
2022最新!18条优化PyTorch的速度和内存效率小技巧
来源:AI公园
作者:Jack Chih-Hsu Lin
编译:ronghuaiyang
你应该知道的18个PyTorch小技巧。

你为什么要读这篇文章?
深度学习模型的训练/推理过程涉及很多步骤。在有限的时间和资源条件下,每个迭代的速度越快,整个模型的预测性能就越快。我收集了几个PyTorch技巧,以最大化内存使用效率和最小化运行时间。为了更好地利用这些技巧,我们还需要理解它们如何以及为什么有效。
我首先提供一个完整的列表和一些代码片段,这样你就可以开始优化你的脚本了。然后我一个一个地详细地研究它们。对于每个技巧,我还提供了代码片段和注释,告诉你它是特定于设备类型(CPU/GPU)还是模型类型。
列表:
数据加载
1、把数据放到SSD中
2、
Dataloader(dataset, num_workers=4*num_GPU)3、
Dataloader(dataset, pin_memory=True)数据操作
4、直接在设备中创建
torch.Tensor,不要在一个设备中创建再移动到另一个设备中5、避免CPU和GPU之间不必要的数据传输
6、使用
torch.from_numpy(numpy_array)或者torch.as_tensor(others)7、在数据传输操作可以重叠时,使用
tensor.to(non_blocking=True)8、使用PyTorch JIT将元素操作融合到单个kernel中。
模型结构
9、在使用混合精度的FP16时,对于所有不同架构设计,设置尺寸为8的倍数
训练
10、将batch size设置为8的倍数,最大化GPU内存的使用
11、前向的时候使用混合精度(后向的使用不用)
12、在优化器更新权重之前,设置梯度为
None,model.zero_grad(set_to_none=True)13、梯度积累:每隔x个batch更新一次权重,模拟大batch size的效果
推理/验证
14、关闭梯度计算
CNN (卷积神经网络) 特有的
15、
torch.backends.cudnn.benchmark = True16、对于4D NCHW Tensors,使用channels_last的内存格式
17、在batch normalization之前的卷积层可以去掉bias
分布式
18、用
DistributedDataParallel代替DataParallel
第7、11、12、13的代码片段
# Combining the tips No.7, 11, 12, 13: nonblocking, AMP, setting
# gradients as None, and larger effective batch size
model.train()
# Reset the gradients to None
optimizer.zero_grad(set_to_none=True)
scaler = GradScaler()
for i, (features, target) in enumerate(dataloader):
# these two calls are nonblocking and overlapping
features = features.to('cuda:0', non_blocking=True)
target = target.to('cuda:0', non_blocking=True)
# Forward pass with mixed precision
with torch.cuda.amp.autocast(): # autocast as a context manager
output = model(features)
loss = criterion(output, target)
# Backward pass without mixed precision
# It's not recommended to use mixed precision for backward pass
# Because we need more precise loss
scaler.scale(loss).backward()
# Only update weights every other 2 iterations
# Effective batch size is doubled
if (i+1) % 2 == 0 or (i+1) == len(dataloader):
