
ICCV 2023|IDEA研究院12篇入选论文亮点解读
近日,ICCV 2023正式公布论文收录结果,IDEA研究院12篇论文入选,在开放词表目标检测与分割、交互式关键点标注、可控文生图、3D目标检测、3D重建、肖像视频生成等领域取得新成果。
ICCV(国际计算机视觉大会,International Conference on Computer Vision)是计算机视觉领域的顶级会议之一,每两年召开一次。根据Google Scholar Metrics 2022年榜单,ICCV在所有计算机科学领域的刊物和会议中位居第4。ICCV 2023将于10月2日至10月6日法国巴黎举办。
跟随本期文章了解IDEA研究院CV领域的部分学术成果,欢迎感兴趣的读者阅读论文原文。
来源:IDEA数字经济研究院
仅用于学术分享,如有侵权,请联系删除


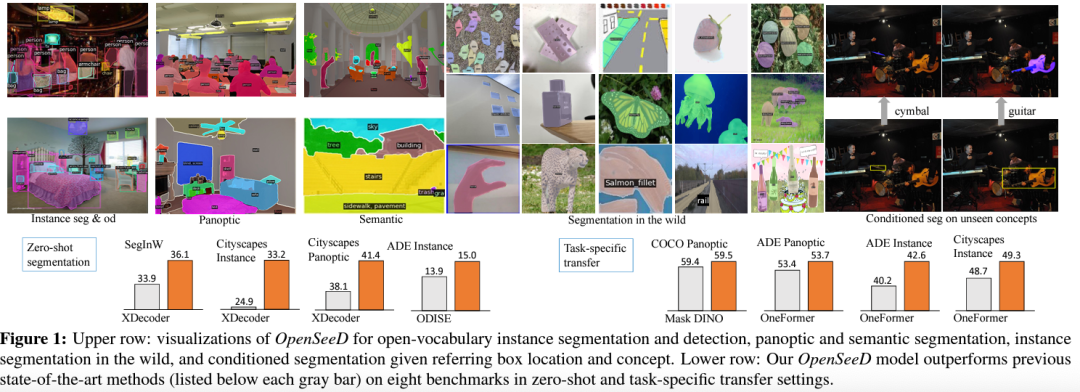
简单有效的开放词表分割框架,未见之物亦可分割,是已知的第一个同时训练全景分割和目标检测提升开集分割性能的模型。
摘要:本文提出了一个开放词表图像分割和检测的框架,解决了检测和分割同时训练过程中的data gap和 training gap,实现了两大任务在开放词表内的联合训练,并大大提升了分割性能。本文在COCO全景分割榜单取得SOTA,并在多个开集分割任务上超越主流方法。
论文链接:
https://arxiv.org/pdf/2303.08131.pdf
代码链接:
https://github.com/IDEA-Research/OpenSeeD


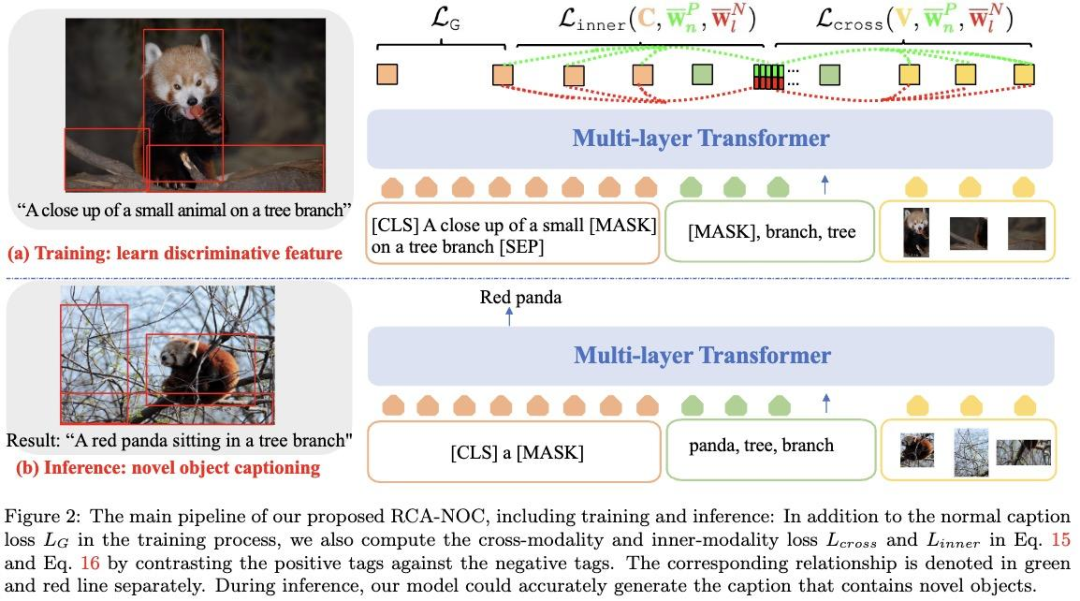
一个改进新物体标题生成任务多模态表示能力的全新方法。
摘要:本文提出了一种新型的新物体图像标题生成方法,该方法采用相对对比学习来学习视觉和语义对齐,以最大化区域与物体标签的兼容性。为了设置合适的对比学习目标,对于每一张图片,我们使用CLIP来扩增标签,并利用每个扩增标签的排序位置作为相对的相关性标签,将每个排名最高的标签与一组排名较低的标签进行对比。这个学习目标鼓励排名最高的标签与其图片和文本上下文的兼容性超过排名较低的标签,从而提高了学习的多模态表示的辨别能力。我们在两个数据集上评估了我们的方法,RCA-NOC大幅度超越了目前最好的方法,展示出其在改进新物体标题生成任务上的视觉-语言表示的有效性。
(论文链接待公开)


