
蚂蚁开源新算法,给大模型提提速!

ChatGPT Plus 一个月就要 20 美元 ,这是笔不小的费用。虽然已经是尊贵的 Plus 用户,但 每次 输 入一个问题后,还是需要等待一段时间才能拿到结果,感觉就像逐字蹦出来的一样。 这 是什么原因呢?
其实,回答的响应速度与服务成本,关键在于 推理效率 ,这也是大模型目前主要技术攻坚方向之一。
近日,蚂蚁开源了一套新算法—— Lookahead 推理加速框架 ,它能做到效果无损、即插即用,实现无痛推理加速, 支持 包括 Llama、OPT、Bloom、GPTJ、GPT2、Baichuan、ChatGLM、GLM 和 Qwen 在内的一系列模型。 该算法 已在蚂蚁大量场景进行了落地,实际获得了 2.66-6.26 倍的加速比,大幅降低了推理耗时。
下面,让我们一起来看看这个算法的加速效果和背后的原理。
加速效果
耳听为虚眼见为实,下面就以蚂蚁百灵大模型 AntGLM 10B 为例,实测一下面对同样的一个问题,生成答案的速度区别。
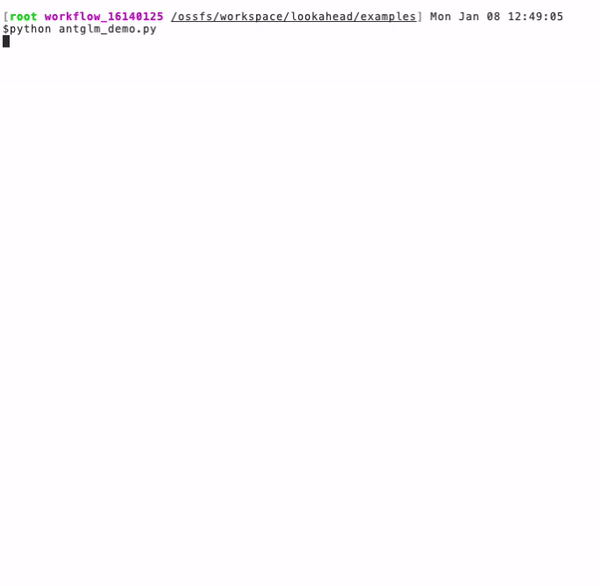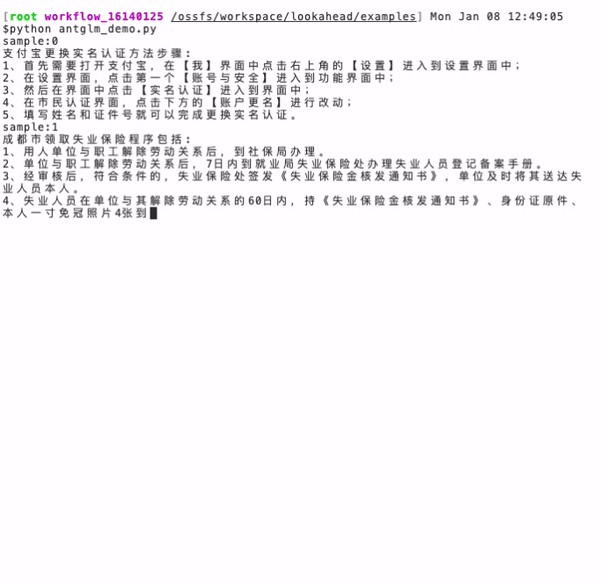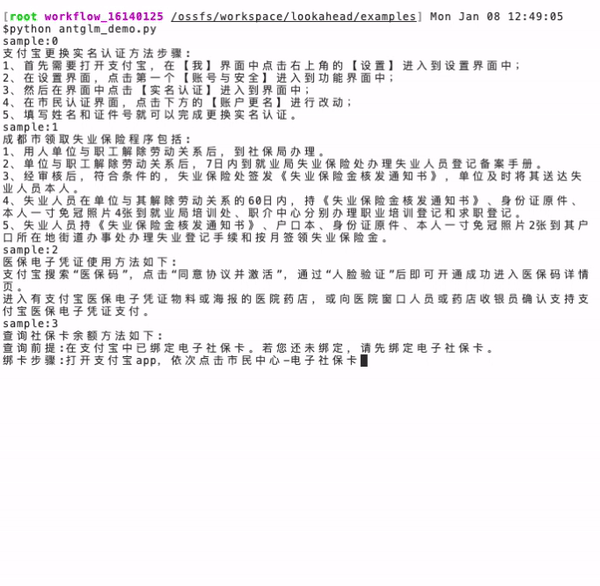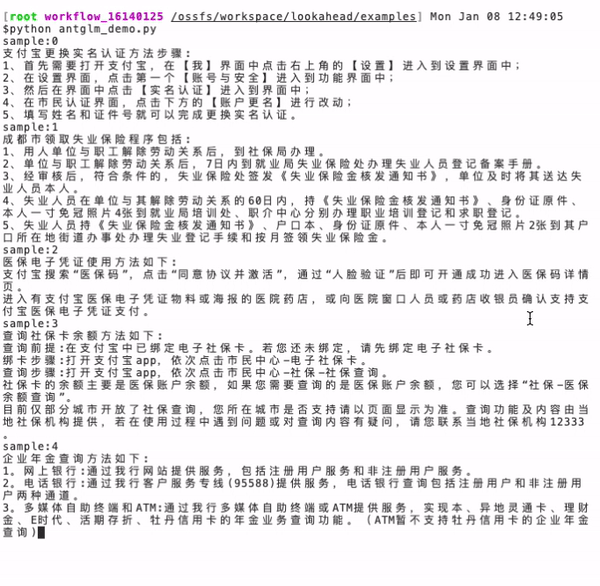

左图(当前主流算法):耗时 16.9 秒,token 生成速度为 33.8 个/秒。
右图(蚂蚁 Lookahead 推理算法): 耗时 3.9 秒,token 生成速度为 147.6 个/秒,速度提升了 4.37 倍。
| AntGLM 10B 模型 | 耗时 | 生成速度 |
