来源:arXiv
编辑:好困
【新智元导读】非对比自监督学习一直存在着几个基本理论问题:如何避免表征崩溃?学习到的表征的性质是什么?近日,田渊栋团队首次对模型训练的行为以及多个超参数的经验效应进行了分析,并提出了极为简单的预测器设置方法,论文已经被ICML 2021接收。
自监督学习 (SSL) 的对比方法通过最小化同一数据点(positive pairs)的两个增强视图之间的距离,和最大化不同数据点(negative pairs)的视图之间的距离来学习表征。
最近BYOL和SimSiam的非对比自监督学习方法在没有negative pairs的情况下也能表现出卓越的性能。
那么,为什么这些方法没有造成表征崩溃?
近期,田渊栋团队发表了一篇论文对这个问题进行了讨论,并且已经被ICML 2021接收。

https://arxiv.org/abs/2102.06810
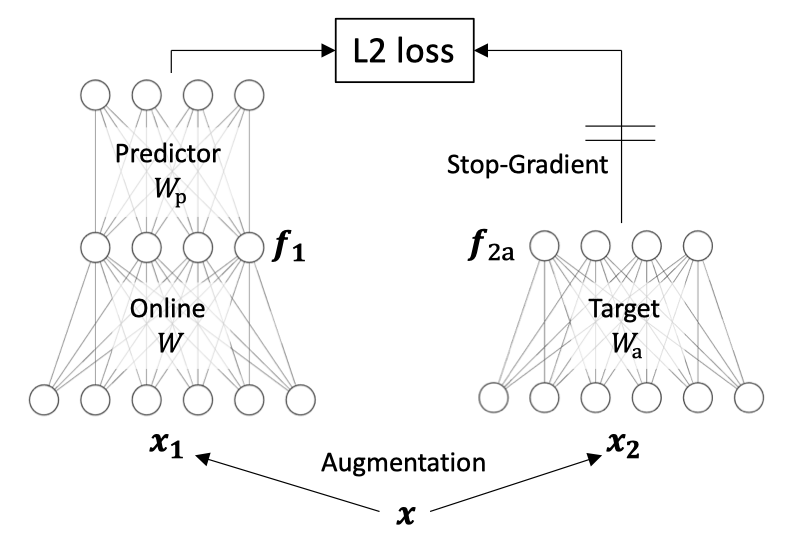
作者受到简单线性网络中非线性学习动态的启发,提出了一种新方法DirectPred,它根据输入的统计数据直接设置线性预测器,而无需梯度训练。
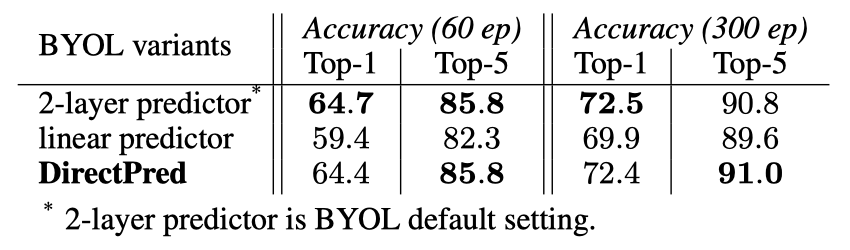
在ImageNet上,DirectPred的性能与使用BatchNorm的双层非线性预测器相当,并且在300个epoch的训练中比线性预测器强2.5%,在60个epoch的训练中强5%。
在本文中,作者首次尝试分析非对比自监督学习训练的行为以及多个超参数的经验效应:
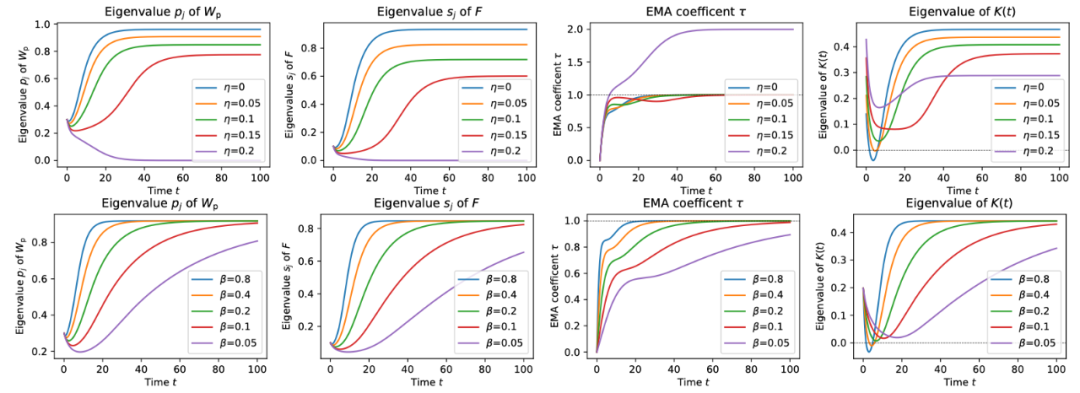
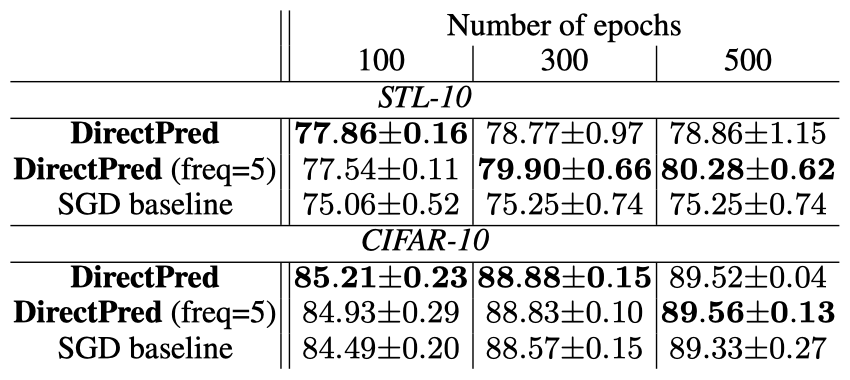
预测器和停止梯度的存在是绝对必要的。去掉它们中的任何一个都会导致BYOL和SimSiam的表征崩溃。虽然最初的BYOL需要EMA来工作,但他们后来证实,如果使用较高的αp,EMA是不必要的(即在线和目标网络可以是相同的)。SimSiam也证实了这一点,只要预测器更新得更频繁或有更大的学习率(或更大的αp)。然而,其性能略低。BYOL和SimSiam都表明,预测器应该始终是最优的,即在预测目标网络的输出时,总是能从在线网络的输出中获得最小的L2误差。当预测器具有较大的学习率并允许比网络的其他部分更频繁的更新时,会具有卓越性能。然而,这也表明,如果预测器的更新过于频繁,那么性能就会下降,这就对预测器始终处于最佳状态作为学习良好表征的关键要求的重要性提出质疑。BYOL表明权重衰减不会导致结果不稳定。使用权重衰减可以在 BYOL 中实现稳定学习。DirectPred直接根据预测器输入的主成分分析来设置预测器的权重,从而避免了复杂的预测器动态和初始化问题。