首次定义交互式关键点检测任务,基准框架方法标注效率超越纯手工10+倍。
摘要:本文首次定义了交互式关键点检测的任务,旨在追求高精度和低成本的标注,并提出了解决该任务的基准框架 Click-Pose,在训练中引入姿态误差建模和交互式人类反馈循环。本方案可以稳定提升标注效率和质量,我们在不同的标注场景中广泛验证了Click-Pose的交互式标注有效性,相对手工标注效率提升10倍以上,相对SOTA模型结合人工修改可提升5倍左右,且实现了端到端关键点检测的最先进性能。

(论文链接待公开)


比ControlNet更可控更高效的人体图像生成模型HumanSD。
摘要:本文提出了一个可控人物图像生成方法HumanSD,旨在高效、准确、原生地控制以人为中心的图片的生成。具体来说,HumanSD使用一种新颖的热图引导去噪损失(heatmap-guided denoising loss)来微调预训练的Stable Diffusion模型,这种策略有效加强了骨骼条件的控制力,同时减轻了灾难性遗忘效应。相比ControlNet、T2I-Adapter等即插即用的双分支控制方法,HumanSD展现了更优的可控力和更快的生成速度,其中可控精度提升73%。同时,我们提供了适用于人体生成的大规模公开数据集用于后续研究。

论文链接:
https://arxiv.org/abs/2304.04269
代码链接:
https://github.com/IDEA-Research/HumanSD


一个全新基础算子以及基于其实现2D特征拉升至3D空间的新方法。
摘要:本文提出了一个基础算子:3D Deformable Attention(DFA3D)。基于DFA3D,我们提出了一种全新的将2D特征拉升到3D空间的方法。我们与其他的特征拉升方法(Lift-Splat-based、2D Deformable Attention-based等)进行了公平比较,结果验证了我们DFA3D-based的方法的优越性。我们在多个多视角3D目标检测方法上进行对比实验,进一步验证了我们的方法的有效性和泛化性。

(论文链接待公开)


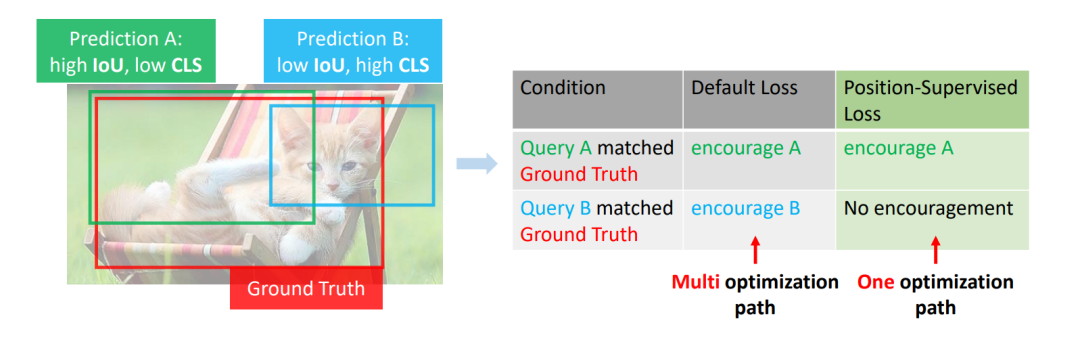
通过在损失中仅引入位置度量来改进DETR模型匹配稳定性,大幅提升性能。
摘要:本文指出DETR中存在的不稳定匹配问题是由多重优化路径所导致,这一问题在DETR的one-to-one matching中更加明显。论文表明,仅需要在分类损失中引入了位置度量即可很好地优化问题。基于这一原则,我们通过引入了位置度量信息,提出了两个简单有效并且可适用于所有DETR系列模型的position-supervised loss和position-modulated matching cost设计。
我们基于DETR系列模型对方法的有效性进行了验证,其中,Stable-DINO在以ResNet-50作为backbone的条件下,在1x和2x标准settings下分别达到了50.4AP和51.5AP。本文方法具有强大的可拓展性,使用Swin-Large和Focal-Huge backbone的条件下,Stable-DINO在COCO test-dev上分别达到了63.8AP和64.8AP的准确率。
论文链接:
https://arxiv.org/abs/2304.04742
代码链接:
https://github.com/IDEA-Research/Stable-DINO


