
yyds!EfficientNetV2:更小,更快!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
上篇文章谷歌打怪升级之路:从EfficientNet到EfficientNetV2(上)讲了EfficientNet,这篇文章讲解EfficientNetV2。
EfficientNetV2
谷歌在2021年4月份提出了EfficientNet的改进版EfficientNetV2: Smaller Models and Faster Training。从题目上就可以看出V2版本相比V1,模型参数量更小,训练速度更快。从下图中可以看到EfficientNetV2比其它模型训练速度快5x~11x,而参数量却少6.8x(表中相比ResNet-RS)。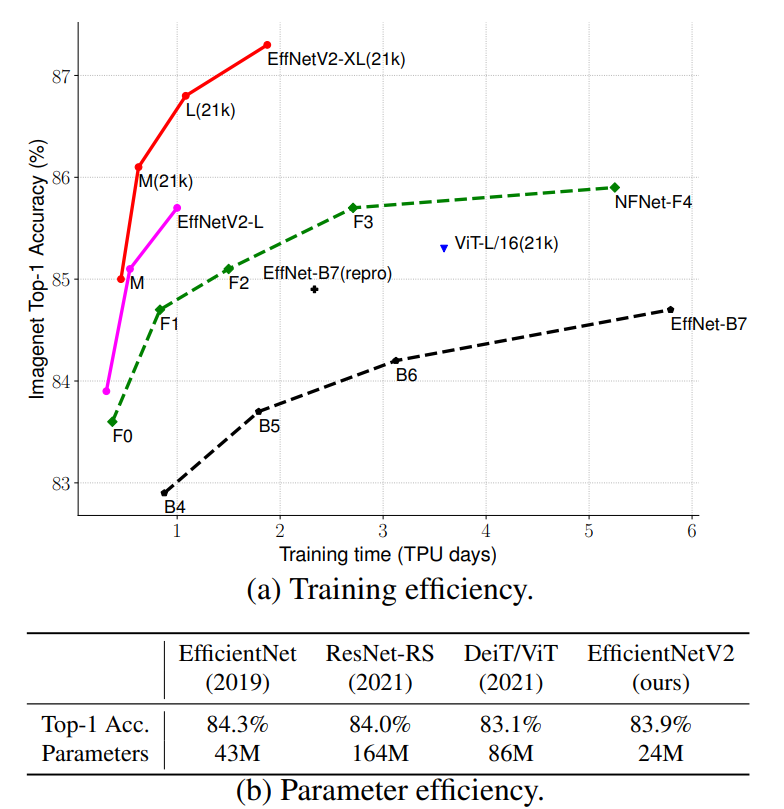
要改进EfficientNet,首先要分析存在的问题,论文中共指出三个方面的训练瓶颈问题。首先是** training with very large image sizes is slow**,EfficientNet在较大的图像输入时会使用较多的显存,如果GPU/TPU总显存固定,此时就要降低训练的batch size,这会大大降低训练速度。一种解决方案就是像FixRes那样,采用较小的图像尺寸训练,但是推理时采用较大的图像尺寸。比如EfficientNet-B6的训练size采用380相比512效果是相当的(推理size为528),但是可以采用更大的batch size,而且计算量更小,训练速度提升2.2x(与FixRes不同的是,这里没有在推理size下进行finetune)。但是论文中提出了一种更高级的训练技巧:progressive Learning,这个后面再叙述。 第二个问题是depthwise convolutions are slow in early layers but effective in later stages。EfficientNet中大量使用depthwise conv,相比常规conv,它的好处是参数量和 FLOPs更小,但是它并不能较好地利用现代加速器(GPU/TPU)。谷歌在EfficientNet-EdgeTPU提出了Fused-MBConv,这里是把MBconv中的depthwise conv3x3和expansion conv1x1替换成一个常规的conv3x3,在Edge TPU测试发现虽然前者的参数量和计算量更少,但是由于常规的conv更能较好地利用TPU,反而后者的执行速度更快。
