
我用Python爬取800只基金数据,发现……
作者:数据科学家联盟
来源:知乎
本文涉及到的知识点
网站分析
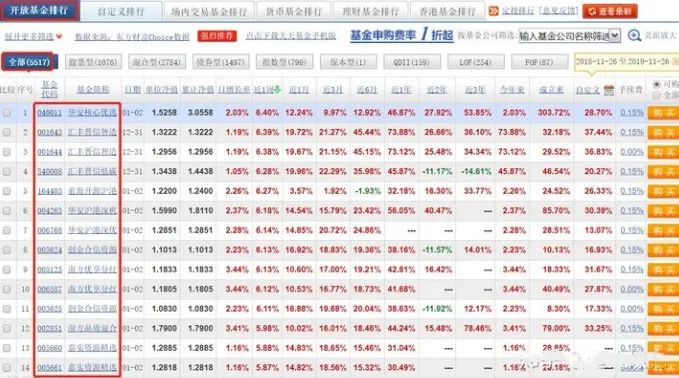
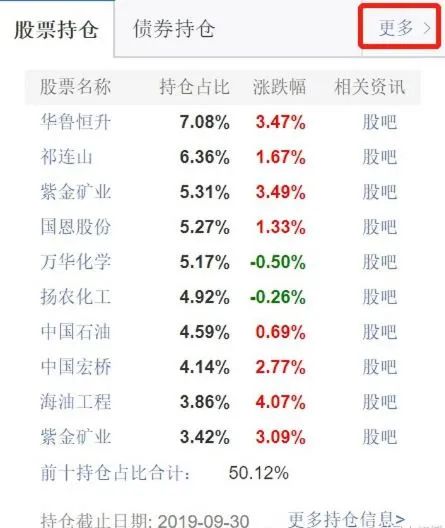
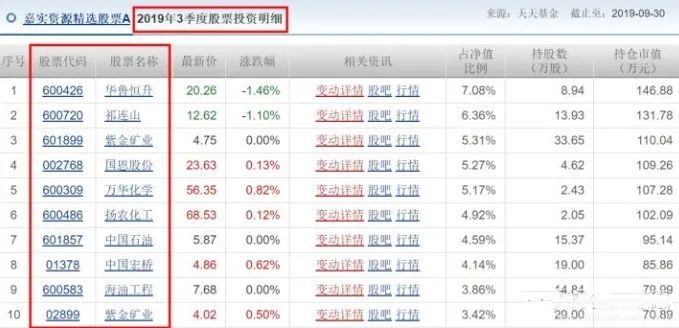
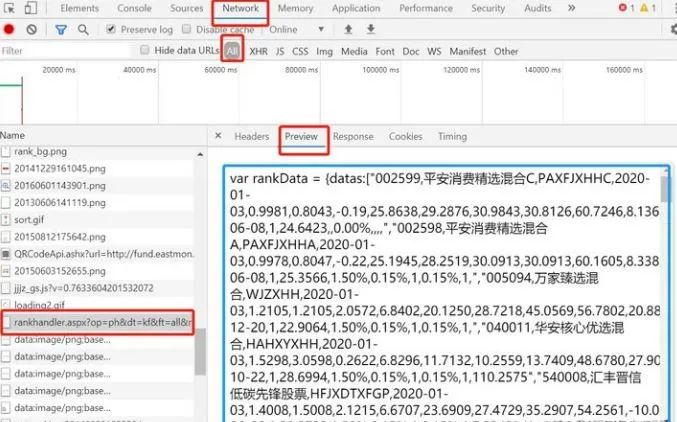
爬取流程
代码讲解——数据爬取
import re
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pymongo
def is_contain_chinese(check_str):
"""
判断字符串中是否包含中文
:param check_str: {str} 需要检测的字符串
:return: {bool} 包含返回True, 不包含返回False
"""
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
#selenium通过class name判断元素是否存在,用于判断基金持仓股票详情页中该基金是否有持仓股票;
def is_element(driver,element_class):
try:
WebDriverWait(driver,2).until(EC.presence_of_element_located((By.CLASS_NAME,element_class)))
except:
return False
else:
return True
#requests请求url的方法,处理后返回text文本
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
proxies = {
"http": "http://XXX.XXX.XXX.XXX:XXXX"
}
response = requests.get(url,headers=headers,proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
else:
print("请求状态码 != 200,url错误.")
