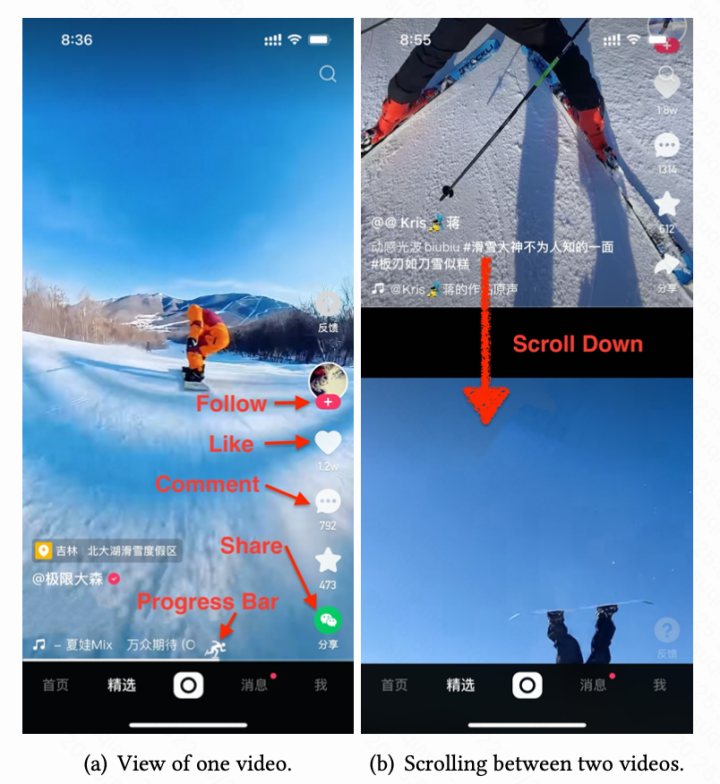
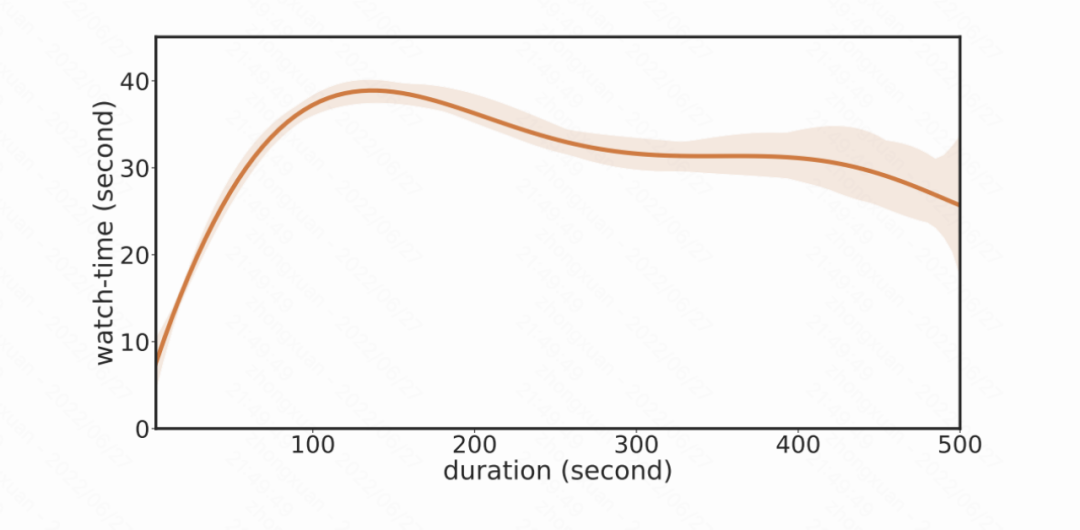
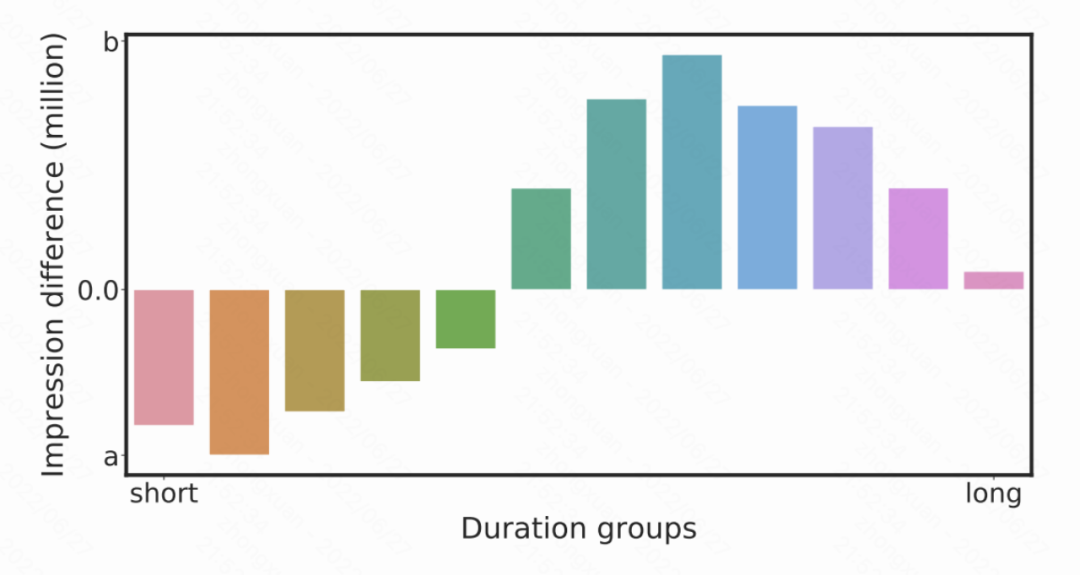
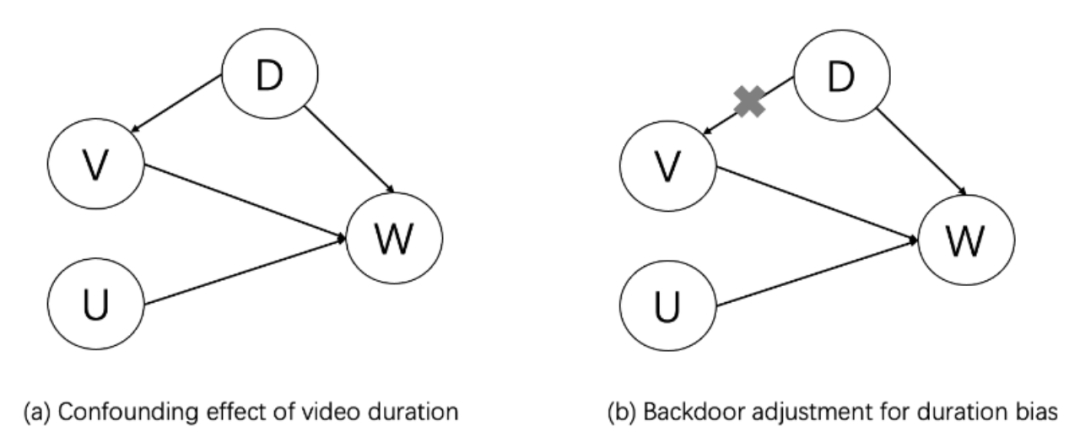
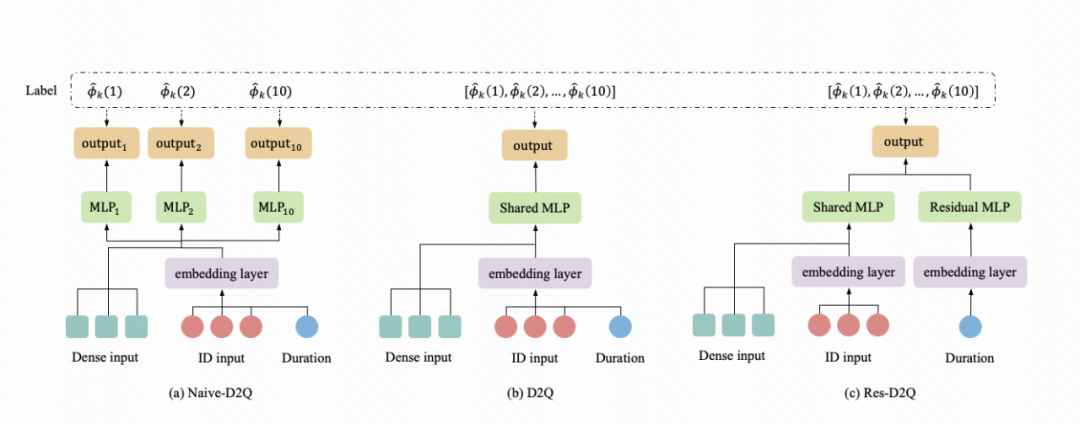
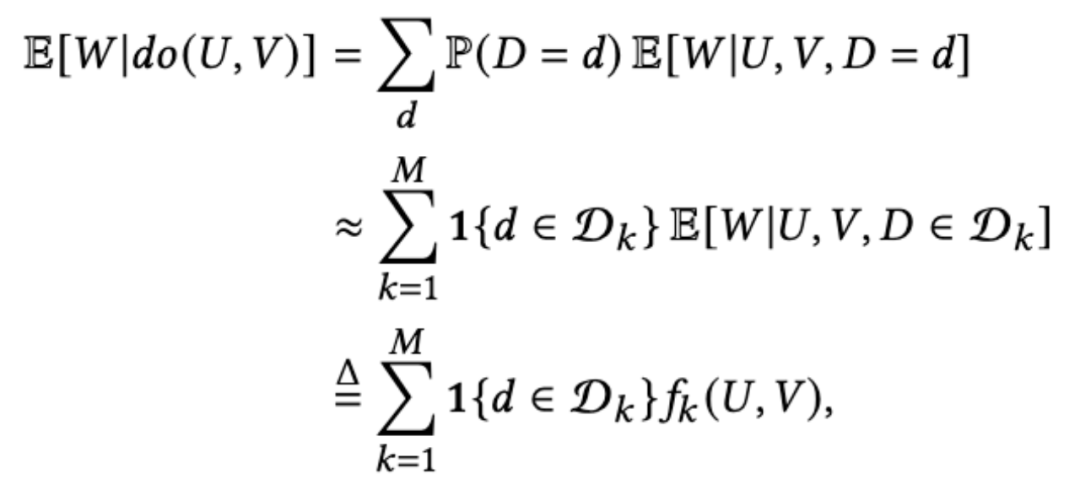KDD 2022 | 快手提出基于因果消偏的观看时长预估模型D2Q,解决短视频推荐视频时长bias难题视学算法关注共 4605字,需浏览 10分钟 ·2022-07-31 02:40 视学算法专栏快手社科推荐团队短视频(比如快手、抖音和视频号等)日益成为人们日常生活中最重要娱乐方式。短视频推荐需要解决的一个基础问题是,如何准确地预估用户对某个视频的观看时长。观看时长建模的精准度一定程度反映了推荐的质量,对提升用户粘性意义重大。业界普遍使用的方法是由 YouTube 在 RecSys 于 2016 年提出来的方法或其变种 [1],然而该方法最开始的提出是基于「点击 - 观看」的长视频场景,在目前无显式点击 Label 的沉浸式浏览模式下并不适用, 同时短视频场景视频本身长度跨度很大,给模型预估带来了极大的挑战。用户对一个视频的观看时长受到两方面影响,一是用户对视频内容的满意程度,二是视频本身的长度(duration)。现有建模方案,不管是直接回归时长,还是 YouTube 的方法,均有训练不稳定,误差大等缺陷。快手首次指出了时长预估中的 duration bias 问题,基于此提出了基于因果推断的时长预估模型,有效地消除了 duration 混淆变量的影响,和 YouTube 方法相比,预估精度和稳定性得到了极大的提升。该 paper 被 SIGKDD 2022 Applied Data Science Track 接收,同时被邀请做口头报告。该论文的模型 D2Q 经过改进之后在快手全量上线,成为短视频领域继 YouTube DNN 之后最好用的时长预估模型。作者:詹若涵、裴昶华、苏强、文剑烽、王学良、穆冠宇、郑东、江鹏论文地址:https://arxiv.org/abs/2206.06003问题建模快手采用的沉浸式浏览模式(如下图一),推荐系统通过建模用户兴趣为用户推荐可能喜欢的视频,优化视频观看时长、浏览深度、互动 (点赞、关注、转发)、多样性等多个维度的指标,以此营造良好的社区氛围,提升用户粘性。