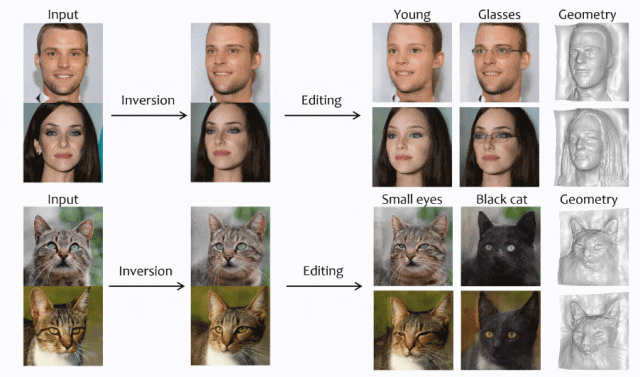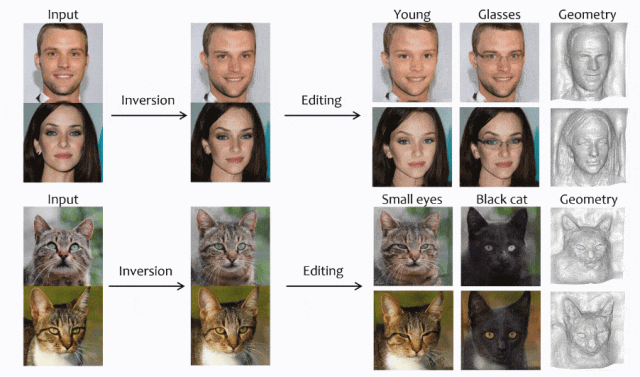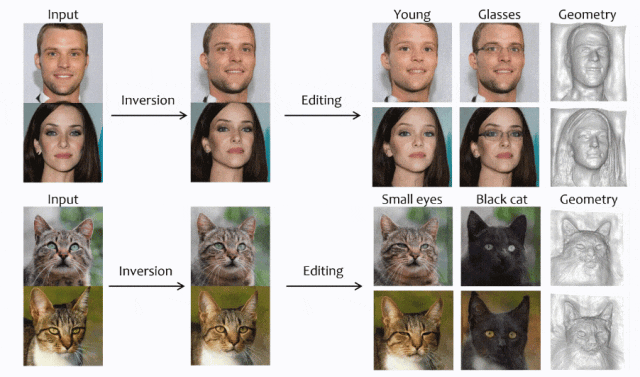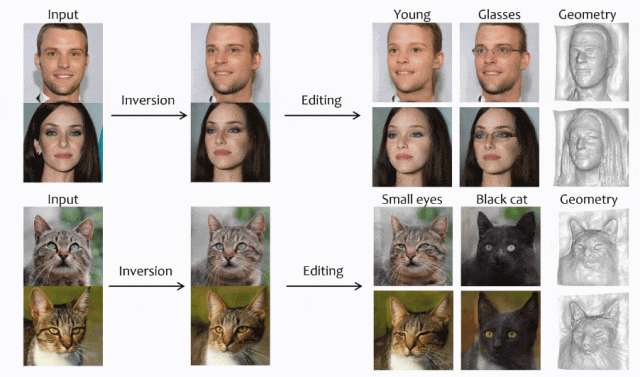
一个基于编码器、从单图进行3D重建的高效方法。
摘要:3D GAN Inversion旨在从单个图像输入中同时实现高重建保真度和合理的3D几何。然而,现有的3D GAN Inversion方法依赖于耗时的优化过程,并且是每张图片单独优化。在这项工作中,我们介绍了一种基于EG3D的新型基于编码器的Inversion框架,EG3D是最广泛使用的3D GAN模型之一。我们利用EG3D隐空间的固有属性,设计了一个鉴别器和背景深度正则化,训练出一个具备几何感知能力的编码器,能够将输入图像转换为相应的隐空间向量。此外,我们探索了EG3D的特征空间,并开发了一个自适应细化阶段,以提高EG3D中特征的表示能力,从而增强细粒度纹理细节的恢复。最后,我们提出了一种考虑遮挡的融合操作,以防止未观察区域的畸变。我们的方法结果可与基于优化的方法媲美,同时运行速度提高了500倍。我们的框架非常适用于语义编辑等应用。
论文链接:
https://arxiv.org/pdf/2303.12326.pdf
代码链接:
https://eg3d-goae.github.io/


