
使用pytorch mask-rcnn进行目标检测/分割训练
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

现在github上面有3个版本的mask-rcnn, keras, caffe(Detectron), pytorch,这几个版本中,据说pytorch是性能最佳的一个,于是就开始使用它进行训练,然而实际跑通的过程中也遇到了不少问题,记录一下。
官方源代码: https://github.com/facebookresearch/maskrcnn-benchmark
安装
参照 https://github.com/facebookresearch/maskrcnn-benchmark作者给的说明进行安装。需要注意两个点:
gcc >= 4.9,否则会出现吐核的错误。具体安装方法写在下面吐核的内容里了。
pytorch==1.0, 安装0.4.0等版本均会报错
作者说是因为gcc版本过低引起的,尝试了很多更新gcc的方法,都有各种问题,最后通过这位小哥的方法成功更新:
https://link.zhihu.com/?target=https%3A//gist.github.com/craigminihan/b23c06afd9073ec32e0c
升级完gcc(>=4.9.0)之后呢, 可能会出现类似 /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found 的报错,主要是升级gcc生成的动态库没有替换老版本gcc的动态库。参考方法可见:
https://blog.csdn.net/xg123321123/article/details/78117162
在自己的数据上训练
数据集组织:参见COCO的数据集格式,你可以使用COCO数据集或者将自己的数据集转为COCO进行训练。当然也可以自己改写Dataset类来加载数据。
我是通过
Pascal
提供的https://github.com/pascal1129/kaggle_airbus_ship_detection/tree/master/0_rle_to_coco将数据集转换为COCO格式的json annotation格式的。
在分配好你的训练集、验证集和测试集后,并获取了对应的annotation文件后,通过修改/maskrcnn-benchmark/maskrcnn-benchmark/config/paths_catalog.py这个文件的DatasetCatalog类来修改目录。
class DatasetCatalog(object):
DATA_DIR = "datasets"
DATASETS = {
"coco_2017_train": {
"img_dir": "coco/train2017",
"ann_file": "coco/annotations/instances_train2017.json"
},
"coco_2017_val": {
"img_dir": "coco/val2017",
"ann_file": "coco/annotations/instances_val2017.json"
}
}同时在/maskrcnn-benchmark/configs/下的你选用的配置文件yaml修改DATASETS参数,注意这里不是直接目录的地方,而是使用前面的DatasetCatalog类中的DATASETS的键值作为索引:
DATASETS:
TRAIN: ("coco_2014_train", "coco_2014_val")
TEST: ("coco_2014_val",)准备好数据集之后,官方提供的默认类别是81,而你的数据集可能只有1个类别,所以需要在/maskrcnn-benchmark/maskrcnn_benchmark/config/defaults.py中修改C.MODEL.ROI_BOX_HEAD.NUM_CLASSES参数。注意,这个参数应该是类别+1(即background),所以只有一类时应该设置为2
接下来就可以按照官方的traning代码进行单GPU/多GPU训练啦
python /path_to_maskrcnn_benchmark/tools/train_net.py --config-file "/path/to/config/file.yaml"开始训练之后过不了几个iter就会出现所有的Loss为nan的现象,这是由于学习率过大引起的,自己调小就可以了。另外默认的版本是用的是warm up lr,所以开始的几个epoch可能和你设定的不一样,没关系~另外,配置参数有两个地点,一个是yaml文件,另外一个是defaults.py, 有一些相同的参数,yaml的会覆盖defaults.py的,大家配置的参数在这两个文件里找就好了。
可视化
该版本的master分支上还没有可视化的实现,实际上可以通过继承MetricLogger来实现,相关的内容在merge request https://github.com/achalddave/maskrcnn-benchmark/commit/4210b77d4aef69c411200b13c93d7e2fe628164d已经实现了,根据文中描述修改完代码后直接运行tensorboard命令即可
tensorboard --logdir=path/to/log-directory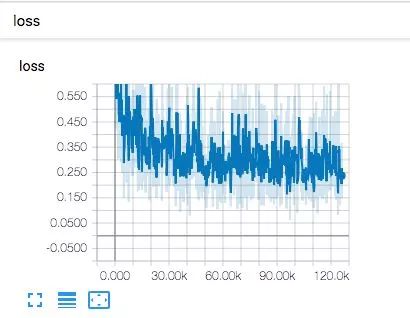
Fine-tune on Pre-trained Model
如果你引用了NUM_CLASS与你的数据不一致的预训练模型,就会出现类似
size mismatch for roi_heads.mask.predictor.mask_fcn_logits.weight: copying a param with shape torch.Size([81, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([2, 256, 1, 1])
的报错。这是因为logitis层的class类别不一致导致的。可以通过删除预训练中包含logits层的参数来解决冲突。使用gist.github.com/wangg12 中提供的脚本对下载的比如说Detectron的预训练模型进行转化,再在yaml文件中将WEIGHT参数改为预训练模型pkl路径即可。
重设学习率
我开始训练的时候遇到一个问题就是改变学习率的参数重新开始训练时,加载的还是上次训练设置的参数。这个问题是由于pytorch在加载checkpoint的时候会把之前训练的optimizer和scheduler一起加载进来。所以如果要重新设置学习率的话,需要在加载state_dict的时候不启用上次训练保存的optimizer和scheduler参数。把maskrcnn_benchmark/utils/checkpoint.py文件中用于load optimizer和scheduler的两行代码注掉就可以了:
if "optimizer" in checkpoint and self.optimizer:
self.logger.info("Loading optimizer from {}".format(f))
# self.optimizer.load_state_dict(checkpoint.pop("optimizer"))
if "scheduler" in checkpoint and self.scheduler:
self.logger.info("Loading scheduler from {}".format(f))
# self.scheduler.load_state_dict(checkpoint.pop("scheduler"))
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~