
实践案例:用 Python 爬取分析每日票房数据

作者:小李子,某外企分析师,主要从事IT行业,但个人非常喜欢电影市场分析,所以经常会写一些电影领域的文章。
博客:http://blog.sina.com.cn/leonmovie
不知不觉又过了一年,挥别2019,让我们拥抱这全新的2020,祝各位新年快乐!
最近在处理一些和有关电影的工作,需要用到一些北美电影票房数据,而这部分数据最权威的网站当属Box Office Mojo(以下简称BOM),于是就上去查看了一下。估计经常关注这个网站的盆友们都知道,这个网站最近刚刚进行了改版,网页排版全面更新,还专门针对移动设备进行了优化(以前的网站页面只有电脑版的),页面虽然好看了不少,但却少了很多数据,之前的网站几乎所有数据都能查到,而现在则只能查到部分数据,有些数据则要到BOM Pro版才能查到,而这个服务是收费的。为了更好地使用数据,还想不花钱,那就只有自己动手丰衣足食,所以笔者就自己写了个Python爬虫,爬取了过去多年的票房数据。以下就以“北美票房每日票房数据”为例,介绍一下如何爬取,其他票房数据类似,只需修改少数代码即可。
图一 要抓取的部分网页的截图
这个爬虫程序完全采用Python语言完成,使用软件为Anaconda 2019.10版(这个目前是最新版的,理论上其包含的各种Python库也是最新的或接近最新的,所以下面的爬虫程序在部分老版软件上可能会出问题,如有问题请及时更新)。爬虫程序主要包括两部分:爬取并存储数据,以及根据数据简单绘制图片。下面就一一讲解一下。
一、爬取和存储数据
首先把需要的包都导入进来。
import requests
import pandas as pd
import time
import matplotlib.pyplot as plt
import matplotlib.dates as mdate
import pylab as mpl # 导入中文字体,避免显示乱码
urltemplate = r'https://www.boxofficemojo.com/daily/%s/?view=year'
这个是数据保存的地方,放在了桌面的一个Excel文档中,因为数据很少,所以根本用不到数据库,Excel足以,当然这里也可以用CSV格式。这里我的路径中包含中文,使用时没有问题,如果大家出现问题,最好使用英文路径。
fileLoc = r'C:\Users\leon\Desktop\BoxOffice\Box Office Mojo票房爬虫\Daily-每日\daily-data.xlsx'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
下面是爬虫主体部分,这里有三点要说明,一是mode='a'这里,这个是0.25.1版pandas以后才有的功能,之前的老版本没有这个功能;二是,不知道是不是我的网络有问题,在爬取过程中有掉线的现象出现,所以在这里用了requests.ConnectionError来处理掉线问题;三是,用了一个小窍门,如果直接用pd.read_html(url)也可以读取网页中的数据,但这里先用requests读取网页,再把requests读取的网页代码放入pd.read_html中,这样既可避免网站的反爬虫机制,也可以加快读取速度,因为pd.read_html直接读取网页实在太慢了。
def scraper(file, headers, urltemp, year_start, year_end):
writer = pd.ExcelWriter(file, engine='openpyxl', mode='a') # 笔者用的文件是xlsx类型,所以这里要指定engine='openpyxl',如果是xls类型,则不用
for i in range(year_start, year_end+1):
url = urltemp % i
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
source_code = r.text
df = pd.read_html(source_code)
df = df[0]
df.to_excel(writer, sheet_name=str(i), index=False)
time.sleep(3)# 稍微放慢一下速度,别把人家网站累坏了
except requests.ConnectionError:
print('Can not get access to the %s year daily data now' % i)
return
writer.save()
writer.close()
scraper(fileLoc, headers, urltemplate, 1977, 2019)
因为网站只提供到最早1977年的数据,所以就把1977年到2019年数据都给抓下来。
图二 抓取的部分数据的截图
二、根据数据简单绘图
下面这个str_to_datetime函数,是除掉数据Date列中一些不必要的文字,比如有些数据带有“New Year’s Eve”字样,要把这些东西去掉
def str_to_datetime(x):
if len(x) > 14:
temp = x.split('2019')
x = temp[0]+'2019'
return x
这个str_to_num函数是把“Top 10 Gross”列的数据都转换成数值,因为这些数据从Excel读取到pandas后,都是string格式的数据,要转换成数值格式
def str_to_num(x):
x = x.replace('$', '')
x = x.replace(',', '')
x = int(x)
return x
在这里我们要做一个“2019年每日票房数据的线形图”,所以要在刚才抓取的文件中读取相应数据,并简单处理一下
table = pd.read_excel(fileLoc, sheet_name='2019')
data = table[['Date', 'Top 10 Gross']]
data['Date'] = data['Date'].apply(str_to_datetime)
data['Top 10 Gross'] = data['Top 10 Gross'].apply(str_to_num)
设置x轴和y轴的数据,x轴是时间数据,y轴是票房数据,其值太大,所以改小点,方便作图
x = pd.to_datetime(data['Date'])
y = data['Top 10 Gross']/1000000
找出票房数据中最大的那个值和其在序列y中的位置,然后找出对应x序列的位置,也就是对应的哪一天
max_loc = y.idxmax()
max_y = y.max()
max_date = x.loc[max_loc]
设置相关参数
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置为黑体字
fig = plt.figure(figsize=(16, 6.5))
ax = fig.add_subplot(111) # 本例的figure中只包含一个图表
ax.set_ylim([0, 200])
plt.tick_params(labelsize=13)
下面这行代码是设置x轴为时间格式,这点很重要,否则x轴显示的将是类似于‘796366’这样的转码后的数字格式
ax.xaxis.set_major_formatter(mdate.DateFormatter('%Y-%m-%d'))
plt.xticks(pd.date_range(x[len(x)-1], x[0], freq='M'), rotation=90)
text = r'票房最高的一天是%s,其票房为%.2f亿' % (max_date.date(), max_y/100)
plt.annotate(text, xy=(max_date, max_y), fontsize=14, \
xytext=(max_date+pd.Timedelta(days=10), max_y+10), \
arrowprops=dict(arrowstyle="->", connectionstyle="arc3"), \
xycoords='data')
plt.ylabel('票房/百万美元', fontdict={'size':14})
plt.plot(x, y)
完成后这个图片效果如下
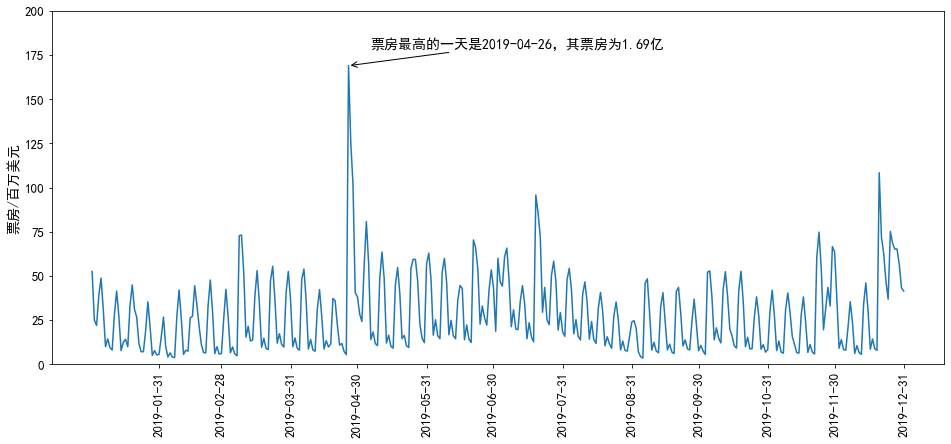
图三 2019年北美票房每日数据图
三、结语
上面这个爬虫程序比较简单,并没有用到数据库、多线程等复杂技术,我们更多地应该从所得到的数据中来挖掘更多的价值,笔者接下来会从这些数据中来分析一下好莱坞电影行业过去一年的发展,届时会分享给大家,敬请期待。