
自监督学习效果差?Meta AI 提出 Q-score 快速过滤错误样本!

极市导读
有没有什么灵丹妙药可以缓解自监督模型在下游任务中出现分错类的情况呢?最近 meta AI 的一篇工作研究了自监督模型在下游任务错误分类的原因,并且提出了缓解这一问题的方法,让我们一起来看看吧 >>加入极市CV技术交流群,走在计算机视觉的最前沿
自监督学习指的是不依靠人工标注数据,直接从数据中学习到有用的特征表示。自监督学习中所采用的监督信息可以是“是否属于同一实例样本”的二分类标签对比学习,也可以是一段连续的自然语言文本的下一个词(自回归语言模型)。
然而自监督学习相关的论文看多了,感觉也就那么回事。除了可以减少对标注数据的依赖,下游任务中该分错类的case,照样会分错类。•᷄ࡇ•᷅

那么究竟有没有什么灵丹妙药可以缓解自监督模型在下游任务中出现分错类的情况呢?
最近 meta AI 的一篇工作研究了自监督模型在下游任务错误分类的原因,并且提出了缓解这一问题的方法,让我们一起来看看吧。

论文标题:
Understanding Failure Modes of Self-Supervised Learning
论文链接:
https://arxiv.org/pdf/2203.01881.pdf
自监督模型下游错误分类的潜在原因
为了研究自监督模型学习到的特征表示中哪些特征可以有助于下游任务的正确分类,作者用 ImageNet-100 预训练了 SimCLR 模型作为 baseline ,并且在学习到的特征表示后面接了个线性分类器用于下游任务的分类。
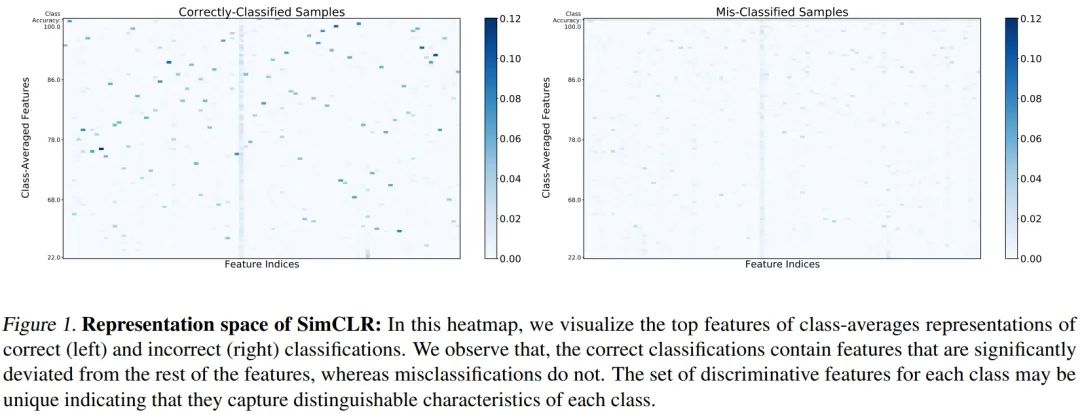