# scaler.step() first unscales the gradients .
# If these gradients contain infs or NaNs,
# optimizer.step() is skipped.
scaler.step(optimizer)
# If optimizer.step() was skipped,
# scaling factor is reduced by the backoff_factor
# in GradScaler()
scaler.update()
# Reset the gradients to None
optimizer.zero_grad(set_to_none=True)
指导思想
总的来说,你可以通过3个关键点来优化时间和内存使用。首先,尽可能减少i/o(输入/输出),使模型管道更多的用于计算,而不是用于i/o(带宽限制或内存限制)。这样,我们就可以利用GPU及其他专用硬件来加速这些计算。第二,尽量重叠过程,以节省时间。第三,最大限度地提高内存使用效率,节约内存。然后,节省内存可以启用更大的batch size大小,从而节省更多的时间。拥有更多的时间有助于更快的模型开发周期,并导致更好的模型性能。
1、把数据移动到SSD中
有些机器有不同的硬盘驱动器,如HHD和SSD。建议将项目中使用的数据移动到SSD(或具有更好i/o的硬盘驱动器)以获得更快的速度。
2. 在加载数据和数据增强的时候异步处理
num_workers=0使数据加载需要在训练完成后或前一个处理已完成后进行。设置num_workers>0有望加快速度,特别是对于大数据的i/o和增强。具体到GPU,有实验发现num_workers = 4*num_GPU 具有最好的性能。也就是说,你也可以为你的机器测试最佳的num_workers。需要注意的是,高num_workers将会有很大的内存消耗开销,这也是意料之中的,因为更多的数据副本正在内存中同时处理。
Dataloader(dataset, num_workers=4*num_GPU)
3. 使用pinned memory来降低数据传输
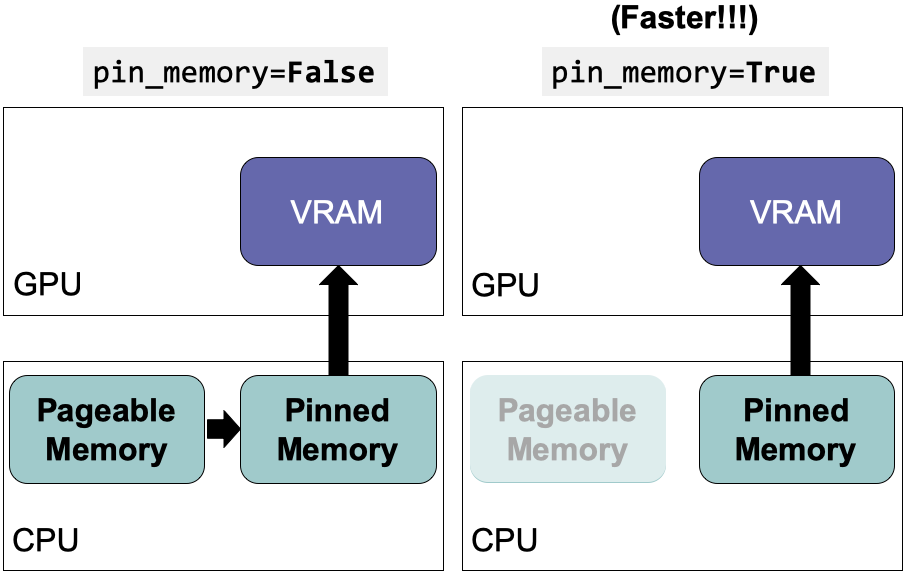
GPU无法直接从CPU的可分页内存中访问数据。设置pin_memory=True 可以为CPU主机上的数据直接分配临时内存,节省将数据从可分页内存转移到临时内存(即固定内存又称页面锁定内存)的时间。该设置可以与num_workers = 4*num_GPU结合使用。
Dataloader(dataset, pin_memory=True)
4. 直接在设备中创建张量
只要你需要torch.Tensor,首先尝试在要使用它们的设备上创建它们。不要使用原生Python或NumPy创建数据,然后将其转换为torch.Tensor。在大多数情况下,如果你要在GPU中使用它们,直接在GPU中创建它们。
# Random numbers between 0 and 1
# Same as np.random.rand([10,5])
tensor = torch.rand([10, 5], device=torch.device('cuda:0'))
# Random numbers from normal distribution with mean 0 and variance 1
# Same as np.random.randn([10,5])
tensor = torch.randn([10, 5], device=torch.device('cuda:0'))
唯一的语法差异是NumPy中的随机数生成需要额外的random,例如:np.random.rand() vs torch.rand()。许多其他函数在NumPy中也有相应的函数:
torch.empty(), torch.zeros(), torch.full(), torch.ones(), torch.eye(), torch.randint(), torch.rand(), torch.randn()
5. 避免在CPU和GPU中传输数据
正如我在指导思想中提到的,我们希望尽可能地减少I/O。注意下面这些命令:
# BAD! AVOID THEM IF UNNECESSARY!
print(cuda_tensor)
cuda_tensor.cpu()
cuda_tensor.to_device('cpu')
cpu_tensor.cuda()
cpu_tensor.to_device('cuda')
cuda_tensor.item()
cuda_tensor.numpy()
cuda_tensor.nonzero()
cuda_tensor.tolist()
# Python control flow which depends on operation results of CUDA tensors
if (cuda_tensor != 0).all():
run_func()
6. 使用 torch.from_numpy(numpy_array)和torch.as_tensor(others)代替 torch.tensor
torch.tensor()会拷贝数据
如果源设备和目标设备都是CPU,torch.from_numpy和torch.as_tensor不会创建数据拷贝。如果源数据是NumPy数组,使用torch.from_numpy(numpy_array) 会更快。如果源数据是一个具有相同数据类型和设备类型的张量,那么torch.as_tensor(others) 可以避免拷贝数据。others 可以是Python的list, tuple,或者torch.tensor。如果源设备和目标设备不同,那么我们可以使用下一个技巧。
torch.from_numpy(numpy_array)
torch.as_tensor(others)
7. 在数据传输有重叠时使用tensor.to(non_blocking=True)
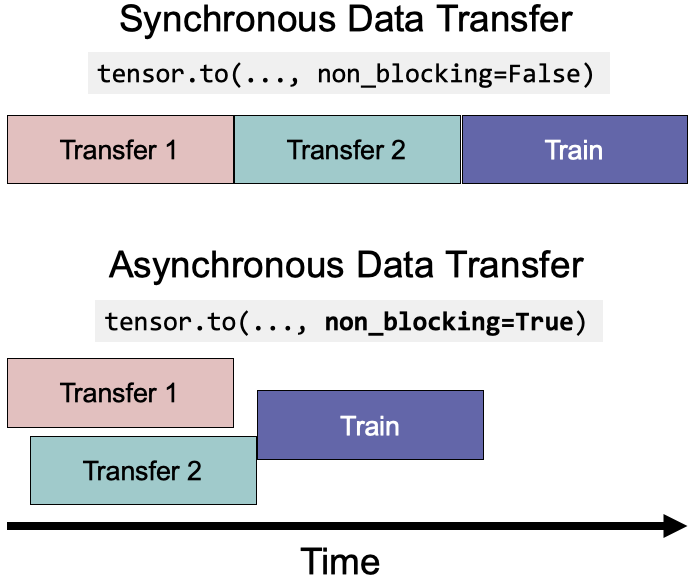
本质上,non_blocking=True允许异步数据传输以减少执行时间。
for features, target in loader:
# these two calls are nonblocking and overlapping
features = features.to('cuda:0', non_blocking=True)
target = target.to('cuda:0', non_blocking=True)
# This is a synchronization point
# It will wait for previous two lines
output = model(features)
8. 使用PyTorch JIT将点操作融合到单个kernel中
点操作包括常见的数学操作,通常是内存受限的。PyTorch JIT会自动将相邻的点操作融合到一个内核中,以保存多次内存读/写操作。例如,通过将5个核融合成1个核,gelu函数可以被加速4倍。
@torch.jit.script # JIT decorator
def fused_gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
9 & 10. 在使用混合精度的FP16时,对于所有不同架构设计,设置图像尺寸和batch size为8的倍数
为了最大限度地提高GPU的计算效率,最好保证不同的架构设计(包括神经网络的输入输出尺寸/维数/通道数和batch size大小)是8的倍数甚至更大的2的幂(如64、128和最大256)。这是因为当矩阵的维数与2的幂倍数对齐时,Nvidia gpu的张量核心(Tensor Cores)在矩阵乘法方面可以获得最佳性能。矩阵乘法是最常用的操作,也可能是瓶颈,所以它是我们能确保张量/矩阵/向量的维数能被2的幂整除的最好方法(例如,8、64、128,最多256)。
这些实验显示设置输出维度和batch size大小为8的倍数,比如(33712、4088、4096)相比33708,batch size为4084或者4095这些不能被8整除的数可以加速计算1.3倍到 4倍。加速度大小取决于过程类型(例如,向前传递或梯度计算)和cuBLAS版本。特别是,如果你使用NLP,请记住检查输出维度,这通常是词汇表大小。
