
老板:先规划,牛逼先吹出去
共 2661字,需浏览 6分钟
·
2023-01-12 12:06
好些天没更新了,并没有偷懒,只不过一直在安装环境,差点都想放弃了。
上一次比较大的更新是做了austin的预览地址,把企业微信的应用和机器人消息各种的消息类型和功能给完善了。上一篇文章也提到了,austin常规的功能已经更新得差不多了,剩下的就是各种细节的完善。
不知道大家还记不记得我当时规划austin时,所画出的架构图:
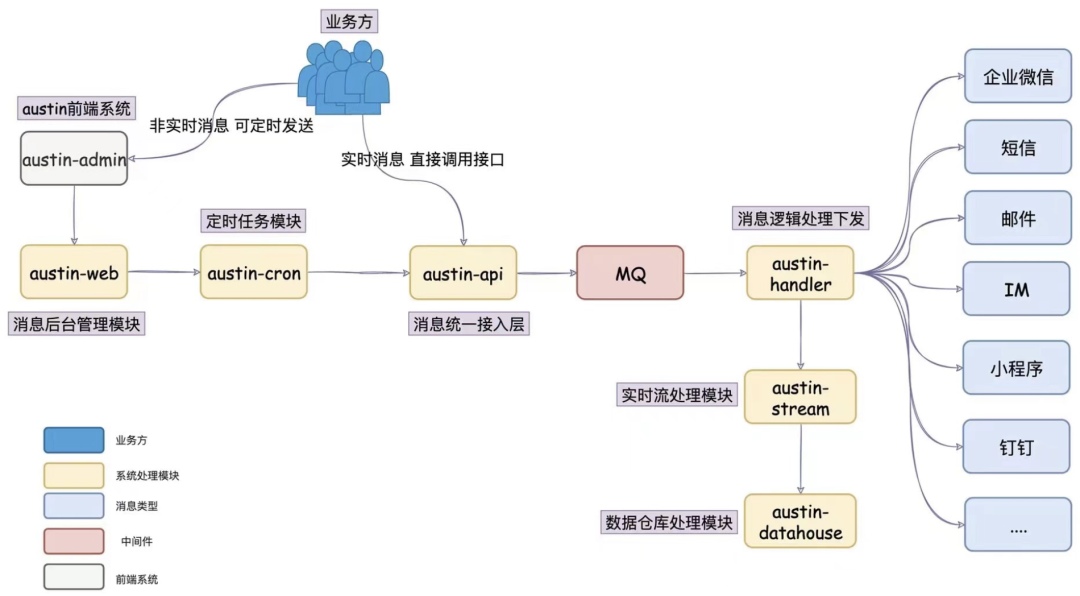
现在就剩下austin-datahouse这个模块没有实现了,也有挺多同学在看代码的时候问过我这个模块在哪...其实就是还没实现,先规划,牛逼先吹出去(互联网人必备技能)
至于这个模块吧,我预想它的功能就是把austin相关的实时数据写到数据仓库里。一方面是做数据备份,另一方面是大多数的报表很多都得依赖数据仓库去做。实际上,生产环境也会把相关的数据写到数仓中。
而在公司里,要把数据写到数据仓库,这事对开发来说一般很简单。因为有数仓这个东西,那大多数都会有相关的基础建设了。对于开发而言,可能就是把日志数据写到Kafka,在相关的后台配置下这个topic,就能将这个topic的数据同步到数据仓库里咯。如果是数据库的话,那应该大数据平台有同步数据的功能,对普通开发来说也就配置下表名就能同步到数据仓库里咯。
反正使用起来很简单就是了。不过,我其实不知道具体是怎么做的。
但是不要紧啊,反正开源项目对于时间这块还是很充裕得啊:没有deadline,没有产品在隔壁催我写,没有相关的技术要跟我对接。那我不懂可以学,于是也花了几天看了下数仓这块内容。
在看数仓的同时,我之前在公司经常会听到数据湖这个词。我刚毕业的时候是没听过的,但这几年好像这个概念就火起来了。跟大数据那边聊点事的时候,经常会听到:数据入湖。
那既然看都看了,顺便了解数据湖是个什么东西吧?对着浏览器一轮检索之后,我发现这个词还是挺抽象的,一直没找到让我耳目一新的答案,这个数据湖也不知道怎么就火起来了。我浏览了一遍之后,我大概可以总结出什么是数据湖,跟数据仓库有啥区别:
1、数据仓库是存储结构化的数据,而数据湖是什么数据都能存(非结构化的数据也能存)。结构化数据可以理解为我们的二维表、JSON数据,非结构化的数据可以理解为图像文件之类的。
数据仓库在写入的时候,就要定义好schema了,而数据湖在写入的时候不需要定schema,可以等用到的时候再查出来。强调这点,说明数据湖对数据的schema约束更加灵活。
2、数据仓库和数据湖并不是替代关系。数据是先进数据湖,将数据加工(ETL)之后,一部分数据会到数据仓库中。
3、我们知道现有的数据仓库一般基于Hadoop体系的HDFS分布式文件系统去搭建的,而数据湖也得存储数据的嘛,一般也是依赖HDFS。