图1 是训练学到的 ImageNet-100 中每个类的平均特征表示(部分特征),其中每个类是按照该类别的分类准确度(acc)排序的。图中用颜色深浅表示平均特征表示的值的绝对大小,左边是在下游任务中可以被正确分类的样本,右边是错误分类的样本的平均特征表示。
可以看到,
表征空间几乎是稀疏的,每个类的大部分特征都接近0; 在正确分类的样本中,每个类的平均特征表示都有十分明显的几个特征,这些特征是类别所独有的,不同类别的可区分特征都不一致,且不同类别的可区分特征有着高度的差异性,而这一点在错误分类的样本中并不明显,错误分类的样本其特征表示没有明显突出变化较大的特征; 在所有样本中都存在或者都激活的特征不太可能是下游任务中用于区分某个类别的特征。
为了研究单个特征对分类正确与否的影响,作者进一步绘制了主要特征和噪声特征的热图,如下所示:

可以看到对于正确分类的样本,主要特征能够捕捉到类别相关的特征,而分类错误的样本,主要特征则包含了太多的噪音和错误的信息;噪声特征的热图则侧重于样本中无信息的部分。因此,作者指出特征表示中包含了很多噪声特征,这些特征对正确分类没有太多的贡献。
综上所述,作者指出了错误分类的两个原因:
训练得到的特征表示中缺少类别特定的主要特征; 主要特征映射到了样本中错误的部分
基于上述几点,作者希望可以通过利用特征表示的特点用无监督的方式对特征表示进行分类,而不需要下游任务中的标签。
自监督表征的质量指标
为了衡量自监督模型学到的特征表示的质量,作者定义了一系列质量指标。
假定一个 SimCLR 模型, 由 ResNet 基本编码器 (base encoder, 记作 ) 和多层感知机 投影层(记作 ) 组成。 和 是 个数据样本中的第 个样本的两种变换表 示, 这里作者用到的数据增强方式是随机裁剪、随机水平翻转等方式的组合。与 SimCLR 类 似, 将样本输入基本编码器, 分别得到自监督模型的特征表示 和 , 用投影层的输出 和 来计算损失函数和训 练模型, 其中 和 分别是表征空间和投影空间的维度大小。模型的优化目标是:
其中, 是模型参数,
因为 会应用到下游任务, 为评估特征表示的好坏, 作者给出了以下几个质量指标:
均值 :计算每一个特征表示 的均值, 即 标准差 : 计算每一个特征表示 的标准差 软稀疏性(Soft Sparsity):计算 中特征小于 的百分占比, 其中, 范数 : 计算每一个特征表示 的 范数, 即 的 分数:逐元素地计算 中最大值并计算 分数, 即
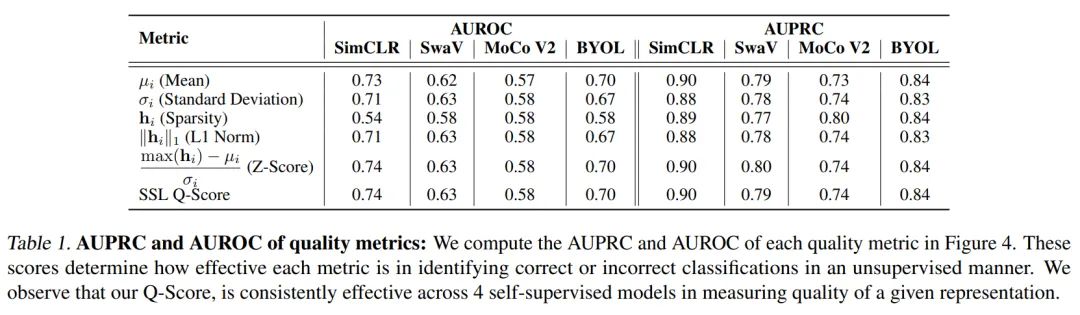
为评估以上指标在衡量下游任务中分类效果的好坏,作者研究并绘制了多个sota自监督模型(包括SimCLR、 SwaV、MoCo V2和BYOL)的特征表示关于上述指标的ROC(receiver operating characteristic)曲线和PR曲线。此外,作者还计算了相应的AUROC(ROC曲线下的面积)和AUPRC(PR曲线下的面积)。
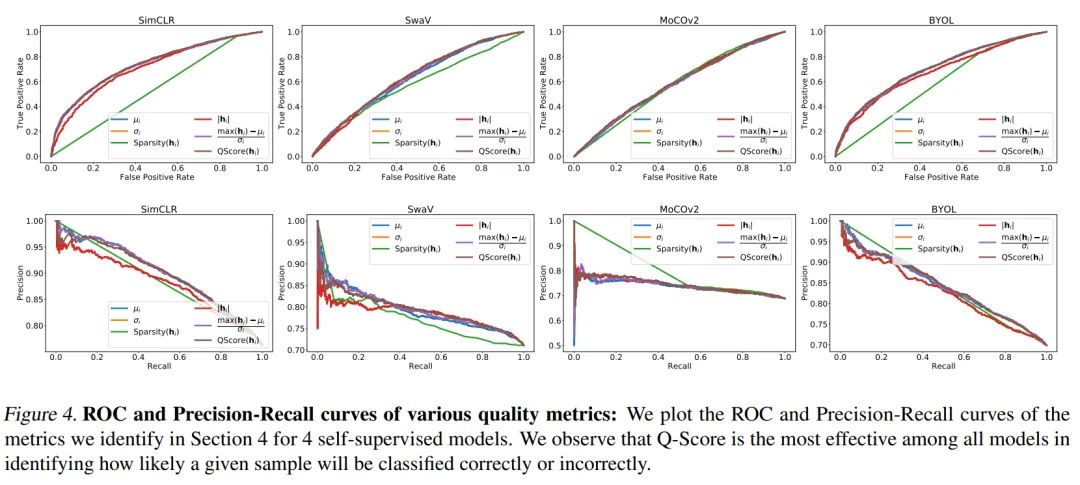
可以看到, L1范数 和 的 分数在各个模型上面都有较为一致的表现, 作者进 一步可视化了 ImageNet-100 中5000个样本的 范数和 分数。
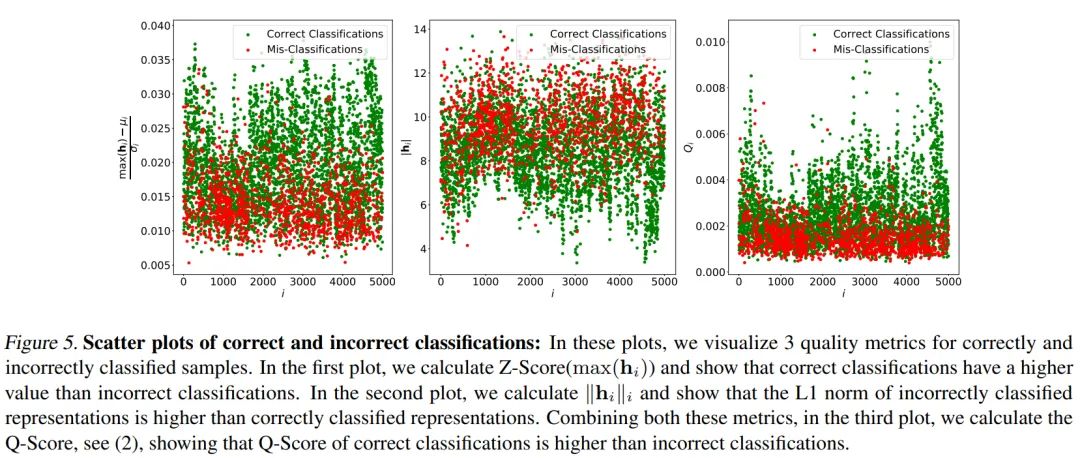
可以看到, 分类正确的样本的 分数普遍高于分类错误的样本, 而 范数则普遍低于分类错 误的样本。
自监督分数
根据前面的实验结果, 作者设计了评判特征表示能否容易在下游任务分类正确的质量指标 分数。第 个样本的 分数定义如下:
分数既能衡量出特征表示的稀疏性(由 计算得到), 又可以判单表示中是否有较高的 偏差值的特征(由 -Score ) 计算得到)。图 4 和表 1 都展示了作者提出的 分数的性能, 可以看出 分数在识别下游任务中是否分类正确的特征表示上确实效果明显。
此外, 作者还将 分数应用到正则项上面, 用于改善自监督模型特征表示的质量
其中, 是用于选择 分数过小的样本的阈值, 是正则项系数
上述公式是常见的正则化公式,但作者指出了这种目标函数会导致特征表示中的某个特征在所有样本中都被激活的情况出现,使得下游任务中很难正确分类,如下图所示:
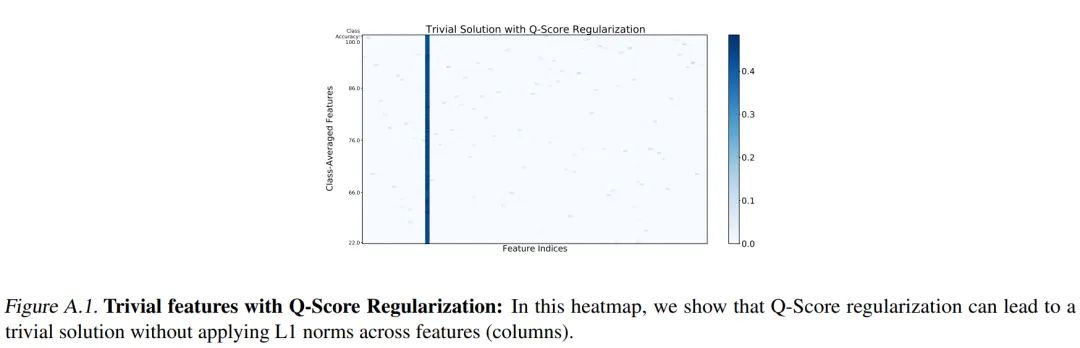
为避免这种情况,作者提出了修改后的带正则化的优化目标:
其中, 是特征表示, 是所有特征表示的第 个特征(按列)的L1范数, 是阈值
实验
准确率
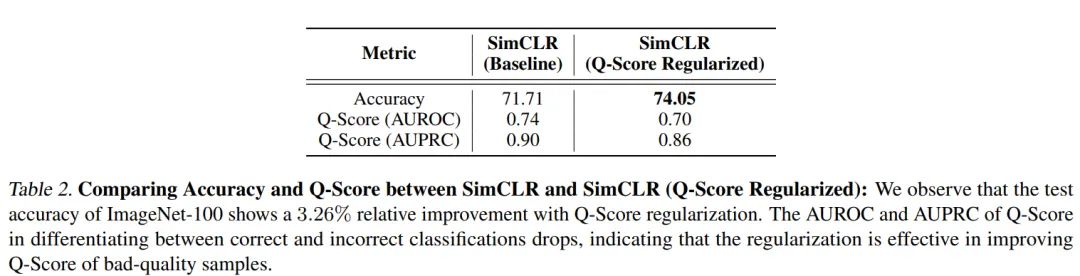
作者将上述分数正则化应用到用 ImageNet-100 预训练的 SimCLR 模型上,正如下表所示,下游分类任务获得了 3.26% 的相对acc提升
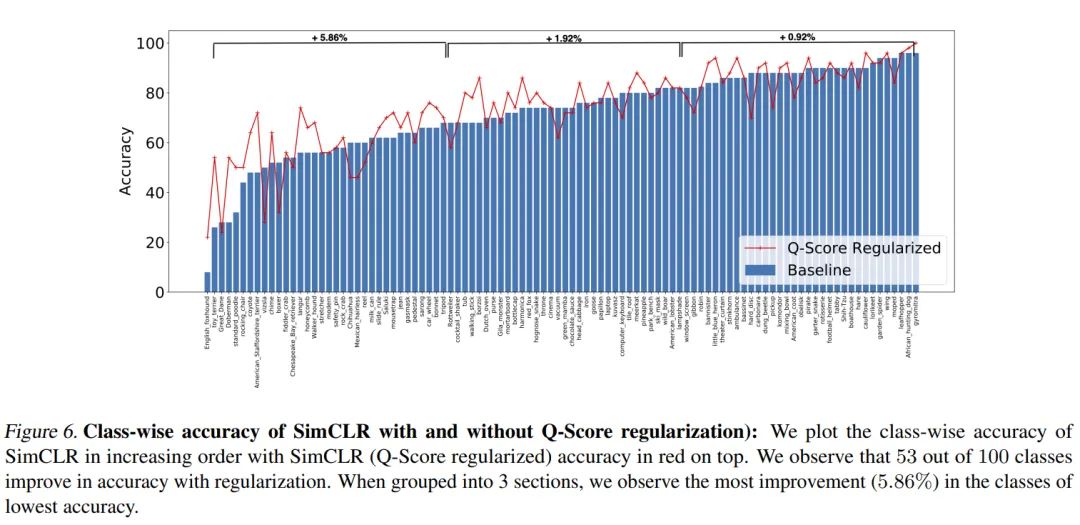
作者还展示了在应用 分数正则化前后每一类的acc变化, 发现在 ImageNet-100 的某些类 中, 应用了 分数正则化后, 其acc比没有应用 分数正则化有明显提高, 而某些类会有些下降, acc下降的这些类多是动物超类, 这些类别的特征表示存在很多共同特征, 比较容易分错类, 而应用 分数正则化则进一步放大了错误的特征, 促使在下游任务中分错类。
特征表示
作者展示了分数正则化后的自监督模型的特征表示,如下所示:
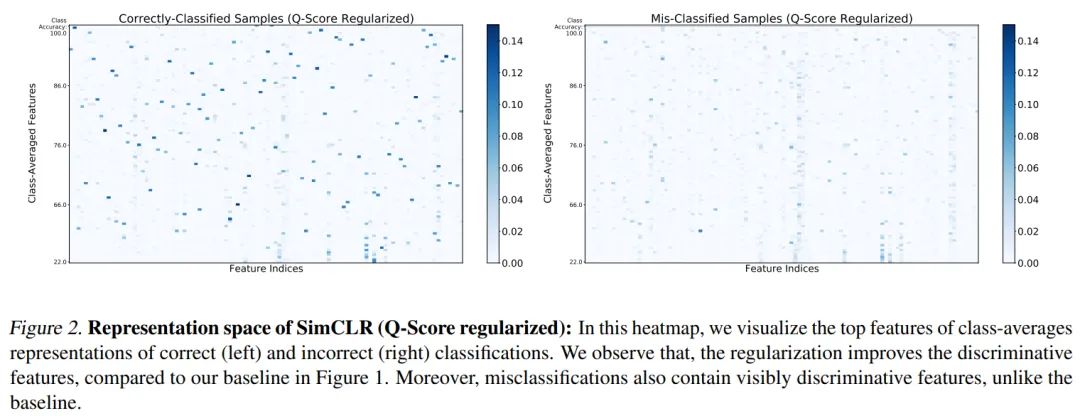
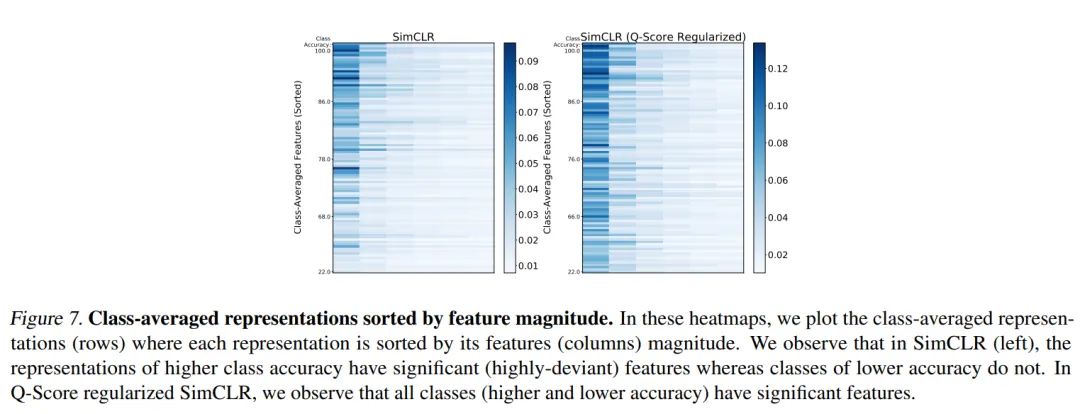
和没有用 分数正则化的特征表示(图 1 ) 相比, 图 2 的特征表示中的主要特征更加明显;图 7 显示的没有区分分类正确与否的类平均特征表示, 其中的特征有了明显清晰的区分; 在 表 2 中, 作者给出了使用 分数正则化前后的AUROC和AUPRC的对比, 可以看到, 使用 分数正则化后, 这两个指标都有明显的下降。以上都证明了 分数正则化的有效性。
可解释性
自监督模型的表示空间是稀疏的,大部分特征都接近于0,而这些接近于0的特征几乎在所有样本中都激活,属于噪音特征。作者展示了应用分数正则化前后的特征表示稀疏度的对比,如下所示:
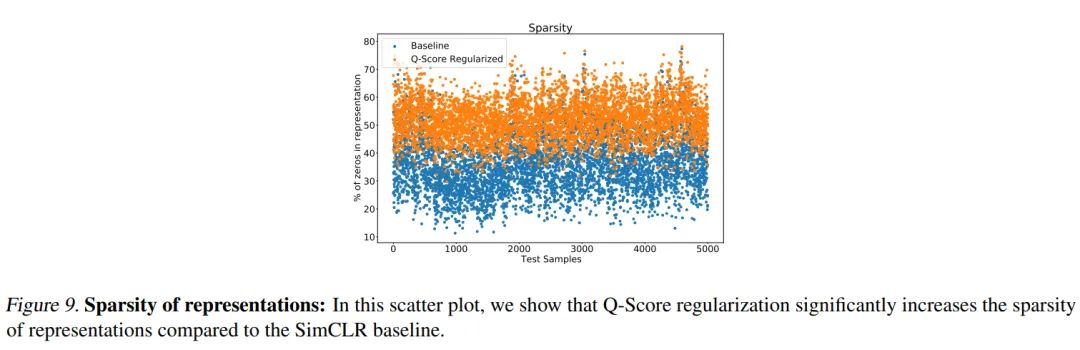

可以看到,应用分数正则化后,特征表示的平均稀疏度从35%增加到52%,正因为剔除了这些噪音特征,使得特征表示的可解释性得到了提升。
总结
作者提出的分数可以在无监督的方式下预估自监督模型得到的特征表示在下游任务中正确分类的可能性,同时分数正则化也可以一定程度上改善低质量的特征表示,有助于提高下游任务的分类准确率。
但是,从论文中看到,作者貌似是用自监督模型学习到的特征表示,或者冻结模型参数,或者直接使用特征表示,用于下游任务的分类。在nlp领域,尤其是大规模预训练语言模型上,一般是fine tuning下游任务,不清楚作者提出的思路在fine tuning上面是否也work呢?

公众号后台回复“96”获取NTIRE2022冠军方案直播链接~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
