knapsack problem solving method:param inst_file_path: path to file with input instances:param solution_file_path: path to file where solver should write output data"""pass
该函数使用method算法,对文件inst_file_path中的算例进行求解,输出最优解和时间,并将该最优解与solution_file_path中的benchmark进行对比,计算两者偏差的百分比。
具体计算方式如下:
gap = (mc - bc) / bc
其中:
mc 为我们算法找到的解
bc benchmark为给出的解
当然为了避免读者抱怨代码过于复杂这里还是直接隐藏代码细节我们直接来看结果吧!+---------+--------+-------------+---------+-----------+-------+| inst_id | number | enumeration | time | benckmark | gap % |+---------+--------+-------------+---------+-----------+-------+| 9000 | 4 | 473 | 0.0001 | 473 | 0.0 || 9001 | 4 | 326 | 0.0001 | 326 | 0.0 || 9002 | 4 | 196 | 0.0001 | 196 | 0.0 || 9050 | 10 | 798 | 0.0026 | 798 | 0.0 || 9051 | 10 | 942 | 0.0024 | 942 | 0.0 || 9052 | 10 | 740 | 0.0022 | 740 | 0.0 || 9100 | 15 | 2358 | 0.1028 | 2358 | 0.0 || 9101 | 15 | 1726 | 0.0924 | 1726 | 0.0 || 9102 | 15 | 2064 | 0.0975 | 2064 | 0.0 || 9150 | 20 | 1995 | 3.7705 | 1995 | 0.0 || 9151 | 20 | 2623 | 3.6683 | 2623 | 0.0 || 9152 | 20 | 2607 | 3.6509 | 2607 | 0.0 || 9200 | 22 | 2625 | 15.9776 | 2625 | 0.0 || 9201 | 22 | 2215 | 15.9097 | 2215 | 0.0 || 9202 | 22 | 2479 | 16.0191 | 2479 | 0.0 |+---------+--------+-------------+---------+-----------+-------+
✪注:number一栏表示该算例下物品的个数。

1. 枚举法能够找到问题的最优解
这是显而易见的,比较你把所有的解(无论可行的还是不可行的)都比较了一遍,还找不出最优的就说不过去了吧。如此看来,这枚举法是个好东西啊,简单粗暴,结果还是最优。是吗?
2. 枚举法求解时间随问题规模增长而呈爆炸式增长
枚举法致命的缺陷就是其求解所需的资源(直观上就是时间、内存等)随当问题规模的增长而呈指数级别增长。这是什么意思呢?
大家看看上面的求解结果
当问题的物品数为4时
求解时间为0.0001
当物品个数增加到22时
求解时间为16.0191
问题规模变为原来的22/4=5.5倍
而求解时间却变为原来的16.0191/0.0001=160191倍
刺激吧
可能这样说大家还没啥感受,那么画个图直观感受下吧
(横着物品个数,纵轴求解时间)
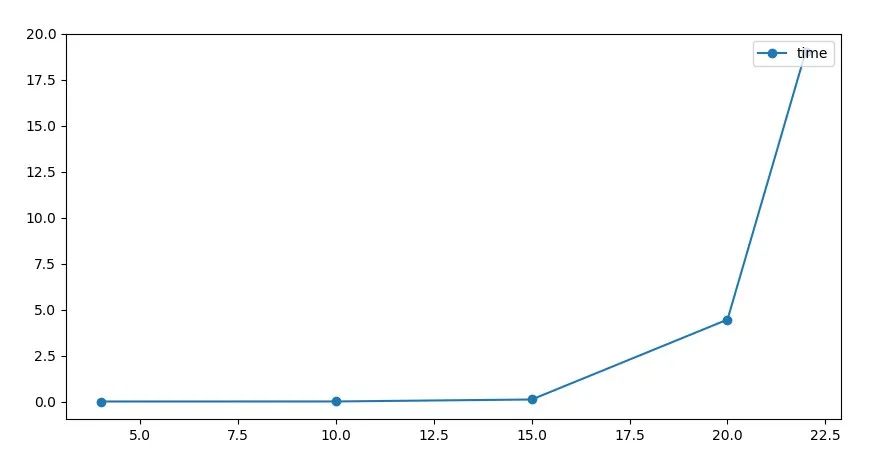
时间增长很明显的指数趋势。当然了,这里为了不再压榨小编这台可怜的电脑,算例规模就没继续增加了。有兴趣的小伙伴可以下载源代码回去自己继续做实验。
总结起来就是,枚举虽然能找到问题的最优解,但是由于其需要花费的计算资源过大,人们往往都不会采用这种方式去求解一个问题。
再探:贪心
﹏
﹏
﹏
﹏
小王家有一颗很高的果树,每年结满果实的时候因为树太高小王都没办法好好摘取所有的果实,只能拿竹竿捅下来一部分。在某一年里,小王在书上看到了鲁迅说要想富先撸树,于是为了能吃到更多的果实小王把整个树给撸掉了。当年小王跟全家人饱餐了一顿,并且多余的果子还买了点小钱。但是在后来的日子里,小王就再也没有果实摘了。

上面就是一个贪心的例子,相信现实中也不乏这样的事件。大家想想,如果不砍那棵树,虽然当年收获的果实会少一点,但是下一年,下下年依然能收获到果实,子子孙孙无穷无尽,总体下来肯定是不砍树获得的收益更大。
