
如何提升算法工程师的大数据开发能力
大家好,我是DASOU;
我之前学习Spark的时候,主要是对着那本spark数据分析敲了一遍代码,然后在Github上狂搜一些比较好的项目,还真让我找到一个,这个后面说;
我先来说说我的想法,就是为啥算法工程师需要大数据开发能力。
对于算法工程师来说,开发能力我自己认为可以分为两种。
一种是有能力写个比较稳定的接口,对外提供服务;如果并发很大的话,公司一般会有专门的团队进行维护。算法工程师写的接口,公司可能也不放心用,笑;
当然如果接口也是组内开发同学写的,比如是C++代码,需要你进行上下线,那么你也要会相应的C++,基本会用其实就可以了(如果是大佬,请忽略我这个渣渣的建议);
但是如果并发不大,比如几百个并发,那么需要自己操刀动手。这个也不难,直接申请资源堆机器就可以(我开玩笑的)。
另一种能力是数据获取的能力。今天我重点说这个;一般在找工作的时候,这个技能是必备的,如果没有这个,基本就是没戏了;
之前写个一个文章来聊这个事情,感兴趣的朋友可以读一下: 算法工程师常说的【处理数据】究竟是在做什么
在互联网公司,数据量是很大的。面对这么大量数据,在做特征工程的时候,用numpy或者padas肯定是力有不逮的。
在获取数据的时候一般就是hive,或者spark;
对于一个大型公司来说,一般是hive和spark都会使用;
对于Hive来说,一般只要懂SQL,一般操作hive就没啥问题;
如果要学习Spark,学习的时候一般会遇到一个困惑。Spark提供了多种接口,主流就是java,python和scala;那么学习哪一种呢?
我自己的建议是直接上手Pyspark,因为简单而且上手快;我自己就是学习的pyspark;
我在学习spark的时候,找了很多资源,对着那本saprk数据分析敲了大部分的代码,然后在github上找到了一个比较好的项目,叫【10天吃掉那只pyspark】。
这个项目我自己对着敲了大部分代码,然后看了一遍。不禁感叹,有些人在写教程方面确实是有天赋的,拍马难及。
我自己在B站是录制了一些教学视频(TRM视频已经突破2万了,太开心了),知道写一个教程是有多难,时常因为怎么把东西写的浅显易懂而苦恼。
总之吧,这个项目我自己还是很推荐的;
整个教程大纲大概是这样的:
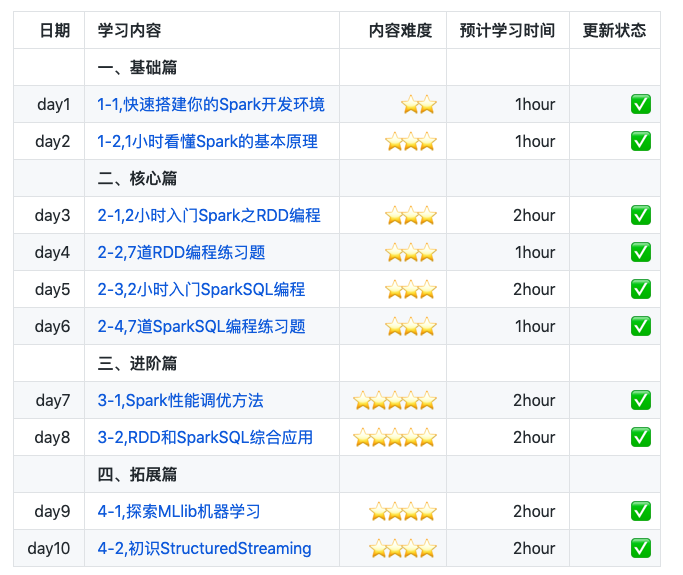
正巧和项目的作者约了一个互推,就把这个项目推荐给大家。希望第大家有所帮助。
感兴趣的朋友直接关注下面公众号,后台回复pyspark,获取项目《eat pyspark in 10 days》github地址。
下面的内容,我就直接照搬原作者的内容了,包括项目地址,以及项目特色。感兴趣的朋友可以看看,时间不够的朋友直接看上面的github也可以;
一,pyspark 🍎 or spark-scala 🔥 ?
pyspark强于分析,spark-scala强于工程。
如果应用场景有非常高的性能需求,应该选择spark-scala.