在上述众多目标中,视频观看时长作为最稠密的指标,也作为用户最稀缺的资源,客观有效的反映用户对视频的喜好程度,是短视频场景下推荐系统优化的重要指标。图一、快手上下滑场景展示然而,时长预估 (Watchtime Prediction) 不仅取决于用户兴趣和视频的匹配程度,还会被视频长度(duration)的分布影响: 一方面,如图二 (a) 所示,对于 100 秒以下的视频,视频观看时长和视频本身的时长有非常明显的线性关联关系,如何在如此优势的特征下建模出用户真正的兴趣部分具有一定的挑战;另外一个方面,下图二(b)展示了平台在一段时间不同 duration 的分布变化,可以看出随着推荐系统的优化,曝光样本中 duration 分布极不均衡,同时长视频的占比会变大。使得模型的训练被长视频主导,影响时长预估模型的效果和稳定性。图二、 (a)视频观看时长和视频长度的关系图二、 (b)不同时间区间视频分布的变化为了解决上述的问题, 论文提出使用因果推断的方法消除时长预估任务中的 duration bias 问题。论文首次通过因果图的方式给出了时长预估任务的形式化定义。图三揭示了 duration 是时长预估中需要消除的混淆变量(Confounder):一方面视频的 duration 和 观看时长直接相关;另一方面,时长预估样本中 duration 分布会影响到模型训练本身:模型训练会被长视频主导,同时优势特征 duration 会影响用户侧兴趣的建模。为了消除 duration 的负向影响,论文提出 Duration-Deconfounded Quantile-based (D2Q) 时长预估方法。D2Q 采用后门准则的调整方法,对于不同 duration 的视频,使用 Distribution-Aware 的时长分位数预估方法来消除 duration 带来的影响,从而提升了时长预估精度。通过在快手数据集上大量的离线评估和在线实验,论文发现 D2Q 显著优于 SOTA 时长预估方法,离线评估预估精度提升 2.8pp。基于该方法改进版本的多目标版本已经在快手 APP 上全量,取得了时长和 VV(播放数)的双重增量提升。图三、 视频推荐场景下观看时长(Watchtime)预估的因果图。D 表示视频的长度 duration,V 表示视频 video, U 表示用户 user, W 表示观看时长 watchtime。