
紧追Google的MLP-Mixer!Facebook AI提出ResMLP!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,大家都被Google AI发布MLP-Mixer: An all-MLP Architecture for Vision(Google AI提出MLP-Mixer:只需MLP就在ImageNet达到SOTA!)给刷屏了。论文中证明了仅包含最简单的MLP结构就能在ImageNet上达到SOTA。而就在Google公布论文的第二天,Facebook AI也公布了一篇论文:ResMLP: Feedforward networks for image classification with data-efficient training。这篇论文提出的ResMLP和Google提出MLP-Mixer模型简直如出一辙,都证明了简单的MLP结构就能在图像分类问题上取得比较好的效果。
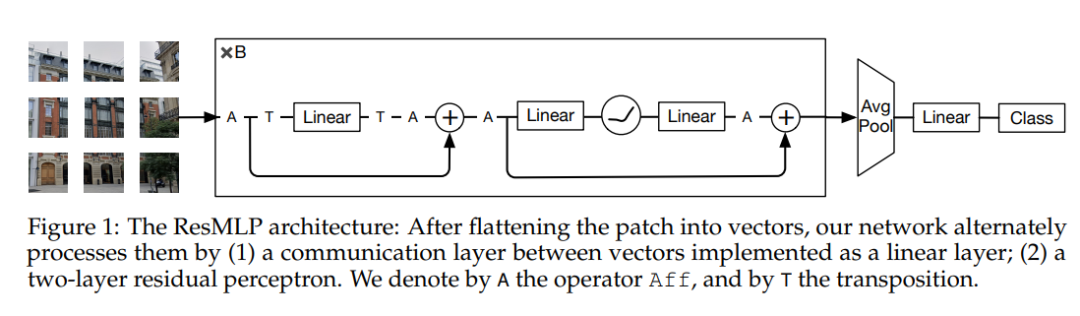
ResMLP的网络结构如上图所示,网络的输入也是一系列的patch emmbeddings,模型的基本block包括一个linear层和一个MLP,其中linear层完成patchs间的信息交互,而MLP则是各个patch的channel间的信息交互(就是原始transformer中的FFN):
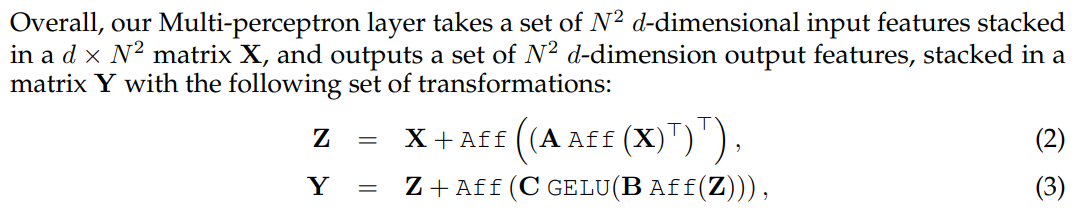
虽然整体思路和MLP-Mixer一致,但是ResMLP还是有以下几点不同的地方:
(1)ResMLP并没有采用LayerNorm,而是采用了一种Affine transformation来进行norm,这种norm方式不需要像LayerNorm那样计算统计值来做归一化,而是直接用两个学习的参数α和β做线性变换:
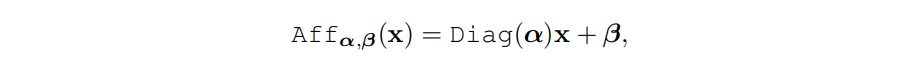
具体的实现代码比较简单:
# No norm layerclass Affine(nn.Module):def __init__(self, dim):super().__init__()self.alpha = nn.Parameter(torch.ones(dim))self.beta = nn.Parameter(torch.zeros(dim))def forward(self, x):return self.alpha * x + self.beta
这种norm方式和Going deeper with image transformers论文中采用的LayerScale很相似,不过后者没有偏置项。实际上在ResMLP中pre-normalization中采用Aff,而residual block的pre-normalization采用LayerScale:
# MLP on channelsclass Mlp(nn.Module):def __init__(self, dim):super().__init__()self.fc1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.fc2 = nn.Linear(4 * dim, dim)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.fc2(x)return x# ResMLP blocks: a linear between patches + a MLP to process them independentlyclass ResMLP_BLocks(nn.Module):def __init__(self, nb_patches ,dim, layerscale_init):super().__init__()self.affine_1 = Affine(dim)self.affine_2 = Affine(dim)self.linear_patches = nn.Linear(nb_patches, nb_patches) #Linear layer on patchesself.mlp_channels = Mlp(dim) #MLP on channelsself.layerscale_1 = nn.Parameter(layerscale_init * torch.ones((dim))) #LayerScaleself.layerscale_2 = nn.Parameter(layerscale_init * torch.ones((dim))) # parametersdef forward(self, x):res_1 = self.linear_patches(self.affine_1(x).transpose(1,2)).transpose(1,2))x = x + self.layerscale_1 * res_1res_2 = self.mlp_channels(self.affine_2(x))x = x + self.layerscale_2 * res_2return x
与ViT和MLP-Mixer一样,ResMLP也是堆积同样的block来提取特征:
# ResMLP model: Stacking the full networkclass ResMLP_models(nn.Module):def __init__(self, dim, depth, nb_patches, layerscale_init, num_classes):super().