
时隔两年,EfficientNet v2来了!更快,更小,更强!

极市导读
谷歌在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制,组合得到了EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

paper: https://arxiv.org/abs/2104.00298
code: https://github.com/google/automl/efficientnetv2
本文是谷歌的MingxingTan与Quov V.Le对EfficientNet的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制。两种改进的组合得到了本文的EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。比如EfficientNetV2取得了87.3%的top1精度且训练速度快5-11倍。
Abstract
本文提出一种训练速度更快、参数量更少的卷积神经网络EfficientNetV2。我们采用了训练感知NAS与缩放技术对训练速度与参数量进行联合优化,NAS的搜索空间采用了新的op(比如Fused-MBConv)进行扩充。实验表明:相比其他SOTA方案,所提EfficientNetV2收敛速度更快,模型更小(6.8x)。
在训练过程中,我们可以通过逐步提升图像大小得到加速,但通常会造成性能掉点。为补偿该性能损失,我们提出了一种改进版的渐进学习方式,它自适应的根据图像大小调整正则化因子,比如dropout、数据增广。
受益于渐进学习方式,所提EfficientNetV2在CIFAR/Cars/Flowers数据集上显著优于其他模型;通过在ImageNet21K数据集上预训练,所提模型在ImageNet上达到了87.3%的top1精度,以2.0%精度优于ViT,且训练速度更快(5x-11x)。
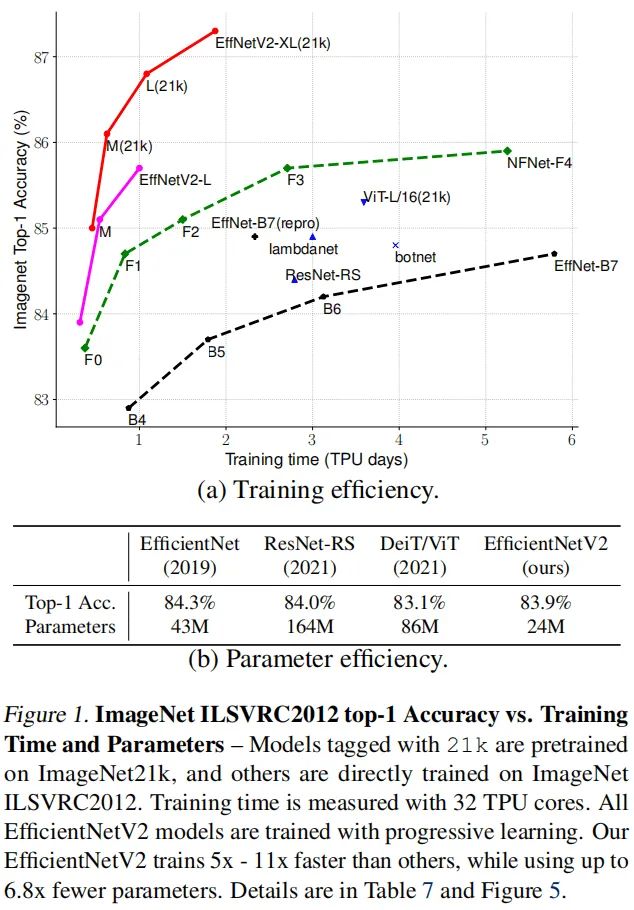
上图给出了所提方法与其他SOTA方案在训练速度、参数量以及精度方面的对比。本文的主要贡献包含以下几点:
提出一类更小、更快的卷积神经网络EfficientNetV2。受益于训练感知NAS与缩放,EfficientNetV2在训练速度与参数量方面显著优于其他方案; 提出一种改进版渐进学习策略,它可以自适应的随图像大小而调整正则化因子。它可以在加速训练的同时提升精度; 所提方案在ImageNet、CIFAR、Cars、Flowers等数据集上取得了11x更快的训练速度,6.8x更少的参数量。
Method
在正式介绍EfficientNetV2之前,我们先简单看一下EfficientNet;然后引出训练感知NAS与缩放,以及所提EfficientNetV2.
Review of EfficientNet
EfficientNet是2019年的一篇文章,它针对FLOPs与参数量采用NAS搜索得到EfficientNet-B0,然后通过复合尺度缩放得到了更大版本的模型,比如EfficientNetB1-B7。

上表给出了EfficientNet与其他方法在精度、参数量以及Flops方面的对比。本文旨在提升模型的训练速度同时保持参数的高效性。
Understanding Training Efficiency
我们对EfficientNetV1的模块进行了研究并得到了集中简单的训练加速技术。
Training with very large image sizes is slow。已有研究表明:EfficientNet的大图像尺寸会导致显著的内存占用。由于GPU/TPU的总内存是固定的,我们不得不采用更小的batch训练这些模型,这无疑会降低训练速度。一种简单的改进方式是采用FixRes,即采用更小的图像尺寸进行训练。如下表所示:采用更小的图像块会导致更小的计算量、更大的batch,可以加速训练(2.2x);与此同时,更小的图像块训练还会导致稍高的精度。在后续章节中,我们会提出一种更先进的训练方法:通过渐进式调整图像尺寸和正则化因子达到训练加速的目的。