算法图三中,D 表示视频的长度 duration,V 表示视频 video, U 表示用户 user, W 表示观看时长 watchtime。视频 duration 通过 D->V->W 和 D->W 两条路径影响时长预估,其中 D->W 表明视频 duration 与观看时长具有直接的因果关系,这也是符合预期的,因为相较于短视频,用户更加倾向于在长视频上停留更长的时间,这是时长模型应该捕捉到的。但是,D->V->W 表示曝光视频的 duration 分布会影响观看时长的预估,这主要是因为推荐系统倾向于推荐长视频来提升 app 时长,导致曝光视频中长视频占比过大;而模型训练时长视频会获得比较大的权重,从而主导了梯度。为了消除 duration 的负面影响。对图三 (a) 所示的原始因果图,论文采用 back-door adjustment 对其进行调整,得到图三(b)。这一操作背后的原理是:对于不同 Duration 的视频,论文使用分开建模的方式来消除 Duration 带来的影响,使得模型的预估更为准确。通过这种方式,时长优化模型可以使用下式表示,进一步的,论文对 Duration 进行粗粒度的分组,来降低遍历所有 Duration 带来的计算开销。具体做法为,对视频的 Duration 进行排序,并等频率分为 M 个桶,使用每个分桶下的样本独立训练时长模型,因此时长优化模型转化为以下形式:其中,是每个 duration 分桶下的时长预估模型。D2Q 算法的具体做法如下:1. 统计训练样本的 duration 分布,得到等频分桶分位点;2. 将样本按照等频分桶分位点分成 k 个相互独立的分桶 D_k;3. 对不同 duration 分桶的样本,在组内统计时长分位数作为 label,得到 Duration-Aware Watchtime-Distribution label;4. 分别在上述的分桶上训练时长预估模型 f_k;算法伪代码如下:D2Q 模型给出每个时长分桶下的分位数预估值,为了让预估值在桶间可比,论文通过观看时长信号的累积概率分布得到预估值对应的观看时长原始值。模型下图四(a)展示了论文的模型,特征选择上,photo 侧包括粗精排预估值 dense/sparse 特征、固有时长 Duration、视频类别标签等,user 侧包括 session 统计特征以及基础属性特征。