第二个问题是depthwise convolutions are slow in early layers but effective in later stages。EfficientNet中大量使用depthwise conv,相比常规conv,它的好处是参数量和 FLOPs更小,但是它并不能较好地利用现代加速器(GPU/TPU)。谷歌在EfficientNet-EdgeTPU提出了Fused-MBConv,这里是把MBconv中的depthwise conv3x3和expansion conv1x1替换成一个常规的conv3x3,在Edge TPU测试发现虽然前者的参数量和计算量更少,但是由于常规的conv更能较好地利用TPU,反而后者的执行速度更快。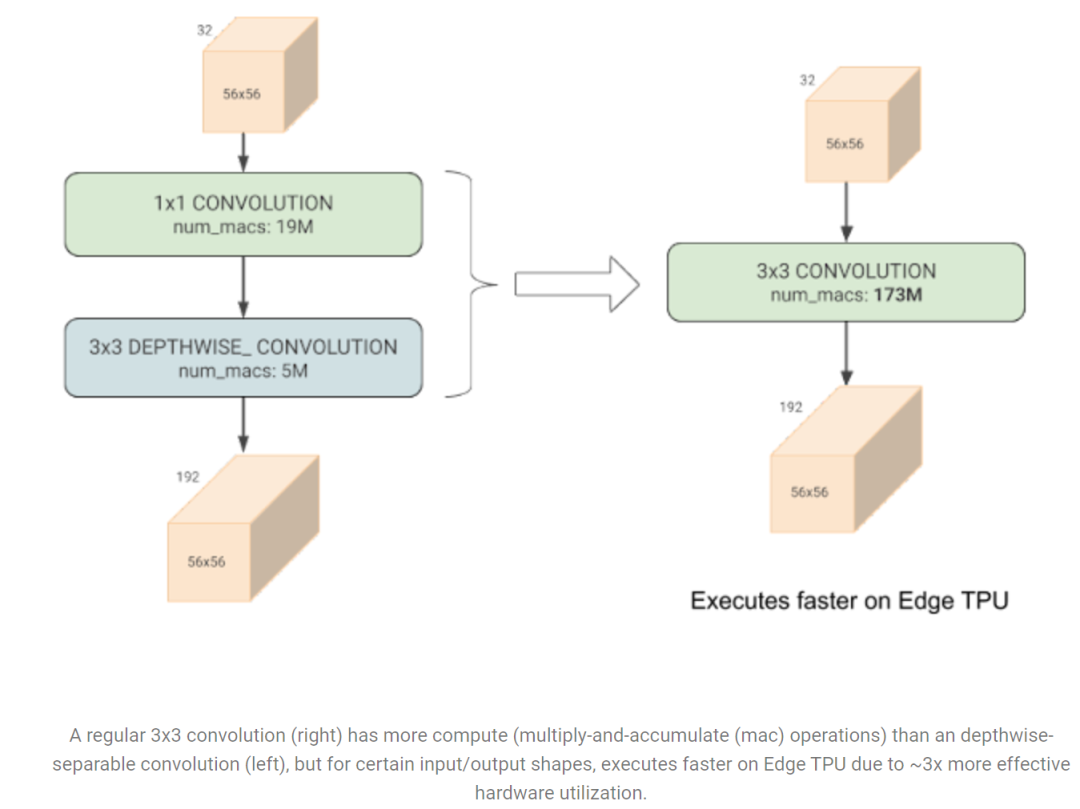 这里逐渐将EfficientNet-B4的MBConv替换成Fused-MBConv,发现如果将stage1~3替换为Fused-MBConv此时训练速度提升,但是所有stage均替换,此时参数量和FLOPs大幅度提升,但是训练速度反而下降。这说明适当地组合MBConv和Fused-MBConv才能取得最佳效果,后面用NAS来进行自动搜索。
这里逐渐将EfficientNet-B4的MBConv替换成Fused-MBConv,发现如果将stage1~3替换为Fused-MBConv此时训练速度提升,但是所有stage均替换,此时参数量和FLOPs大幅度提升,但是训练速度反而下降。这说明适当地组合MBConv和Fused-MBConv才能取得最佳效果,后面用NAS来进行自动搜索。 第三个问题是equally scaling up every stage is sub-optimal。EfficientNet的各个stage均采用一个复合缩放策略,比如depth系数为2时,各个stage的层数均加倍。但是各个stage对训练速度和参数量的影响并不是一致的,同等缩放所有stage会得到次优结果。EfficientNetV2采用的是非一致的缩放策略,后面的stages增加更多的layers。同时EfficientNet也不断地增大图像大小,由于导致较大的显存消耗而影响训练速度,所以EfficientNetV2设定了最大图像size限制。
第三个问题是equally scaling up every stage is sub-optimal。EfficientNet的各个stage均采用一个复合缩放策略,比如depth系数为2时,各个stage的层数均加倍。但是各个stage对训练速度和参数量的影响并不是一致的,同等缩放所有stage会得到次优结果。EfficientNetV2采用的是非一致的缩放策略,后面的stages增加更多的layers。同时EfficientNet也不断地增大图像大小,由于导致较大的显存消耗而影响训练速度,所以EfficientNetV2设定了最大图像size限制。