使用大于256的倍数不会增加更多的好处,但也没有害处。这些设置取决于cuBLAS和cuDNN版本以及GPU架构。你可以在文档中找到矩阵维数的特定张量核心要求。由于目前PyTorch AMP多使用FP16,而FP16需要8的倍数,所以通常推荐使用8的倍数。如果你有更高级的GPU,比如A100,那么你可以选择64的倍数。如果你使用的是AMD GPU,你可能需要检查AMD的文档。
除了将batch size大小设置为8的倍数外,我们还将batch size大小最大化,直到它达到GPU的内存限制。这样,我们可以用更少的时间来完成一个epoch。
11. 在前向中使用混合精度后向中不使用
有些操作不需要float64或float32的精度。因此,将操作设置为较低的精度可以节省内存和执行时间。对于各种应用,英伟达报告称具有Tensor Cores的GPU的混合精度可以提高3.5到25倍的速度。
值得注意的是,通常矩阵越大,混合精度加速度越高。在较大的神经网络中(例如BERT),实验表明混合精度可以加快2.75倍的训练,并减少37%的内存使用。具有Volta, Turing, Ampere或Hopper架构的较新的GPU设备(例如,T4, V100, RTX 2060, 2070, 2080, 2080 Ti, A100, RTX 3090, RTX 3080,和RTX 3070)可以从混合精度中受益更多,因为他们有Tensor Core架构,它相比CUDA cores有特殊的优化。

值得一提的是,采用Hopper架构的H100预计将于2022年第三季度发布,支持FP8 (float8)。PyTorch AMP可能会支持FP8(目前v1.11.0还不支持FP8)。
在实践中,你需要在模型精度性能和速度性能之间找到一个最佳点。我之前确实发现混合精度可能会降低模型的精度,这取决于算法,数据和问题。
使用自动混合精度(AMP)很容易在PyTorch中利用混合精度。PyTorch中的默认浮点类型是float32。AMP将通过使用float16来进行一组操作(例如,matmul, linear, conv2d)来节省内存和时间。AMP会自动cast到float32的一些操作(例如,mse_loss, softmax等)。有些操作(例如add)可以操作最宽的输入类型。例如,如果一个变量是float32,另一个变量是float16,那么加法结果将是float32。
autocast自动应用精度到不同的操作。因为损失和梯度是按照float16精度计算的,当它们太小时,梯度可能会“下溢”并变成零。GradScaler通过将损失乘以一个比例因子来防止下溢,根据比例损失计算梯度,然后在优化器更新权重之前取消梯度的比例。如果缩放因子太大或太小,并导致inf或NaN,则缩放因子将在下一个迭代中更新缩放因子。
scaler = GradScaler()
for features, target in data:
# Forward pass with mixed precision
with torch.cuda.amp.autocast(): # autocast as a context manager
output = model(features)
loss = criterion(output, target)
# Backward pass without mixed precision
# It's not recommended to use mixed precision for backward pass
# Because we need more precise loss
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients .
# If these gradients contain infs or NaNs,
# optimizer.step() is skipped.
scaler.step(optimizer)
# If optimizer.step() was skipped,
# scaling factor is reduced by the backoff_factor in GradScaler()
scaler.update()
你也可以使用autocast 作为前向传递函数的装饰器。
class AutocastModel(nn.Module):
...