4、开源的数据湖技术比较出名的有hudi、iceberg、Delta Lake
看完上面的描述,是不是觉得有点空泛。看似学到了很多,但是实际还是不知道数据湖有啥牛逼之处。嗯,我也是这么想的。总体下来,感觉数据湖就相当于数据仓库的ODS,围绕着这些数据定义了对应的meta信息,做元数据的管理。
说到ODS这个词了,就简单聊下数据仓库的分层结构吧。这个行业通用的,一般分为以下:
1、ODS(Operate Data Store),原始数据层,未经过任何加工的。
2、DIM(Dictionary Data Layer),维度数据层,比如存储地域、用户客户端这些维度的数据。
3、DWD(Data Warehouse Detail),数据明细层,把原始数据经过简单的加工(去除脏数据,空数据之后就得到明细数据)。
4、DWS(Data Warehouse Service),数据维度汇总层,比如将数据明细根据用户维度做汇总得到的汇总之后的数据。
5、ADS(Application Data Store),数据应用层,这部分数据能给到后端以接口的方式给到前端做可视化使用了。
至于为什么要分层,跟当初我们理解DAO/Service/Controller的思想差不多,大概就是复用和便于后续修改变动。
扯了那么多吧,聊会ausitn项目吧,我是打算怎么做的呢?因为我的实时计算austin-stream模块是采用Flink去做的,我打算austin-datahouse也是采用flink去做。
这几年在大数据领域湖仓一体、流批一体这些概念都非常火,而对于austin来说,第一版迭代还不用走得这么急。我目前的想法是利用flink的tableapi去对接Hive,通过Superset、Metabase、DataEase 其中一个开源的大数据可视化工具把Hive的数据给读取出来,那第一版就差不多完成了。
有了这个想法以后,我这几天就在写相关的代码和部署对应的环境了。这个环境的问题啊,比我预想中还要难搞很多,特别是Flink的各种版本对应的Hive版本。反正现在还在搞,等后面跑通环境了,再来跟大家分享下这个过程吧。
看到这篇文章的肯定也会有大数据相关的同学,感觉是可以给我们科普下数据湖究竟有什么必要性,我总感觉数据仓库就已经够用了。欢迎在评论区多多交流呀。
推荐项目
如果想学Java项目的,我还是
强烈推荐
我的开源项目消息推送平台Austin,可以用作
毕业设计
,可以用作
校招
,可以看看
生产环境是怎么推送消息
的。
仓库地址(可点击阅读原文跳转):https://gitee.com/zhongfucheng/austin
我开通了 股东服务 内容,感兴趣可以点击下方看看,主要针对的是项目哟