基于上述的三个问题分析,为了提升训练速度,EfficientNetV2采用training-aware NAS来设计,优化目标包括accuracy,parameter efficiency和training efficiency,搜索的卷积单元包括MBConv和Fused MBConv。论文中给出了搜索得到的EfficientNetV2-S模型,结构如下所示。相比V1结构,V2在前1~3个stage采用Fused MBConv;另外可以看出前面stage的MBConv的expansion ratio较小,而V1的各个stage的expansion ratio几乎都是6;V1部分stage采用了5x5卷积核,而V2只采用了3x3卷积核,但包含更多layers来弥补感受野;V2中也没有V1中的最后的 stride-1的stage。这些区别让EfficientNetV2参数量更少,显存消耗也更少。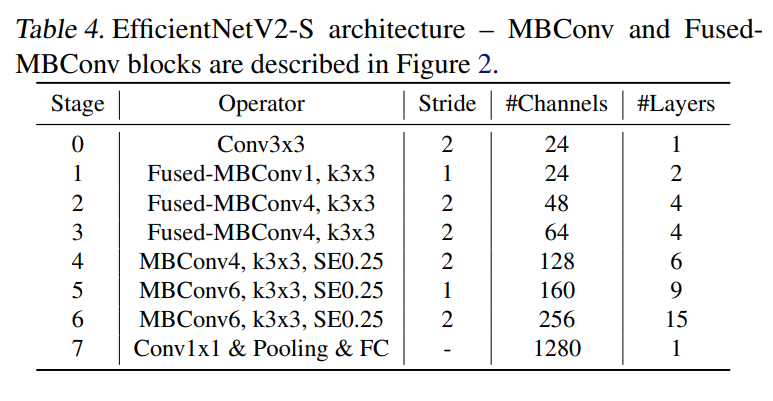 对EfficientNetV2-S进行缩放,可以进一步得到另外两个更大的模型:EfficientNetV2-M和EfficientNetV2-L。前面已经说过,V2缩放规则相比V1增加两个额外的约束,一个是限制图像最大size(最大480),二是后面的stage的layers更大。这两个模型的具体配置从开源的代码effnetv2_configs中找到,后两个较大的模型的输入size均为480。
对EfficientNetV2-S进行缩放,可以进一步得到另外两个更大的模型:EfficientNetV2-M和EfficientNetV2-L。前面已经说过,V2缩放规则相比V1增加两个额外的约束,一个是限制图像最大size(最大480),二是后面的stage的layers更大。这两个模型的具体配置从开源的代码effnetv2_configs中找到,后两个较大的模型的输入size均为480。
下图给出了EfficientNetV2模型在ImageNet上top-1 acc和train step time,这里的训练采用固定的图像大小,不过比推理时图像大小降低30%,而图中的EffNet(reprod)也是采用这样的训练策略,可以看到比baseline训练速度和效果均有明显提升,而EfficientNetV2在训练速度和效果上有进一步地提升。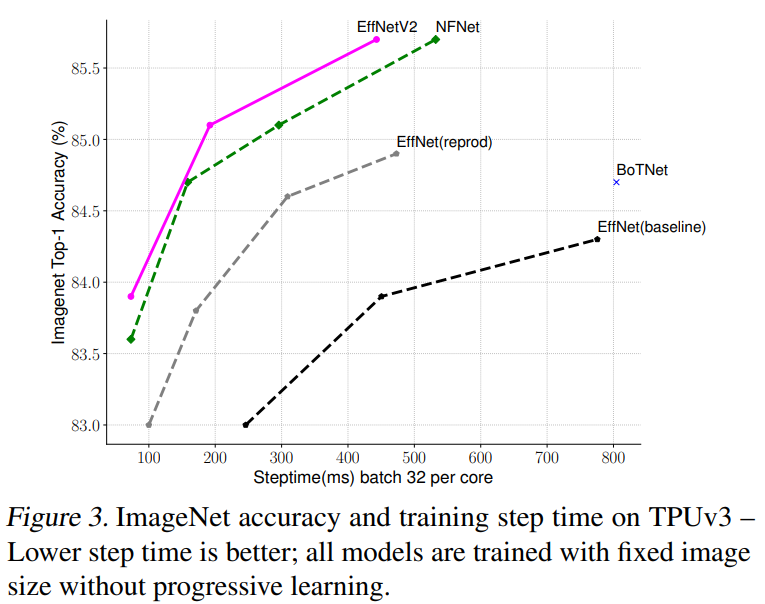
除了模型设计优化,论文还提出了一种progressive learning策略来进一步提升EfficientNetV2的训练速度,简单来说就训练过程渐进地增大图像大小,但在增大图像同时也采用更强的正则化策略,训练的正则化策略包括数据增强和dropout等,这里更强的正则化指的是采用更大的dropout rate,RandAugment magnitude和mixup ratio。 不同的图像输入采用不同的正则化策略,这不难理解,因为图像输入越大,模型容量越大,此时应该采用更强的正则化来防止过拟合,而小的输入模型容量小,应该采用较轻的正则化策略以防止欠拟合。从下表中可以看到,大的图像输入要采用更强的数据增强,而小的图像输入要采用较轻的数据增强才能训出最优模型效果。