|---|---|---|
| 主流算法 | 16.9s | 33.8 token/s |
| Lookahead 算法 | 3.9s | 147.6 token/s |


左图(当前主流算法):耗时 15.7 秒,token 生成速度为 48.2 个/秒;
右图(蚂蚁 Lookahead 推理算法): 耗时 6.4 秒,token生成速度为 112.9 个/秒,速度提升了 2.34 倍。
| Llama2-7B-chat 模型 |
耗时 | 生成速度 |
|---|---|---|
| 主流算法 | 15.7s | 48.2 token/s |
| Lookahead 算法 | 6.4s | 112.9 token/s |
技术原理
当下的大模型基本都是基于自回归解码,每一步解码仅生成一个 token,这种操作方式既浪费了 GPU 的并行处理能力,也导致用户体验延迟过高,影响使用流畅度。
业内有少量的优化算法,主要集中在如何生成更好的草稿(即猜测生成 token 的序列)上,但是实践证明草稿在超过 30 个 token 长度后,端到端的推理效率就无法 进一步提高,但是这个长度远没有 充分利用 GPU 的运算能力。
为了进一步 压榨硬件性能,蚂蚁 Lookahead 推理加速算法采用了 多分支的策略 ,即草稿序列不再仅仅包含一条分支,而是包含多条并行的分支,多条分支在一次前向过程中进行并行验证。 因此可以在耗时基本不变的前提下,提高一次前向过程生成的 token 个数。
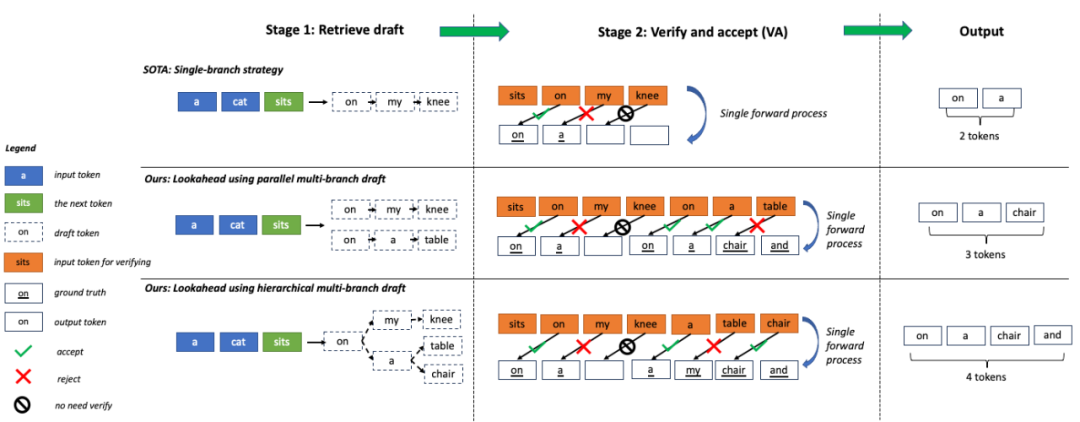
