
独家 | 利用LSTM实现股价预测

作者:Siddharth M 翻译:王可汗 校对:欧阳锦 本文约1300字,建议阅读6分钟
本文教你如何利用LSTM网络预测股价走势,并对开盘和收盘价进行可视化。
一、介绍
数据集:
二、利用LSTM实现股票的时间序列预测
gstock_data = pd.read_csv('data.csv')gstock_data .head()
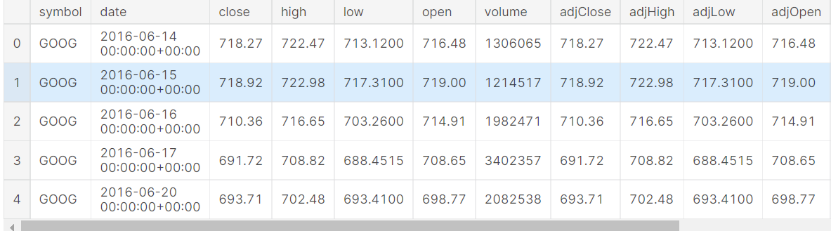
数据集探索:
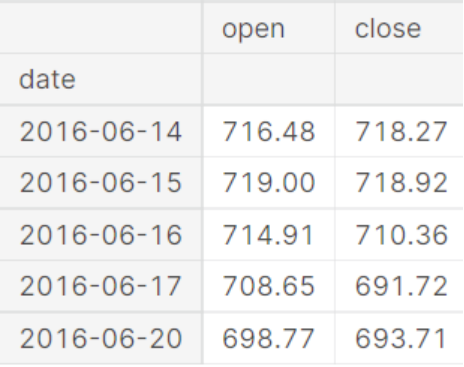
gstock_data = gstock_data [['date','open','close']]gstock_data ['date'] = pd.to_datetime(gstock_data ['date'].apply(lambda x: x.split()[0]))gstock_data .set_index('date',drop=True,inplace=True)gstock_data .head()
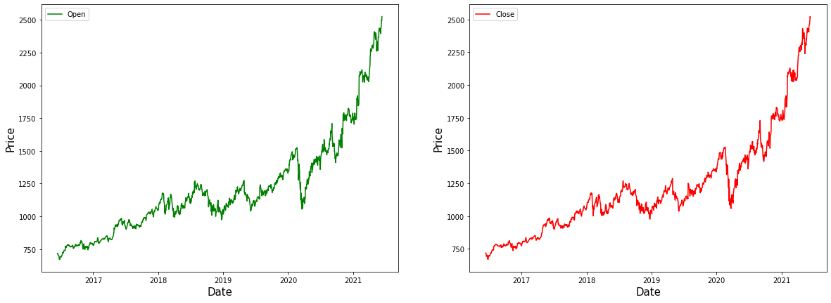
fg,ax=plt."parent.postMessage({'referent':'.matplotlib.pyplot.subplots'}, '*')">subplots(1,2,figsize=(20,7))ax[0].plot(gstock_data ['open'],label='Open',color='green')ax[0].set_xlabel('Date',size=15)ax[0].set_ylabel('Price',size=15)ax[0].legend()ax[1].plot(gstock_data ['close'],label='Close',color='red')ax[1].set_xlabel('Date',size=15)ax[1].set_ylabel('Price',size=15)ax[1].legend()fg.show()
数据预处理:
from sklearn.preprocessing import MinMaxScalerMs = MinMaxScaler()gstock_data [gstock_data .columns] = Ms.fit_transform(gstock_data )training_size = round(len(gstock_data ) * 0.80)train_data = gstock_data [:training_size]test_data = gstock_data [training_size:]
训练数据的划分:
def create_sequence(dataset):sequences = []labels = []start_idx = 0for stop_idx in range(50,len(dataset)):sequences.append(dataset.iloc[start_idx:stop_idx])labels.append(dataset.iloc[stop_idx])start_idx += 1return (np.array(sequences),np.array(labels))train_seq, train_label = create_sequence(train_data)test_seq, test_label = create_sequence(test_data)
LSTM模型的实现:
from keras.models import Sequentialfrom keras.layers import Dense, Dropout, LSTM, Bidirectional
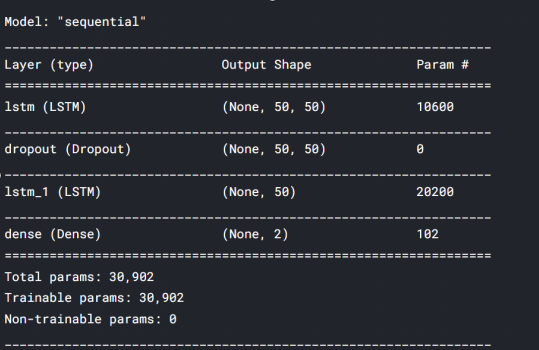
model = Sequential()model.add(LSTM(units=50, return_sequences=True, input_shape = (train_seq.shape[1], train_seq.shape[2])))model.add(Dropout(0.1))model.add(LSTM(units=50))model.add(Dense(2))model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mean_absolute_error'])model.summary()model.fit(train_seq, train_label, epochs=80,validation_data=(test_seq, test_label), verbose=1)test_predicted = model.predict(test_seq)test_inverse_predicted = MMS.inverse_transform(test_predicted)
