
EfficientNetV2:更小,更快,更好的EfficientNet
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:Mostafa Ibrahim
编译:ronghuaiyang
相比于之前的SOTA,训练速度快了5~10x,而且性能更高。
论文:https://arxiv.org/pdf/2104.00298.pdf
代码:https://github.com/google/automl/efficientnetv2
通过渐进学习,我们的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上显著优于之前的模型。通过在相同的ImageNet21k上进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top1精度,在使用相同的计算资源进行5到11倍的训练时,比最近的ViT的准确率高出2.0%。代码可以在https://github.com/google/automl/efficientnetv2上找到。
EfficientNets已经成为高质量和快速图像分类的重要手段。它们是两年前发布的,非常受欢迎,因为它们的规模让它们的训练速度比其他网络快得多。几天前谷歌发布了EfficientNetV2,在训练速度和准确性方面都有了很大的提高。在本文中,我们将探索这个新的EfficientNet是如何对之前的一个进行改进的。
性能更好的网络(如DenseNets和EfficientNets)的主要基础是用更少的参数实现更好的性能。当你减少参数的数量时,你通常会得到很多好处,例如更小的模型尺寸使它们更容易放到内存中。然而,这通常会降低性能。因此,主要的挑战是在不降低性能的情况下减少参数的数量。
这一挑战目前主要集中在神经网络体系结构搜索(NAS)这一日益成为热点的领域。在最优情况下,我们给某个神经网络一个问题描述,然后它就会给出这个问题的最优网络结构。
我不想在这篇文章中讨论EfficientNets 。但是,我想提醒你EfficientNets的概念,这样我们就可以精确地指出在架构上的主要差异,从而使性能更好。EfficientNets使用NAS来构建一个基线网络(B0),然后他们使用“复合扩展”来增加网络的容量,而不需要大幅增加参数的数量。在这种情况下,最重要的度量指标是FLOPS(每秒浮点运算次数),当然还有参数的数量。
1. 渐进式训练

EfficientNetV2使用了渐进式学习的概念,这意味着尽管在训练开始时图像大小最初很小,但它们逐渐增大。这个解决方案源于这样一个事实,即EfficientNets的训练速度在大图像尺寸时开始受到影响。
渐进式学习并不是一个新概念,它在以前已经被使用过。问题是,以前使用的时候,相同的正则化效果被用于不同大小的图像。EfficientNetV2的作者认为这降低了网络容量和性能。这就是为什么他们会随着图像大小的增加而动态增加正规化来解决这个问题。
如果你仔细想想,这很有道理。在小图像上过度正则化会导致拟合不足,而在大图像上过度正则化会导致过拟合。
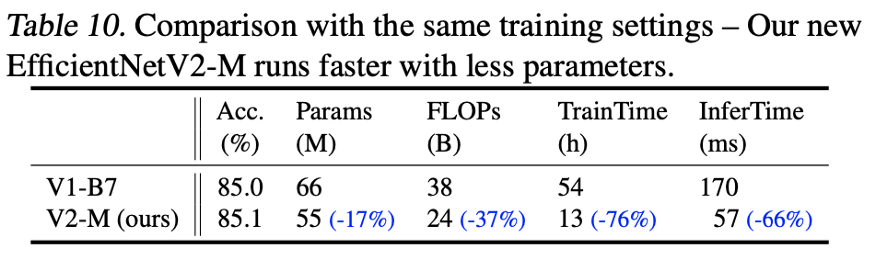
通过改进的渐进学习,我们的EfficientNetV2在ImageNet、CIFAR-10、CIFAR- 100、Cars和Flowers数据集上取得了强大的结果。在ImageNet上,我们实现了85.7%的top-1精度,同时训练速度提高了3 - 9倍,比以前的模型小6.8倍
2. 在MB Conv层上构建Fused-MB Conv层
EfficientNets使用了一个称为“depth convolution layer”的卷积层,这些层有较少的参数和FLOPS,但它们不能充分利用GPU/CPU。为了解决这一问题,最近发表了一篇题为“MobileDets: Searching for Object Detection Architectures for Mobile accelerator”的论文,该论文通过一个名为“Fuse-MB Conv layer”的新层解决了这一问题。这个新层被使用在这里的EfficientNetV2上。然而,由于其参数较多,不能简单地将所有旧的MB Conv层都替换成Fused-MB Conv层。
这就是为什么他们使用训练感知NAS来动态搜索fused和常规MB Conv层的最佳组合。NAS实验结果表明,在较小的模型中,早期将部分MB Conv层替换为fused层可以获得更好的性能。研究还表明,MB Conv层(沿网络)的扩展比越小越好。最后,它表明更小的内核大小和更多的层是更好的。

3. 一个更加动态的方法去扩展
我认为这里值得学习的一个主要有价值的想法是他们改进网络的方法。我认为总结这一方法的最好方法是首先用EfficientNet来查看问题,这是显而易见的,但接下来的步骤是开始制定一些更动态的规则和概念,以便更好地适应目标和目的。我们首先在渐进式学习中看到了这一点,当他们使正则化更加动态,以便更好地适应图像大小,提高了表现。
我们现在看到这种方法再次被用于扩展网络。EfficientNet使用一个简单的复合缩放规则,均匀地扩大所有stages。EfficientNetV2的作者指出这是不必要的,因为并不是所有的阶段都需要通过扩展来提高性能。这就是为什么他们使用非统一的扩展策略在后期逐步添加更多层的原因。他们还添加了一个缩放规则来限制最大的图像大小,因为EfficientNets倾向于积极地将图像大小放大。
我认为这背后的主要原因是,早期的层并不需要扩展,因为在这个早期阶段,网络只关注高级特征。然而,当我们深入到网络的更深层,并开始研究低级特征时,我们将需要更大的层来完全消化这些细节。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!