不同的图像输入采用不同的正则化策略,这不难理解,因为图像输入越大,模型容量越大,此时应该采用更强的正则化来防止过拟合,而小的输入模型容量小,应该采用较轻的正则化策略以防止欠拟合。从下表中可以看到,大的图像输入要采用更强的数据增强,而小的图像输入要采用较轻的数据增强才能训出最优模型效果。 在实现上,首先对模型设定训练过程的输入图像大小以及数据增强的范围,然后将训练过程分成4个阶段(每个阶段87个epoch),每进入一个阶段,图像大小以及数据增强均线性提升。EfficientNetV2的训练设置如下所示(这里的训练最大image size大约比推理时小30%:380 vs 480):
在实现上,首先对模型设定训练过程的输入图像大小以及数据增强的范围,然后将训练过程分成4个阶段(每个阶段87个epoch),每进入一个阶段,图像大小以及数据增强均线性提升。EfficientNetV2的训练设置如下所示(这里的训练最大image size大约比推理时小30%:380 vs 480): EfficientNetV2在ImageNet上与其它模型对比如下表所示,可以看到无论是参数量,FLOPs,推理速度还是训练速度上,EfficientNetV2均有明显的优势。额外一点是,如果用ImageNet21K进行预训练,模型可以取得更好的效果,比如不用预训练,EfficientNetV2-L比EfficientNetV2-M效果仅提升了0.6个点,仅达到85.7%,但是预训练后EfficientNetV2-M效果就达到了86.2%,所以论文中说:scaling up data size is more effective than simply scaling up model size in high-accuracy regime。
EfficientNetV2在ImageNet上与其它模型对比如下表所示,可以看到无论是参数量,FLOPs,推理速度还是训练速度上,EfficientNetV2均有明显的优势。额外一点是,如果用ImageNet21K进行预训练,模型可以取得更好的效果,比如不用预训练,EfficientNetV2-L比EfficientNetV2-M效果仅提升了0.6个点,仅达到85.7%,但是预训练后EfficientNetV2-M效果就达到了86.2%,所以论文中说:scaling up data size is more effective than simply scaling up model size in high-accuracy regime。
从EfficientNet到EfficientNetV2,背后不仅仅是一次简单的迭代,而是包含了谷歌多年来各种工作的堆叠。
参考
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks EfficientNetV2: Smaller Models and Faster Training google/automl/efficientnetv2
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