但也正是“要想富先撸树”这种贪心的思想,导致了小王一时被利益蒙蔽了双眼,就把树给撸掉了。那么大家想想一个问题:想要在当年吃到更多的果实,非得把树给连根砍掉吗?
那可未必!可以选择在当年把带有果子的树干给砍下来,这样也能在当年获得更多的果子。并且随着时间的推移,等树的新枝长出来了,小王就可以再次进行同样的操作。这样一年又一年,显然能获得比直接砍树更多的果子。
我们可以看到,在某一年里“砍树”和“砍树枝”都是基于贪心思想的两种不同的贪心方式。显然“砍树枝”这种方式是要优于“砍树”这种方式的。
可见,贪心算法不仅仅是简单的局部最优这么简单,他最终的结果跟贪心的方式是密切相关的。我们回来看背包问题这个例子,写写代码跑一跑大家都明白了。
首先,我们基于第一种贪心的方式:满足背包容量的前提下,拿价值大的物品。
def greedy1(ins: kp_instance) -> kp_solution:sorted_items = ins.W_V.copy()sorted_items.sort(key=lambda x: x[1], reverse=True) # 对价值进行降序排序current_weight = 0best_sol = kp_solution()best_sol.decision = [0 for _ in range(len(ins.W_V))]best_sol.feasible = True# 在容量范围内,不断挑价值大的往里面装for item in sorted_items:if current_weight + item[0] > ins.C: # 这个物品装不下了,看看下一个continuebest_sol.total_value += item[1]current_weight += item[0]best_sol.decision[ins.W_V.index(item)] = 1 # 记录选择的物品return best_sol
现在依然是和最优的benchmark进行对比,看看效果如何:
+---------+--------+---------+--------+-----------+--------+| inst_id | number | greedy1 | time | benckmark | gap % |+---------+--------+---------+--------+-----------+--------+| 9000 | 4 | 415 | 0.0 | 473 | -12.26 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 || 9002 | 4 | 196 | 0.0 | 196 | 0.0 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 || 9052 | 10 | 701 | 0.0 | 740 | -5.27 || 9100 | 15 | 2341 | 0.0 | 2358 | -0.72 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 || 9102 | 15 | 2053 | 0.0 | 2064 | -0.53 || 9150 | 20 | 1924 | 0.0001 | 1995 | -3.56 || 9151 | 20 | 2623 | 0.0001 | 2623 | 0.0 || 9152 | 20 | 2553 | 0.0001 | 2607 | -2.07 || 9200 | 22 | 2607 | 0.0001 | 2625 | -0.69 || 9201 | 22 | 2107 | 0.0001 | 2215 | -4.88 || 9202 | 22 | 2479 | 0.0001 | 2479 | 0.0 |+---------+--------+---------+--------+-----------+--------+
好了,我们现在来试试第二种贪心的方式:满足背包容量的前提下,拿性价比高的物品。性价比=价值/密度。
def greedy2(ins: kp_instance) -> kp_solution:sorted_items = ins.W_V.copy()sorted_items.sort(key=lambda x: x[1] / x[0], reverse=True) # 对价值进行降序排序current_weight = 0best_sol = kp_solution()best_sol.decision = [0 for _ in range(len(ins.W_V))]best_sol.feasible = True# 在容量范围内,不断挑性价比大的往里面装for item in sorted_items:if current_weight + item[0] > ins.C: # 这个物品装不下了,看看下一个continuebest_sol.total_value += item[1]current_weight += item[0]best_sol.decision[ins.W_V.index(item)] = 1 # 记录选择的物品return best_sol