@autocast() # autocast as a decorator
def forward(self, input):
x = self.model(input)
return x
12. 在优化器更新权重之前将梯度设置为None
通过model.zero_grad()或optimizer.zero_grad()将对所有参数执行memset ,并通过读写操作更新梯度。但是,将梯度设置为None将不会执行memset,并且将使用“只写”操作更新梯度。因此,设置梯度为None更快。
# Reset gradients before each step of optimizer
for param in model.parameters():
param.grad = None
# or (PyTorch >= 1.7)
model.zero_grad(set_to_none=True)
# or (PyTorch >= 1.7)
optimizer.zero_grad(set_to_none=True)
13. 梯度累积:每隔x个batch再更新梯度,模拟大batch size
这个技巧是关于从更多的数据样本积累梯度,以便对梯度的估计更准确,权重更新更接近局部/全局最小值。这在batch size较小的情况下更有帮助(由于GPU内存限制较小或每个样本的数据量较大)。
for i, (features, target) in enumerate(dataloader):
# Forward pass
output = model(features)
loss = criterion(output, target)
# Backward pass
loss.backward()
# Only update weights every other 2 iterations
# Effective batch size is doubled
if (i+1) % 2 == 0 or (i+1) == len(dataloader):
# Update weights
optimizer.step()
# Reset the gradients to None
optimizer.zero_grad(set_to_none=True)
14. 在推理和验证的时候禁用梯度计算
实际上,如果只计算模型的输出,那么梯度计算对于推断和验证步骤并不是必需的。PyTorch使用一个中间内存缓冲区来处理requires_grad=True变量中涉及的操作。因此,如果我们知道不需要任何涉及梯度的操作,通过禁用梯度计算来进行推断/验证,就可以避免使用额外的资源。
# torch.no_grad() as a context manager:
with torch.no_grad():
output = model(input)
# torch.no_grad() as a function decorator:
@torch.no_grad()
def validation(model, input):
output = model(input)
return output
15. torch.backends.cudnn.benchmark = True
在训练循环之前设置torch.backends.cudnn.benchmark = True可以加速计算。由于计算不同内核大小卷积的cuDNN算法的性能不同,自动调优器可以运行一个基准来找到最佳算法。当你的输入大小不经常改变时,建议开启这个设置。如果输入大小经常改变,那么自动调优器就需要太频繁地进行基准测试,这可能会损害性能。它可以将向前和向后传播速度提高1.27x到1.70x。
torch.backends.cudnn.benchmark = True
16. 对于4D NCHW Tensors使用通道在最后的内存格式

使用channels_last内存格式以逐像素的方式保存图像,作为内存中最密集的格式。原始4D NCHW张量在内存中按每个通道(红/绿/蓝)顺序存储。转换之后,x = x.to(memory_format=torch.channels_last),数据在内存中被重组为NHWC (channels_last格式)。你可以看到RGB层的每个像素更近了。据报道,这种NHWC格式与FP16的AMP一起使用可以获得8%到35%的加速。
目前,它仍处于beta测试阶段,仅支持4D NCHW张量和一组模型(例如,alexnet,mnasnet家族,mobilenet_v2,resnet家族,shufflenet_v2,squeezenet1,vgg家族)。但我可以肯定,这将成为一个标准的优化。
N, C, H, W = 10, 3, 32, 32
x = torch.rand(N, C, H, W)
# Stride is the gap between one element to the next one
# in a dimension.
print(x.stride())
# (3072, 1024, 32, 1)# Convert the tensor to NHWC in memory
x2 = x.to(memory_format=torch.channels_last)
print(x2.shape) # (10, 3, 32, 32) as dimensions order preserved
print(x2.stride()) # (3072, 1, 96, 3), which are smaller
print((x==x2).all()) # True because the values were not changed
17. 在batch normalization之前禁用卷积层的bias
这是可行的,因为在数学上,bias可以通过batch normalization的均值减法来抵消。我们可以节省模型参数、运行时的内存。
nn.Conv2d(..., bias=False)
18. 使用 DistributedDataParallel代替DataParallel
对于多GPU来说,即使只有单个节点,也总是优先使用 DistributedDataParallel而不是 DataParallel ,因为 DistributedDataParallel 应用于多进程,并为每个GPU创建一个进程,从而绕过Python全局解释器锁(GIL)并提高速度。
总结
在这篇文章中,我列出了一个清单,并提供了18个PyTorch技巧的代码片段。然后,我逐一解释了它们在不同方面的工作原理和原因,包括数据加载、数据操作、模型架构、训练、推断、cnn特定的优化和分布式计算。一旦你深入理解了它们的工作原理,你可能会找到适用于任何深度学习框架中的深度学习建模的通用原则。

英文原文:https://towardsdatascience.com/optimize-pytorch-performance-for-speed-and-memory-efficiency-2022-84f453916ea6
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