Depthwise convolutios are slow in early layers。EfficientNet的核心模块采用了depthwise卷积,它具有更少的参数量和计算量(但往往无法充分利用现有加速器)。近来,提出的Fused-MBConv可以更充分的利用手机/服务端的加速器。它采用常规卷积替换了MBConv中的深度卷积与 卷积,见下图。
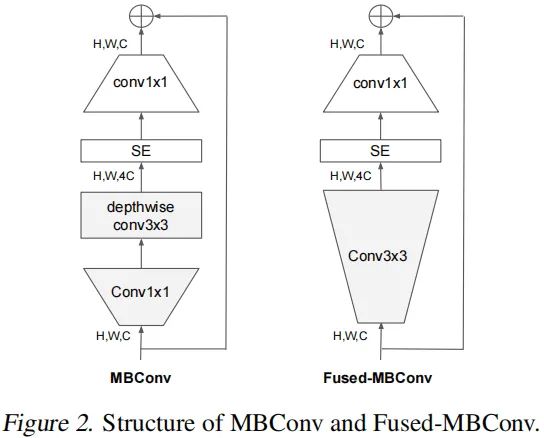
为系统的比较这两个模块,我们基于EfficientNet-B4,采用Fused-MBConv替换原始的MBConv,性能对比见下表。可以看到:(1) 在stage1-3阶段替换时,Fused-MBConv可以加速训练并带来少量的参数量与FLOPs提升;(2) 如果stage1-7全部替换,它会带来大量的参数量与FLOPs提升且降低训练速度。也就是说:MBConv与Fused-MBConv的正确组合并不容易直接确定,因此我们采用NAS搜索最佳组合。

Equally scaling up every stage is sub-optimal。EfficientNet采用复合测试对所有stage均衡缩放。比如当depth系数为2时,网络的所有阶段的层数加倍。然而,不同阶段在训练速度与参数量方面并非均等贡献。我们将采用非均匀缩放策略对后面的stage添加更多的层。此外,针对EfficientNet的采用大尺寸图像导致大计算量、训练速度降低问题,我们对缩放规则进行了轻微调整并约束最大图像尺寸到稍小值。
Training-Aware NAS and Scaling
至此,我们得到了多种加速训练的设计方案。为更好的组合这些方案,我们提出了一种训练感知NAS。
NAS Search。我们这里采用的NAS框架主要是基于EfficientNet与MnasNet,但对参数量与训练高效性同时进行优化。具体来说,我们采用EfficientNet作为骨干网络,搜索空间为类似EfficientNet的基于stage的空间,它包含MBConv、Fused-MBConv等卷积操作,层数、核尺寸、扩展比例;另一方面,我们通过这两种策略降低搜索空间:(1)移除不避免的搜索选项,比如pooling算子;(2) 复用EfficientNet中的通道数信息。由于搜索空间更小,我们可以采用简单的随机搜索进行更大网络的搜索(比如大小类似EfficientNet-B4)。具体来说,我们采样1000个模型,每个模型训练10个epoch。搜索奖励包含模型精度A、归一化训练时长S、参数量P,并通过加权方式组合 。
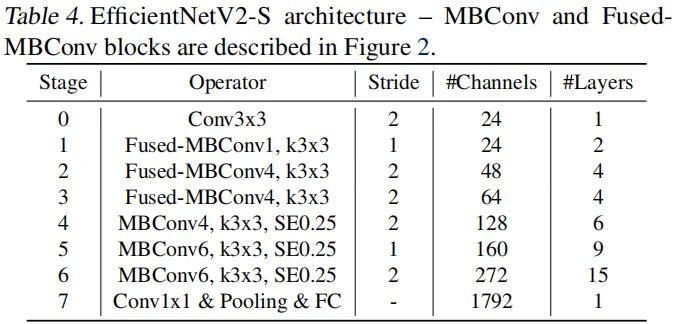
EfficientNetV2 Architecture。上表给出了所搜索到的EfficientNetV2-S的架构信息。相比EfficientNet,它有这样几个不同: EfficientNetV2大量利用了MBConv与Fused-MBConv(主要在网络早期); EfficientNetV2使用了更小的扩展比例,导致了更少的内存占用; EfficientNetV2倾向于选择更小的卷积核,用更多的层补偿感受野的减小; EfficientNetV2移除了EfficientNet中最后的stride-1 stage。 EfficientNet Scaling。我们在EfficientNetV2-S的基础上采用类似EfficientNet的复合缩放(并添加几个额外的优化)得到EfficientNetV2-M/L。额外的优化描述如下: 限制最大推理图像尺寸为480; 在网络的后期添加更多的层提升模型容量且不引入过多耗时,可见上表中的stage5与stage6.