代码实现方式和此前的差不多,这里大家应该都能看懂就不说了。
看看结果如何
+---------+--------+---------+------+-----------+--------+| inst_id | number | greedy2 | time | benckmark | gap % |+---------+--------+---------+------+-----------+--------+| 9000 | 4 | 473 | 0.0 | 473 | 0.0 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 || 9002 | 4 | 174 | 0.0 | 196 | -11.22 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 || 9052 | 10 | 740 | 0.0 | 740 | 0.0 || 9100 | 15 | 2321 | 0.0 | 2358 | -1.57 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 || 9102 | 15 | 2064 | 0.0 | 2064 | 0.0 || 9150 | 20 | 1979 | 0.0 | 1995 | -0.8 || 9151 | 20 | 2516 | 0.0 | 2623 | -4.08 || 9152 | 20 | 2564 | 0.0 | 2607 | -1.65 || 9200 | 22 | 2625 | 0.0 | 2625 | 0.0 || 9201 | 22 | 2211 | 0.0 | 2215 | -0.18 || 9202 | 22 | 2433 | 0.0 | 2479 | -1.86 |+---------+--------+---------+------+-----------+--------+
直观上感觉这种方式的效果更好了一点呢,因为大部分算例都能直接找到最优解了。但是至于是不是真的好,大家说了才算,我们比较下两种贪心的方式:
+---------+--------+---------+--------+---------+--------+--------+| inst_id | number | greedy1 | time1 | greedy2 | time2 | gap % |+---------+--------+---------+--------+---------+--------+--------+| 9000 | 4 | 415 | 0.0 | 473 | 0.0 | -12.26 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 | 0.0 || 9002 | 4 | 196 | 0.0 | 174 | 0.0 | 12.64 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 | 0.0 || 9052 | 10 | 701 | 0.0 | 740 | 0.0 | -5.27 || 9100 | 15 | 2341 | 0.0 | 2321 | 0.0 | 0.86 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 | 0.0 || 9102 | 15 | 2053 | 0.0 | 2064 | 0.0 | -0.53 || 9150 | 20 | 1924 | 0.0001 | 1979 | 0.0001 | -2.78 || 9151 | 20 | 2623 | 0.0001 | 2516 | 0.0001 | 4.25 || 9152 | 20 | 2553 | 0.0001 | 2564 | 0.0001 | -0.43 || 9200 | 22 | 2607 | 0.0001 | 2625 | 0.0001 | -0.69 || 9201 | 22 | 2107 | 0.0001 | 2211 | 0.0001 | -4.7 || 9202 | 22 | 2479 | 0.0001 | 2433 | 0.0001 | 1.89 |+---------+--------+---------+--------+---------+--------+--------+