return None
#该方法直接将首页的数据请求、返回、处理,组成持仓信息url和股票名字并存储到数组中;
def page_url():
stock_url = [] #定义一个数组,存储基金持仓股票详情页面的url
stock_name = [] #定义一个数组,存储基金的名称
url = "http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=zzf&st=desc&sd=2018-11-26&ed=2019-11-26&qdii=&tabSubtype=,,,,,&pi=1&pn=10000&dx=1&v=0.234190661250681"
result_text = get_one_page(url)
# print(result_text.replace('\"',',')) #将"替换为,
# print(result_text.replace('\"',',').split(',')) #以,为分割
# print(re.findall(r"\d{6}",result_text)) #输出股票的6位代码返回数组;
for i in result_text.replace('\"',',').split(','): #将"替换为,再以,进行分割,遍历筛选出含有中文的字符(股票的名字)
result_chinese = is_contain_chinese(i)
if result_chinese == True:
stock_name.append(i)
for numbers in re.findall(r"\d{6}",result_text):
stock_url.append("http://fundf10.eastmoney.com/ccmx_%s.html" % (numbers)) #将拼接后的url存入列表;
return stock_url,stock_name
#selenium请求[基金持仓股票详情页面url]的方法,爬取基金的持仓股票名称;
def hold_a_position(url):
driver.get(url) # 请求基金持仓的信息
element_result = is_element(driver, "tol") # 是否存在这个元素,用于判断是否有持仓信息;
if element_result == True: # 如果有持仓信息则爬取;
wait = WebDriverWait(driver, 3) # 设置一个等待时间
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'tol'))) # 等待这个class的出现;
ccmx_page = driver.page_source # 获取页面的源码
ccmx_xpath = etree.HTML(ccmx_page) # 转换成成 xpath 格式
ccmx_result = ccmx_xpath.xpath("//div[@class='txt_cont']//div[@id='cctable']//div[@class='box'][1]//td[3]//text()")
return ccmx_result
else: #如果没有持仓信息,则返回null字符;
return "null"
if __name__ == '__main__':
# 创建连接mongodb数据库
client = pymongo.MongoClient(host='XXX.XXX.XXX.XXX', port=XXXXX) # 连接mongodb,host是ip,port是端口
db = client.db_spider # 使用(创建)数据库
db.authenticate("用户名", "密码") # mongodb的用户名、密码连接;
collection = db.tb_stock # 使用(创建)一个集合(表)
stock_url, stock_name = page_url() #获取首页数据,返回基金url的数组和基金名称的数组;
#浏览器动作
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options) #初始化浏览器,无浏览器界面的;
if len(stock_url) == len(stock_name): #判断获取的基金url和基金名称数量是否一致
for i in range(len(stock_url)):
return_result = hold_a_position(stock_url[i]) # 遍历持仓信息,返回持仓股票的名称---数组
dic_data = {
'fund_url':stock_url[i],
'fund_name':stock_name[i],
'stock_name':return_result
} #dic_data 为组成的字典数据,为存储到mongodb中做准备;
print(dic_data)
collection.insert_one(dic_data) #将dic_data插入mongodb数据库
else:
print("基金url和基金name数组数量不一致,退出。")
exit()
driver.close() #关闭浏览器
#查询:过滤出非null的数据
find_stock = collection.find({'stock_name': {'$ne': 'null'}}) # 查询 stock_name 不等于 null 的数据(排除那些没有持仓股票的基金机构);
for i in find_stock:
print(i)
代码讲解——数据处理
import pymongo
#一、数据库:连接库、使用集合、创建文档;#
client = pymongo.MongoClient(host='XXX.XXX.XXX.XXX',port=XXXXX) #连接mongodb数据库
db = client.db_spider #使用(创建)数据库
db.authenticate("用户名","密码") #认证用户名、密码
collection = db.tb_stock #使用(创建)一个集合(表),里面已经存储着上面程序爬取的数据了;
tb_result = db.tb_data #使用(创建)一个集合(表),用于存储最后处理完毕的数据;
#查询 stock_name 不等于 null 的数据,即:排除那些没有持仓股票的基金;
find_stock = collection.find({'stock_name':{'$ne':'null'}})
#二、处理数据,将所有的股票数组累加成一个数组---list_stock_all #
list_stock_all = [] #定义一个数组,存储所有的股票名称,包括重复的;
for i in find_stock:
print(i['stock_name']) #输出基金的持仓股票(类型为数组)
list_stock_all = list_stock_all + i['stock_name'] #综合所有的股票数组为一个数组;
print("股票总数:" + str(len(list_stock_all)))
#三、处理数据,股票去重#
list_stock_repetition = [] #定义一个数组,存放去重之后的股票
for n in list_stock_all:
if n not in list_stock_repetition: #如果不存在
list_stock_repetition.append(n) #则添加进该数组,去重;
print("去重后的股票数量:" + str(len(list_stock_repetition)))
#四、综合二、三中的得出的两个数组进行数据筛选#
for u in list_stock_repetition: #遍历去重后股票的数组
if list_stock_all.count(u) > 10: #在未去重股票的数组中查找股票的重复数,如果重复数大于10
#将数据组成字典,用于存储到mongodb中;
data_stock = {
"name":u,
"numbers":list_stock_all.count(u)
}
insert_result = tb_result.insert_one(data_stock) #存储至mongodb中
print("股票名称:" + u + " , 重复数:" + str(list_stock_all.count(u)))
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62c9'), 'name': '水晶光电', 'numbers': 61}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62ca'), 'name': '老百姓', 'numbers': 77}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cb'), 'name': '北方华创', 'numbers': 52}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cc'), 'name': '金风科技', 'numbers': 84}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cd'), 'name': '天顺风能', 'numbers': 39}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62ce'), 'name': '石大胜华', 'numbers': 13}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cf'), 'name': '国投电力', 'numbers': 55}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d0'), 'name': '中国石化', 'numbers': 99}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d1'), 'name': '中国石油', 'numbers': 54}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d2'), 'name': '中国平安', 'numbers': 1517}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d3'), 'name': '贵州茅台', 'numbers': 1573}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d4'), 'name': '招商银行', 'numbers': 910}
总结
- EOF -
推荐阅读:
评论