Training Speed Comparsion。上表给出了不同网络的训练速度对比(所有摩西那个采用相同的图像大小)。我们发现:(1) 当训练合理时,EfficientNet仍可以得到非常好的性能均衡;(2) 相比其他方法,EfficientNetV2训练速度更快。
Progressive Learning
正如前面所提到:图像尺寸对于训练速度影响很大。除了FixRes外,还有其他方法在训练过程中动态改变图像尺寸,但通常造成了精度下降。
我们认为:上述精度下降主要源自不平衡的正则化因子,也就是说:当采用不同的图像尺寸训练时,我们应当同时调整正则化强度。事实上,大的模型需要更强的正则化以避免过拟合,比如EfficientNet-B7采用了更大的dropout核更强的数据增广。在这里,我们认为:对于相同模型,
小的图像尺寸会导致更小的模型容量,因此需要弱化版正则因子; 大的图像尺寸导致更多的计算量和模型容量,需要更强的正则因子以避免过拟合。

为验证上述假设,我们采用不同图像尺寸、数据增强训练了一个模型,结果见上表。这里得出的实验结论与上述假设基本一致。这就促使我们:在训练过程中,伴随图像尺寸改变自适应调整正则化因子,此即为我们所提出的改进版渐进式学习方案。

上图给出了本文所提学习方案示意图,在训练早期,我们采用较小尺寸图像+弱化正则训练,此时模型可以快速学习简单表达能力;然后,我们逐渐提升图像尺寸并添加更强的正则因子。下图给出了该渐进式学习方案的步骤说明。

我们这里所提出的渐进式学习与现有正则因子具有兼容性,为简单起见,我们主要研究了以下三种正则:Dropout、RandAugment以及Mixup。
Experiments
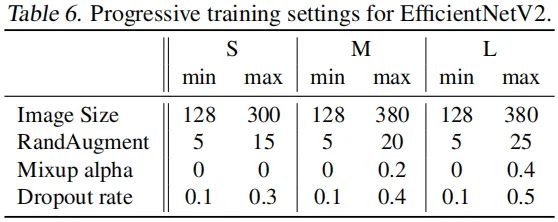
在训练过程中,我们将整个训练划分为四个阶段,每个阶段约87epoch:在训练的早期采用小图像块+弱化正则;在训练的后期采用更大的图像块核增强的正则,上表给出了不同模型的最大、最小图像尺寸以及正则强度。

上表给出了所提方法与其他方案在精度、参数量、FLOPs以及耗时方面的对比。从中可以看到:
相比其他方法,所提EfficientNetV2训练速度更快、精度更高、参数量更少。 相比EfficientNet-B7,EfficientNetV2精度相当,但训练速度快11倍。 相比RegNet和ResNeSt,EfficientNetV2精度更高、推理速度更快。 相比ViT,EfficientNetV2以85.7%的精度超越了ViT-L/16(21k)。 在推理速度方面,相比EfficientNet,EfficientNetV2精度更高、速度更快;相比ResNeSt,EfficientNetV2-M精度高0.6%,速度快2.8倍。 缩放数据尺寸要比简单的缩放模型大小更有效:当top1精度超过85%后,很难通过加单的提升模型大小提升精度;然而,ImageNet21K预训练可以显著提升模型精度。

上表对所提方法的迁移学习能力进行了对比。可以看到:相比其他卷积网络与Transformer方案,本文所提方法的泛化性能更加。
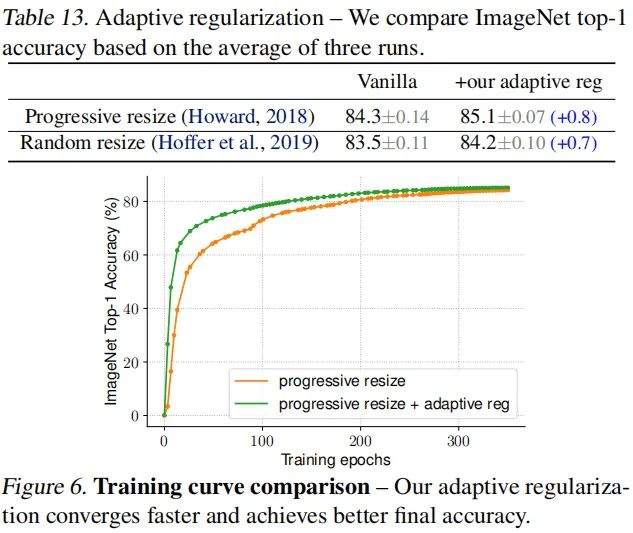
最后,我们还自适应正则的影响性进行分析,结果见上图。可以看到:(1) 自适应正则可以提升模型精度达0.7%;(2) 小尺度图像上添加弱化正则可以加速模型收敛。
全文到此结束,更多消融实验与分析建议各位同学查看原文。
推荐阅读
2021-03-17
2021-04-01

2021-03-29

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