其中gap = (greedy1 - greedy2 )/greedy1。
gap一列中,负值的行表示该算例下greedy1要比greedy2找到的解价值少一些,也就是该解差一些。
从上面的结果中可以看出,负值很明显比正值多,就测试的算例看来,greedy2的方式效果要好一些。
也就是以密度贪心的方式更为有效一些。
(不知道大家注意到上述结果的时间没有,贪心方式求解的速度真的快到没朋友)
因为两种greedy的求解时间没有太大区别,我们取greedy1的求解时间与枚举法的求解时间比较一下:
+---------+--------+--------------+------------------+--------------+| inst_id | number | greedy1_time | enumeration_time | gap % |+---------+--------+--------------+------------------+--------------+| 9000 | 4 | 0.0 | 0.0001 | -434.48 || 9001 | 4 | 0.0 | 0.0001 | -883.33 || 9002 | 4 | 0.0 | 0.0001 | -1378.57 || 9050 | 10 | 0.0 | 0.0029 | -26853.85 || 9051 | 10 | 0.0 | 0.0034 | -28400.0 || 9052 | 10 | 0.0 | 0.0025 | -20143.33 || 9100 | 15 | 0.0 | 0.1056 | -677307.89 || 9101 | 15 | 0.0 | 0.1059 | -220584.62 || 9102 | 15 | 0.0 | 0.1059 | -496103.85 || 9150 | 20 | 0.0 | 4.9548 | -21188157.89 || 9151 | 20 | 0.0 | 4.3277 | -14065001.33 || 9152 | 20 | 0.0 | 4.3265 | -13695871.43 || 9200 | 22 | 0.0 | 22.5842 | -62555795.45 || 9201 | 22 | 0.0001 | 21.4181 | -19700567.17 || 9202 | 22 | 0.0001 | 19.3518 | -23236437.44 |+---------+--------+--------------+------------------+--------------+
其中gap = (greedy1_time - enumeration_time)/greedy1_time * 100%
 这时间差距实在是太大了那么为什么贪心算法这么 快呢?
这时间差距实在是太大了那么为什么贪心算法这么 快呢?
其实大家注意到了没有,贪心算法其实就是一个“构造”解的过程而已,相比较于枚举法而言,贪心是没有“搜索”这一过程的,他只是按照一定的方式,将解给构造起来而已。因此,贪心法大多数情况下,在取得还算“过得去”的结果的同时,也能保持较快求解速度。这是贪心算法的一大优点。
综合起来:
贪心算法能取得“还可以”的解,有时候甚至能找到最优解。
贪心算法由于只是利用“构造”的方式生成解,因此速度相对而言会非常快,同时不会随着问题规模的增长而大幅度增加,是平缓的线性增长。
如果想利用贪心取得较好的结果,那么就需要设计出优秀的贪心方式了。

 那么大家再想想贪心除了碰巧能取得最优解什么情况下一定能取得最优解呢?
那么大家再想想贪心除了碰巧能取得最优解什么情况下一定能取得最优解呢?
?其实很简单,当贪心过程中决策的每一步都互不影响时,最终的结果就是最优解。
其实真是这种情况的话,那么整个问题的各个步骤的决策都可以重新分解为一个单独的子问题了,那么由于各个子问题互不影响,贪心获得子问题的最优,组合起来最后肯定也是全局的最优。

文案&编辑:邓发珩(华中科技大学管理学院本科三年级)审稿人:秦时明岳(华中科技大学管理学院)指导老师:秦时明岳(华中科技大学管理学院)排版:程欣悦(荆楚理工学院本科二年级)
如对文中内容有疑问,欢迎交流。PS:部分资料来自网络。如有需求,可以联系:秦虎老师(professor.qin@qq.com)邓发珩(华中科技大学管理学院本科三年级:2638512393@qq.com)程欣悦(荆楚理工学院本科二年级:1293900389@qq.com)