从蒸馏到自蒸馏:通用归一化损失与定制化软标签。
摘要:知识蒸馏(KD)使用教师的预测logits作为软标签来指导学生,而自知蒸馏则不需要真实的教师来提供软标签。本研究通过将通用的KD损失分解和重新组织,将这两个任务的公式统一为标准化KD(NKD)损失和针对目标类别(图像的类别)和非目标类别的定制软标签,命名为通用自知蒸馏(USKD)。我们将KD损失分解,并发现其中的非目标损失强制使学生的非目标logits与教师的相匹配,但两个非目标logits的总和不同,防止它们完全相同。NKD将非目标logits进行归一化,使它们的总和相等。它可以广泛应用于KD和自知蒸馏,以更好地利用软标签进行蒸馏损失。USKD为目标和非目标类别生成定制的软标签,而无需教师。它将学生的目标logit平滑处理为软目标标签,并利用中间特征的排名按照Zipf定律生成软非目标标签。对于带有教师的KD,我们的NKD在CIFAR-100和ImageNet数据集上实现了最先进的性能,使用ResNet-34教师将ResNet18的ImageNet Top-1准确率从69.90%提升到71.96%。对于没有教师的自知蒸馏,USKD是第一个可以有效应用于CNN和ViT模型的自知蒸馏方法,额外的时间和内存开销可以忽略不计,从而获得了新的最先进结果,例如在ImageNet上,MobileNet和DeiT-Tiny分别获得了1.17%和0.55%的准确率提升。
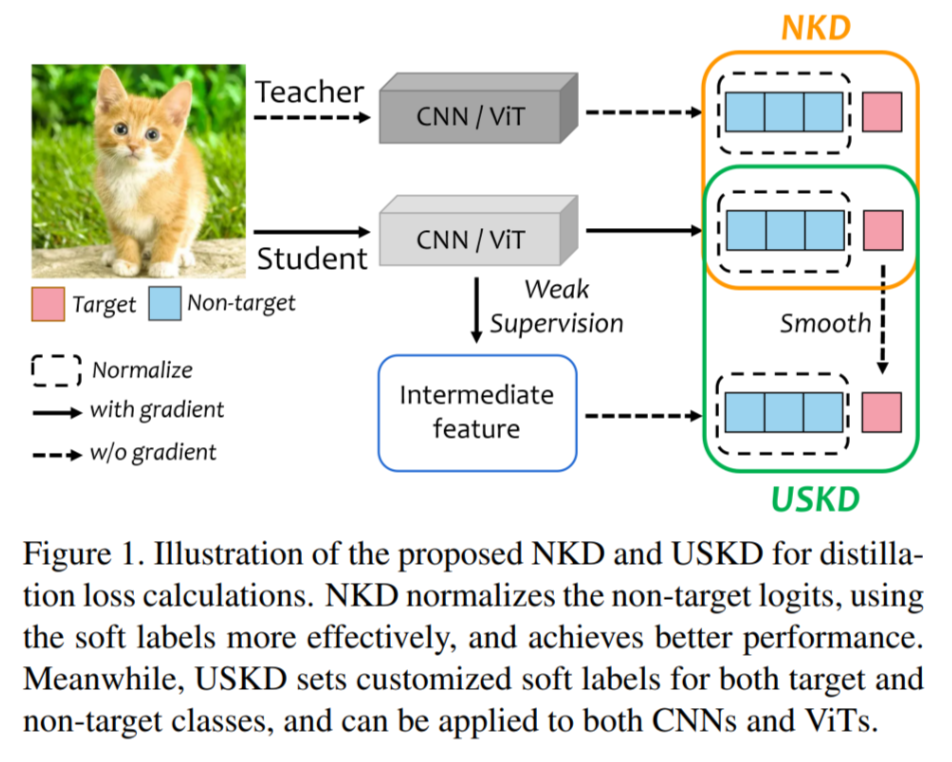
论文链接:
https://arxiv.org/pdf/2303.13005.pdf
代码链接:
https://github.com/yzd-v/cls_KD