这种简单的DirectPred方法在CIFAR-10中产生了相当不错的性能,并且在STL-10和ImageNet(60个epoch)的线性评估协议中,比线性预测器的梯度训练的精度高5%。在标准的ImageNet基准(300个epoch)上,DirectPred取得了72.4%/91.0%的Top-1/Top-5,比使用线性预测器的BYOL(69.9%/89.6%)高2.5%,与使用双层预测器的BYOL默认设置(72.5%/90.8%)相近。对于BYOL和SimSiam来说,存在一种「平衡」,确保在线和目标表征之间的任何匹配不会仅仅归因于预测器的权重,从而使在线权重毫无用处。在多层线性网络和矩阵分解中已经发现了类似的权重平衡动态,而作者将其推广到自监督学习动态。此外,非零权重衰减可以帮助消除初始化导致的额外常数C,进一步平衡预测器和在线网络的权重,会使下游任务有更好的表现。简单地将「最佳解决方案」插入线性预测器,BYOL在100个epoch后表现不佳。相比之下,使用梯度下降法,单一线性层预测器的BYOL在100个epoch后可以达到STL-10中74%-75%的Top-1。作者提供了一种选择预测器的新方法,可以完全避免梯度下降。估计预测器输入的相关矩阵F并直接设置Wp为其函数,从而避免需要通过优化对齐F和Wp的特征空间,以及Wp的崩溃。与基于梯度的线性预测器优化相比,这种非常简单的理论驱动方法在实践中也产生了更好的性能。在模拟解耦动力学的合成实验上对Wp应用对称正则化时,权重衰减η和EMA β发挥的作用。在学习率α=0.01时,这两个条件都将K(t)的特征值提高到0以上,这样就可以实现特征空间对齐,但也有不同的权衡。β=0.4,所以αβ=0.004=1-γa,其中γa=0.996。第一行:权重衰减η。大的η会提高K(t)的特征值,但会大大降低最终收敛的特征值pj和sj(即最终特征不突出),甚至将它们降到0(没有进行训练)。第二行:指数移动平均线β。小的β也能提升K(t)的特征值,但训练收敛的速度要慢得多。通过引入freq来进行评估,也就是对矩阵F进行特征分解以设定Wp的频率。例如,freq=5意味着每5个minibatches就进行一次特征分解。结果表明,通过DirectPred直接计算Wp(76.77%)比通过梯度下降训练效果更好(74.51%)。此外,通过额外的正则化可以获得更好的效果(77.38%)。而估算F的不同方法(移动平均或简单平均)只产生很小的差异。使用DirectPred在BYOL训练100个epoch之后的STL-10的Top-1精度DirectPred在训练了更多的epochs之后也保持良好的性能。如果直接设置Wp之间允许一些梯度步骤(即freq>1),性能可以更好(80.28%)。出现这种情况可能是因为估计的F不够准确,而SGD进行了纠正,这同时也减轻了特征分解的计算成本。使用DirectPred经过更长时间训练的STL-10/CIFAR-10的Top-1精度如果cj是较小的负数,性能仍然很好,但如果cj为正会导致性能很差,这可能是由于许多小的特征值sj变为零。BYOL训练100个epoch后STL-10的Top-1精度