再进一步 ,蚂蚁 Lookahead 推理加速算法利用 trie 树存储和检索 token 序列,并将多条草稿中相同的父节点进行合并,进一步提高了计算效率。 为了提高易用性,trie 树的构建不依赖额外的草稿模型,只利用推理过程中的 prompt 及生成的回答进行动态构建,降低了用户的接入成本。
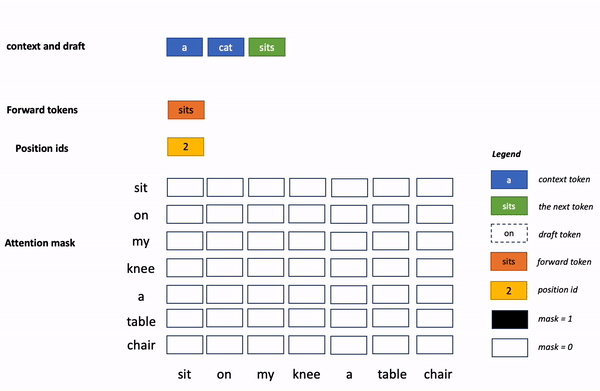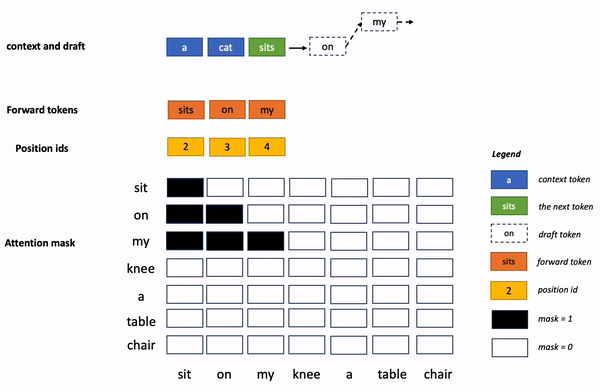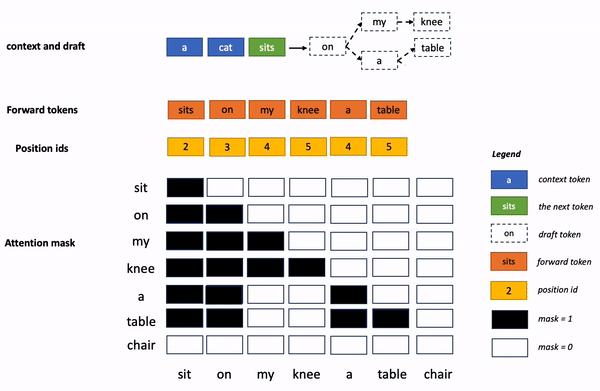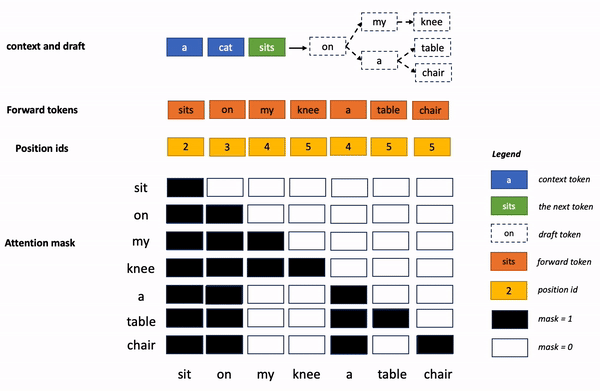
上面的专业术语有点多,非专业的读者理解起来有点困难。 换个通俗易懂的说 法,再解释一下:
原来的 token 生成过程,就像早期中文输入法,只能一个字一个字“敲”出来,采用了蚂蚁的加速算法后,token 生成就像联想输入法,有些整句可直接“蹦”出来。
最后
蚂蚁 Lookahead 推理加速算法在检索增强生成(RAG)场景及公开数据集进行了测试。
-
在蚂蚁内部的 RAG 数据集上,AntGLM10B 模型的加速比达到 5.36,token 生成速度 280 个/秒;
-
在 Dolly15k 及 GSM8K 数据集上, 多个开源模型都 有 2 倍以上的加速比,与此同时,显存增加和内存消耗几乎可以忽略。
该算法现已在 GitHub 上开源,相关论文也已公布在 ARXIV。感兴趣的同学可以阅读下相关论文了解更多技术细节,运行下源码查看效果。
论文地址 : https://arxiv.org/abs/2312.12728
代码仓库: https://github.com/alipay/PainlessInferenceAcceleration
- END - 👆 关注「HelloGitHub」收到第一时间的更新 👆