如果应用场景有非常多的可视化和机器学习算法需求,推荐使用pyspark,可以更好地和python中的相关库配合使用。
此外spark-scala支持spark graphx图计算模块,而pyspark是不支持的。
pyspark学习曲线平缓,spark-scala学习曲线陡峭。
从学习成本来说,spark-scala学习曲线陡峭,不仅因为scala是一门困难的语言,更加因为在前方的道路上会有无尽的环境配置痛苦等待着读者。
而pyspark学习成本相对较低,环境配置相对容易。从学习成本来说,如果说pyspark的学习成本是3,那么spark-scala的学习成本大概是9。
如果读者有较强的学习能力和充分的学习时间,建议选择spark-scala,能够解锁spark的全部技能,并获得最优性能,这也是工业界最普遍使用spark的方式。
如果读者学习时间有限,并对Python情有独钟,建议选择pyspark。pyspark在工业界的使用目前也越来越普遍。
二,本书📚 面向读者🤗
本书假定读者具有基础的的Python编码能力,熟悉Python中numpy, pandas库的基本用法。
并且假定读者具有一定的SQL使用经验,熟悉select,join,group by等sql语法。
三,本书写作风格🍉
本书是一本对人类用户极其友善的pyspark入门工具书,Don't let me think是本书的最高追求。
本书主要是在参考spark官方文档,并结合作者学习使用经验基础上整理总结写成的。
不同于Spark官方文档的繁冗断码,本书在篇章结构和范例选取上做了大量的优化,在用户友好度方面更胜一筹。
本书按照内容难易程度、读者检索习惯和spark自身的层次结构设计内容,循序渐进,层次清晰,方便按照功能查找相应范例。
本书在范例设计上尽可能简约化和结构化,增强范例易读性和通用性,大部分代码片段在实践中可即取即用。
如果说通过学习spark官方文档掌握pyspark的难度大概是5,那么通过本书学习掌握pyspark的难度应该大概是2.
仅以下图对比spark官方文档与本书《10天吃掉那只pyspark》的差异。

四,本书学习方案 ⏰
1,学习计划
本书是作者利用工作之余大概1个月写成的,大部分读者应该在10天可以完全学会。
预计每天花费的学习时间在30分钟到2个小时之间。
当然,本书也非常适合作为pyspark的工具手册在工程落地时作为范例库参考。
2,学习环境
本书全部源码在jupyter中编写测试通过,建议通过git克隆到本地,并在jupyter中交互式运行学习。
为了直接能够在jupyter中打开markdown文件,建议安装jupytext,将markdown转换成ipynb文件。
为简单起见,本书按照如下2个步骤配置单机版spark3.0.1环境进行练习。
#step1: 安装java8#jdk下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html#java安装教程:https://www.runoob.com/java/java-environment-setup.html#step2: 安装pyspark,findsparkpip install -i https://pypi.tuna.tsinghua.edu.cn/simple pysparkpip install findspark
此外,也可以在和鲸社区的云端notebook中直接运行pyspark,没有任何环境配置痛苦。详情参考该项目的readme文档。
import findspark
#指定spark_home,指定python路径
spark_home = "/Users/liangyun/anaconda3/lib/python3.7/site-packages/pyspark"
python_path = "/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
print("spark version:",pyspark.__version__)
rdd = sc.parallelize(["hello","spark"])
print(rdd.reduce(lambda x,y:x+' '+y))
spark version: 3.0.1
hello spark
五,鼓励和联系作者
感兴趣的小伙伴可以扫码下方二维码,关注公众号:算法美食屋,后台回复关键字:pyspark,获取项目《eat pyspark in 10 days》github地址。
也可以在公众号后台回复关键字:spark加群,加入spark和大数据读者交流群和大家讨论。