可视化:
# Merging actual and predicted data for better visualizationgs_slic_data = pd.concat([gstock_data .iloc[-202:].copy(),pd.DataFrame(test_inverse_predicted,columns=['open_predicted','close_predicted'],index=gstock_data .iloc[-202:].index)], axis=1)gs_slic_data[['open','close']] = MMS.inverse_transform(gs_slic_data[['open','close']])gs_slic_data.head()gs_slic_data[['open','open_predicted']].plot(figsize=(10,6))plt."parent.postMessage({'referent':'.matplotlib.pyplot.xticks'}, '*')">xticks(rotation=45)plt."parent.postMessage({'referent':'.matplotlib.pyplot.xlabel'}, '*')">xlabel('Date',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.ylabel'}, '*')">ylabel('Stock Price',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.title'}, '*')">title('Actual vs Predicted for open price',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.show'}, '*')">show()gs_slic_data[['close','close_predicted']].plot(figsize=(10,6))plt."parent.postMessage({'referent':'.matplotlib.pyplot.xticks'}, '*')">xticks(rotation=45)plt."parent.postMessage({'referent':'.matplotlib.pyplot.xlabel'}, '*')">xlabel('Date',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.ylabel'}, '*')">ylabel('Stock Price',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.title'}, '*')">title('Actual vs Predicted for close price',size=15)plt."parent.postMessage({'referent':'.matplotlib.pyplot.show'}, '*')">show()
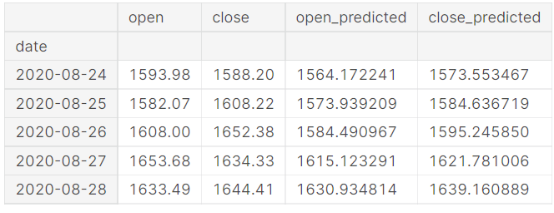
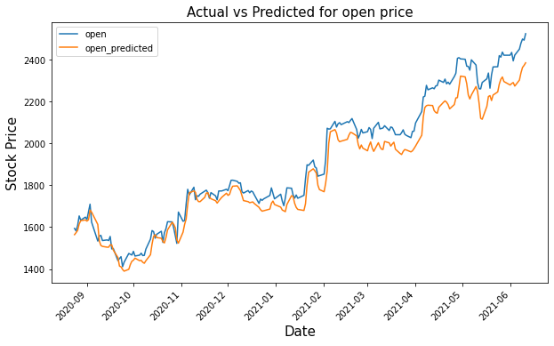
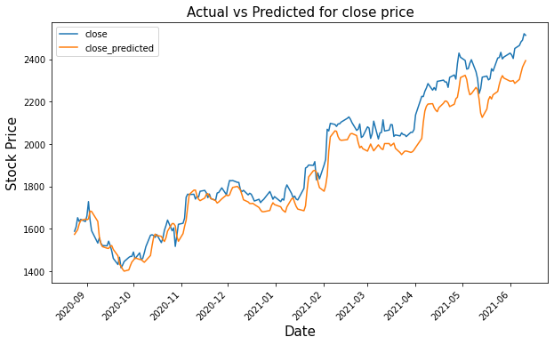
三、结论
参考:
https://the-learning-machine.com/article/dl/long-short-term-memory
https://www.kaggle.com/amarsharma768/stock-price-prediction-using-lstm/notebook
编辑:黄继彦
译者简介

王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”查看原文
评论