在训练方式上,第一个版本采用了 M 个网络完全独立,分别学习各自的 label,这种训练方式不共享特征 embedding,特征 embedding 空间随着分桶维度扩大线性增加,存储、训练的资源开销随之增加,实现成本较高,不符合工业界场景的要求;因此论文设计了如图四(b)的网络结构, M 个网络共享底层特征,采用多输出的训练方式,则 batch 内样本分布不均的问题会导致子塔训练不稳定,收敛到局部最优。单塔单输出的训练方式在实际训练时效果稳定,收敛速度较快,是 D2Q 实现的基线版本。为了进一步提升模型效果,论文在单塔单输出模型中引入 Duration bias 模块 (如图四 c 所示),用于建模不同分桶下的样本差异(Res-D2Q),离线训练指标得到进一步的提升。图四、D2Q 模型结构示意图效果论文使用 XAUC、XGAUC 以及 MAE 等指标对时长回归效果进行评估。MAE 表示短视频预估时长与观看时长 label 的误差绝对值,表示模型回归精度,是回归任务的常用评估指标。XAUC 的计算方式如下:将测试集中的样本两两组合,若组合的标签和预估值的序一致则为正序,否则为逆序,XAUC 是正序对数与总组合数的比值;XGAUC 是用户维度计算的 XAUC。由于推荐系统主要优化候选集的排序,评估指标 XAUC 能够更加直观的反映预估时长序的好坏,与论文的优化目标更加适配。论文分别评估了 0、10、20、30、50、100 时长分桶下,D2Q 以及 Res-D2Q 的预估效果,与常用的时长建模方案 (VR、WLR) 进行对比,结果如下图表所示。其中,VR 表示观看时长回归任务;WLR 是 YouTube 提出的时长预估方式 (在快手单列场景下,使用 60% 全局时长分位数作为正负样本划分依据,并使用观看时长对正样本加权)。由表可知,D2Q 建模方式显著优于 VR 和 WLR,其中 D2Q-30 与 VR 相比提升尤为显著,XGAUC 指标提升 2.8pp;而 Res-D2Q 在相同的 duration 分桶下,XGAUC 相对 D2Q 也有千分位的提升。图五、D2Q 模型离线评估效果(上)及随着分桶数量变化 XGAUC 变化曲线(下)为了说明 duration 分桶数对模型预估效果的影响,论文做了消融实验。实验发现 D2Q 的预估效果在 30 分桶后随着 duration 分桶数增加而下降,这一现象主要是由以下原因导致的:(1) 分桶数增加,各分桶下的样本变少,全局分位数统计信噪比降低;(2) 样本空间随着分桶数增加而增大,单塔单输出模型拟合能力有限,导致排序效果下降。在实际大规模线上生效时,论文将统计的数据量扩大的一个量级,通过分布式计算,使得 100 个分桶时效果也不会下降,进一步的提升了模型的效果。