使用两层预测器的优点之一是Wp可以取决于输入特征。作者通过使用输入空间的几个随机分区对此进行了探索。在每个随机分区中,估计了不同的相关矩阵F,而最终的F是所有相关矩阵的总和。通过6个随机分区,DirectPred在100个epoch之后达到78.20±0.16的Top-1精度,缩小了与双层预测器(78.85%)的差距。作者以ResNet-50作为骨干来产生线性探针的特征。架构设计(如特征维度)、增强策略(如颜色抖动、模糊等)和线性分类协议遵循BYOL。作者实验了两种不同的训练设置来研究DirectPred的泛化能力:采用非对称损失,其中,损失使用标准SGD优化60个epoch,批大小为256。
采用对称损失、4096批大小和LARS优化器,并训练了300个epoch。
作为基线,BYOL的双层预测器(使用BatchNorm和ReLU,4096个隐藏维度,256个输入/输出维度)在300个epoch的预训练中取得了72.5%的Top-1精度,90.8%的Top-5精度。相比之下,DirectPred可以在没有任何基于梯度的训练时,通过直接设置每个小批次(256×256)的线性预测器权重来达到这个性能(72.4% top1,91.0% top5)。为了进行公平的比较,作者也采用了经过学习的线性预测器来运行BYOL。然而,其性能分别下降到69.9%和89.6%。在60个epoch时差距更大,在top-1中高达5.0%(59.4% vs. 64.4%)。这些实验证明了DirectPred在STL10和CIFAR上的成功也可以推广到ImageNet。DirectPred与BYOL在没有基于梯度的训练的情况下,在ImageNet中的比较作者主要围绕着三维非线性动态系统,对非对比自监督学习的理论进行了分析。不仅产生了对复杂成分的功能作用的概念性见解,如EMA、停止梯度、预测器、预测器对称性、不同的学习率、权重衰减以及所有的相互作用。而且还预测了许多消融研究的性能模式,并提出了一种极其简单的DirectPred方法,在现实世界中可以与更复杂的预测器动态性能相媲美。在只有一个线性预测器的情况下,DirectPred在ImageNet上的结果已经显示出强大的性能,与ImageNet上双层预测器的默认BYOL设置相当。田渊栋,Facebook人工智能研究院研究员、研究经理,卡耐基梅隆大学机器人系博士。Xinlei Chen,Facebook人工智能研究院研究员。
参考资料:
https://arxiv.org/abs/2102.06810