__init__()self.patch_projector = Patch_projector()self.blocks = nn.ModuleList([ResMLP_BLocks(nb_patches ,dim, layerscale_init)for i in range(depth)])self.affine = Affine(dim)self.linear_classifier = nn.Linear(dim, num_classes)def forward(self, x):B, C, H, W = x.shapex = self.patch_projector(x)for blk in self.blocks:x = blk(x)x = self.affine(x)x = x.mean(dim=1).reshape(B,-1) #average poolingreturn self.linear_classifier(x)
(2)ResMLP不像MLP-Mixer一样采用两个MLP,对于token mixing部分只是采用一个linear层。其实ResMLP的本意是将self-attention替换成MLP,而self-attention后面的FFN本身就是一个MLP,这样就和Google的MLP-Mixer一样了,但是最终实验发现替换self-attention的MLP中间隐含层的维度越大反而效果越差,索性就直接简化成a simple linear layer of size N × N;
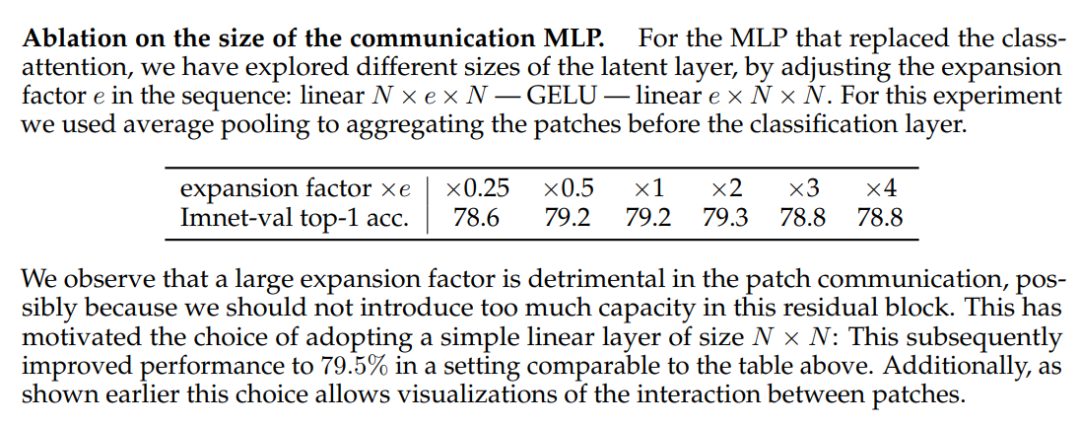
(3)没有在大数据(ImageNet-21K,JFT-300M)上pretrain,模型都是直接用ImageNet-1K训练的,主要是用training strategy (heavy data-augmentation and optionally distillation)来得到好的performance。
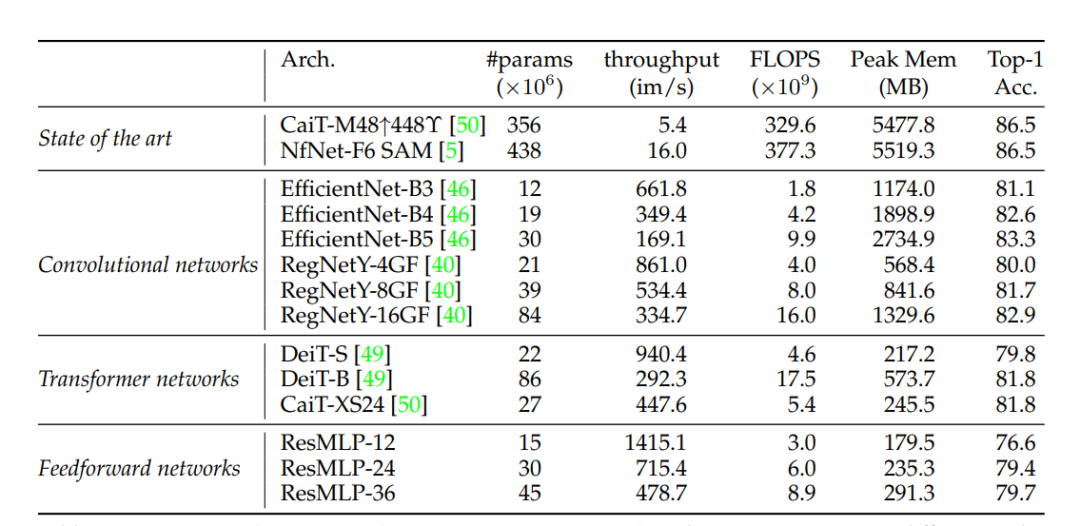
ResMLP相比ViT和CNN,效果还是稍差一点,但是通过知识蒸馏可以进一步提升效果,这说明MLP模型比较容易过拟合,知识蒸馏可能引入了一些正则来提升效果。
另外一点就是ResMLP采用linear层来做patch mixing,这样就可以简单对学习的weights进行可视化(N^2xN^2大小的图像),可视化后发现学习的参数和卷积很类似,表现出了局部性(特别是前面的layer):

论文中进一步分析了模型的稀疏性,论文中发现不仅linear层很稀疏,而且MLP的参数也很稀疏,这可能有利于做模型压缩:
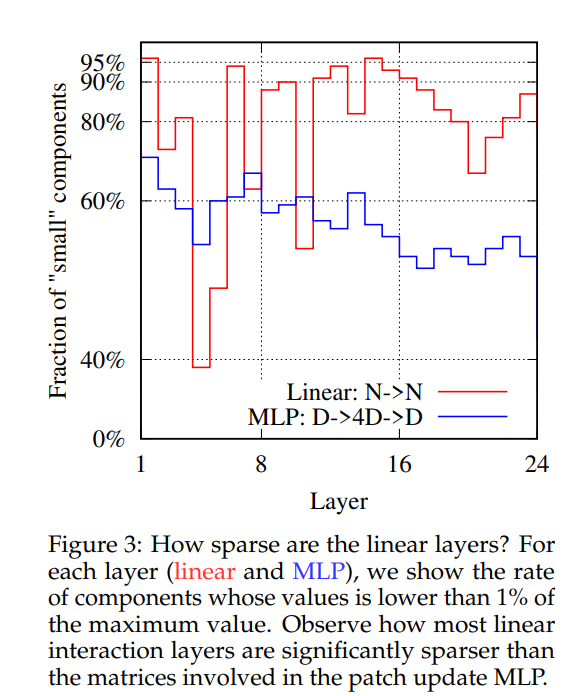
虽然在同等条件下,MLP还稍差于ViT和CNN,但是MLP结构是非常简单的,或许在不远的将来,会有更好的训练策略和设计使得MLP效果进一步提升。
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