挑战和未来方向一个高效的时长预估模型对于短视频推荐场景显得非常重要,是评价用户满意度、衡量平台收益的一个重要的指标。该论文首次从因果推断的角度对时长建模进行形式化的定义,同时指出了时长预估中最大的难点和挑战: duration bias。并给出了一套行之有效的方法。然而现有的时长预估的精度和准确度还有很大的提升空间。一方面是由于现有的 Label 设计需要进行进一步的改进的空间:如融合一些其他目标,在时长为主目标的前提下兼顾其他目标;而另外一方面,用户观看视频时长本身相比于其他的显式反馈信号如点赞,评论等噪声更大,如何在不损失信息量的情况下提升视频时长的信噪比也是一个很有价值的研究方向。快手这篇论文也是第一次将时长预估这个问题进行了正式的总结和初探,旨在抛出问题,非常欢迎大家参与到该问题的优化和讨论过程中,将视频推荐的时长预估模型提升一个层次。[1] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016.© THE END 转载请联系原公众号获得授权点个在看 paper不断! 浏览 73点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 视频号用户时长涨了80%昨天,腾讯发布了2024年Q1财报,游戏和社交增长乏力,现在发力的是广告、支付和云服务,而短时间内的增长点只能是:以视频号为载体的直播带货生态在财报中,腾讯将自己毛利和经营利润的大幅增长归结于:微信视频号、搜一搜广告、小游戏平台服务费、视频号商家技术服务费。而以上业务全部来自微信,换句话说,微信以一总时长翻倍的视频号,似乎并未冲击到快手企鹅生态0【短视频专题】短视频快手系列报告:老铁经济 快手江湖数据D江湖0短视频又拍云短视频服务集短视频采集、上传、存储、分发、播放于一体,借助短视频 SDK、上传加速、不限量存储、视频瘦身、稳定快速的 CDN 及播放器 SDK,为用户提供专企业级短视频解决方案。短视频推广短视频发布短视频营销短视频直播带货成都创小新网络科技有限公司0【短视频】短视频爆粉地图数据D江湖0【短视频】视频号的新机会数据D江湖0上半年移动网民增速快,短视频占全网使用总时长近三成TV大数据洞察0快手短视频如何打造矩阵流量?运营大叔0短视频内容算法:如何在算法推荐时代引爆短视频短视频内容算法:如何在算法推荐时代引爆短视频0点赞 评论 收藏 分享 手机扫一扫分享分享 举报