一个从音频驱动指定人物生成高保真且多样的肖像视频的框架。
摘要:音频驱动的肖像视频生成旨在通过给定的音频驱动指定肖像的视频。驱动保真度和多模态的肖像视频肖像具有广泛应用。以往的方法尝试通过训练不同模型或从给定视频中提取信号来捕捉不同的运动模式,以此生成高保真度的肖像视频。然而,缺乏音-唇同步与其他动作(例如头部姿势/眼睛眨动)之间的相关度学习通常导致不自然的驱动结果。在本文中,我们提出了一个统一的系统,用于多人、多模态和高保真度的说话肖像视频生成。该方法包含三个阶段:1)带有双重注意力的网络(MODA)从给定音频中生成说话相关的表征。在MODA中,我们设计了一个双重注意力模块,以编码准确的口部动作和多样的模态信息。2)面部合成网络生成密集且详细的面部关键点。3)时序引导的渲染器合成稳定的视频。广泛的评估结果表明,所提出的系统比同期其他方法生成的视频肖像更加自然和逼真。
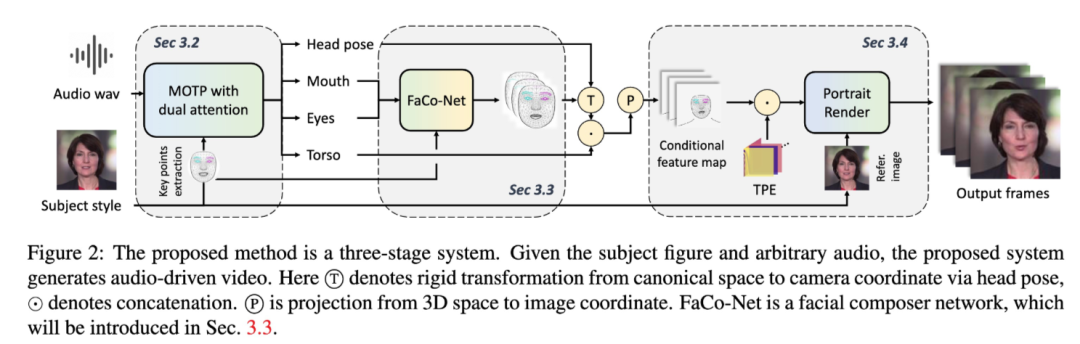
项目链接:
https://liuyunfei.net/projects/iccv23-moda
代码:
https://github.com/DreamtaleCore/MODA


一个基于Transformer的高精度单目3D人脸重建模型。
摘要:精确地从单目图像和视频中重建3D人脸对于各种应用至关重要,例如数字化角色创建等。然而,目前基于深度学习的方法在实现准确重建的过程中,确保解耦面部参数和视频数据处理的稳定性方面面临着重大挑战。在本文中,我们提出了一种基于Transformer的单目3D人脸重建模型TokenFace。TokenFace使用不同面部元素的独立Token来捕捉不同面部参数的信息,并采用时间Transformer从视频数据中捕捉时间信息。这种设计可以自然地解开不同的面部元素,并对2D和3D训练数据都兼具灵活性。在混合2D和3D数据上训练后,该模型能够在图像上准确重建人脸并对视频数据达到稳定重建的能力。在基准数据集NoW和Stirling上进行的实验结果表明,TokenFace在所有指标上达到了最先进的性能,大幅优于同期其他方法。

(论文链接待公开)


首个纯ViT架构的视频分割方法,可借助自监督预训练的ViT(如MAE)大幅提升性能。
摘要:当前流行的视频对象分割(VOS)方法通过多个手工设计的模块实现特征匹配,这些模块分别执行特征提取和匹配。然而,上述手工设计的方法在经验上导致目标交互不足,从而限制了VOS中动态目标感知特征学习的发展。为了解决这些限制,本文提出了一个简化的VOS(SimVOS)框架,通过利用单个Transformer骨干网络来执行联合特征提取和匹配。这种设计使SimVOS能够学习更好的针对目标的特征,从而实现准确的mask预测。更重要的是,SimVOS可以直接使用预训练的ViT骨干网络(如MAE)进行视频分割,从而弥合了VOS和大规模自监督预训练之间的差距。为了在性能和速度之间取得更好的平衡,我们进一步探索了帧内注意力,并提出了一种新的token细调模块来提高运行速度和节省计算成本。在不使用任何合成视频和BL30K预训练数据的情况下,我们取得了DAVIS-2017(88.0% J&F),DAVIS-2016(92.9% J&F)和YouTube-VOS 2019(84.2% J&F)的SOTA结果。

(论文链接待公开)
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2022
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
