
ArrayList和LinkedList使用不当,性能差距会如此之大!
前言
在面试的时候,经常会被问到几个问题:
ArrayList和LinkedList的区别,相信大部分朋友都能回答上:
ArrayList是基于数组实现,LinkedList是基于链表实现
当随机访问List时,ArrayList比LinkedList的效率更高,等等
当被问到ArrayList和LinkedList的使用场景是什么时,大部分朋友的答案可能是:
ArrayList和LinkedList在新增、删除元素时,LinkedList的效率要高于 ArrayList,而在遍历的时候,ArrayList的效率要高于LinkedList
那这个回答是否准确呢?今天我们就来研究研究!
配合这篇文章食用会更香,从源码角度解析ArrayList.subList的几个坑
文章首发在公众号(月伴飞鱼),之后同步到掘金和个人网站:xiaoflyfish.cn/
喜欢的话,之后会分享更多系列文章!
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
微信搜索:月伴飞鱼,交个朋友,进面试交流群
公众号后台回复666,可以获得免费电子书籍
我们先来简单介绍下ArrayList和LinkedList的原理实现!
源码分析
ArrayList
实现类
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
ArrayList实现了List接口,继承了AbstractList抽象类,底层是数组实现的,并且实现了自增扩容数组大小。
ArrayList还实现了Cloneable接口和Serializable接口,所以他可以实现克隆和序列化。
ArrayList还实现了RandomAccess接口,这个接口是一个标志接口,他标志着“只要实现该接口的List类,都能实现快速随机访问”。
基本属性
ArrayList属性主要由数组长度size、对象数组elementData、初始化容量default_capacity等组成, 其中初始化容量默认大小为10。
//默认初始化容量
private static final int DEFAULT_CAPACITY = 10;
//对象数组
transient Object[] elementData;
//数组长度
private int size;
从ArrayList属性来看,elementData被关键字transient修饰了,transient关键字修饰该字段则表示该属性不会被序列化。
但ArrayList其实是实现了序列化接口,这是为什么呢?
由于ArrayList的数组是基于动态扩增的,所以并不是所有被分配的内存空间都存储了数据。
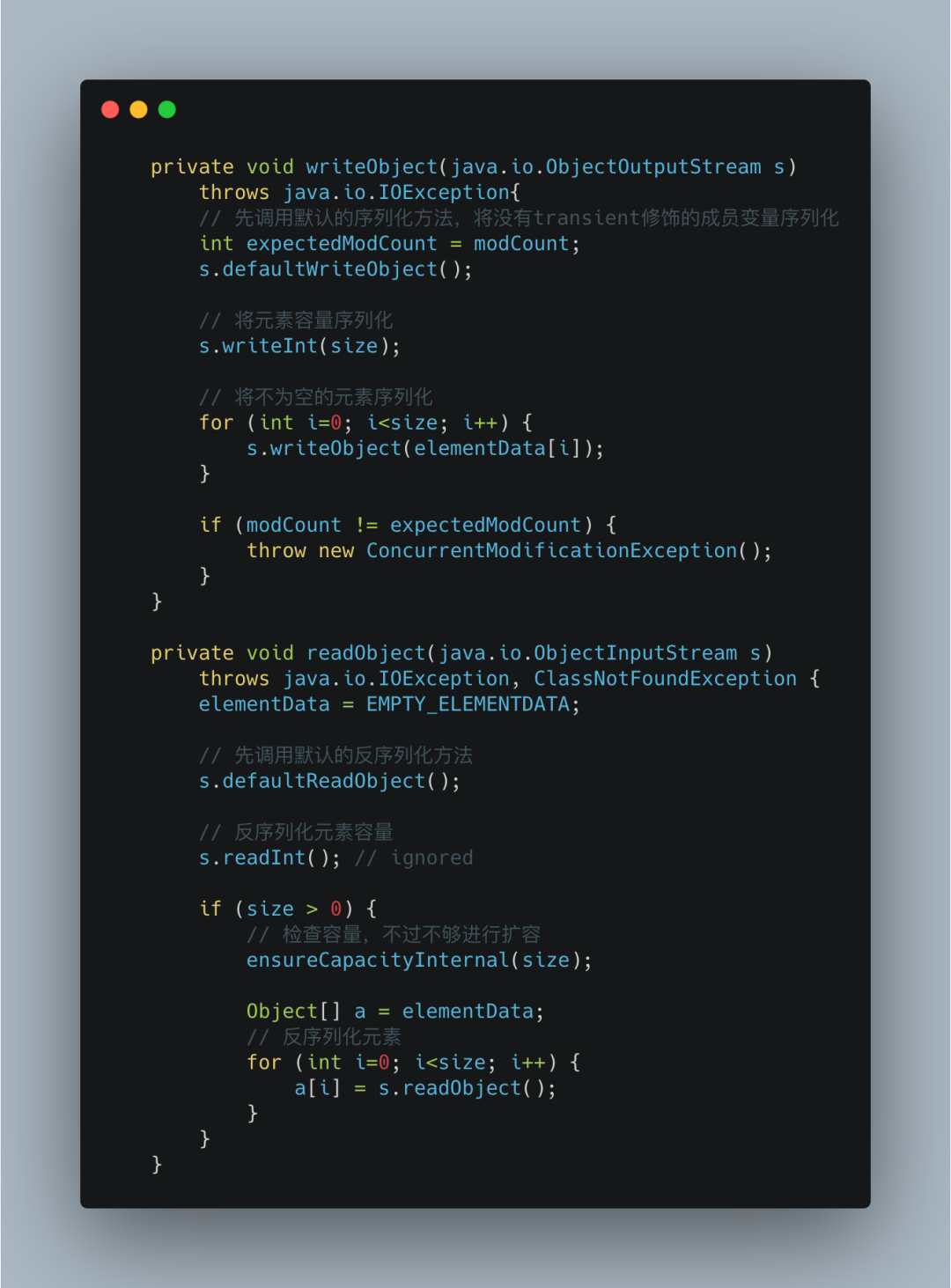
如果采用外部序列化法实现数组的序列化,会序列化整个数组,ArrayList为了避免这些没有存储数据的内存空间被序列化,内部提供了两个私有方法writeObject以及readObject来自我完成序列化与反序列化,从而在序列化与反序列化数组时节省了空间和时间。
因此使用transient修饰数组,是防止对象数组被其他外部方法序列化。
ArrayList自定义序列化方法如下:
初始化
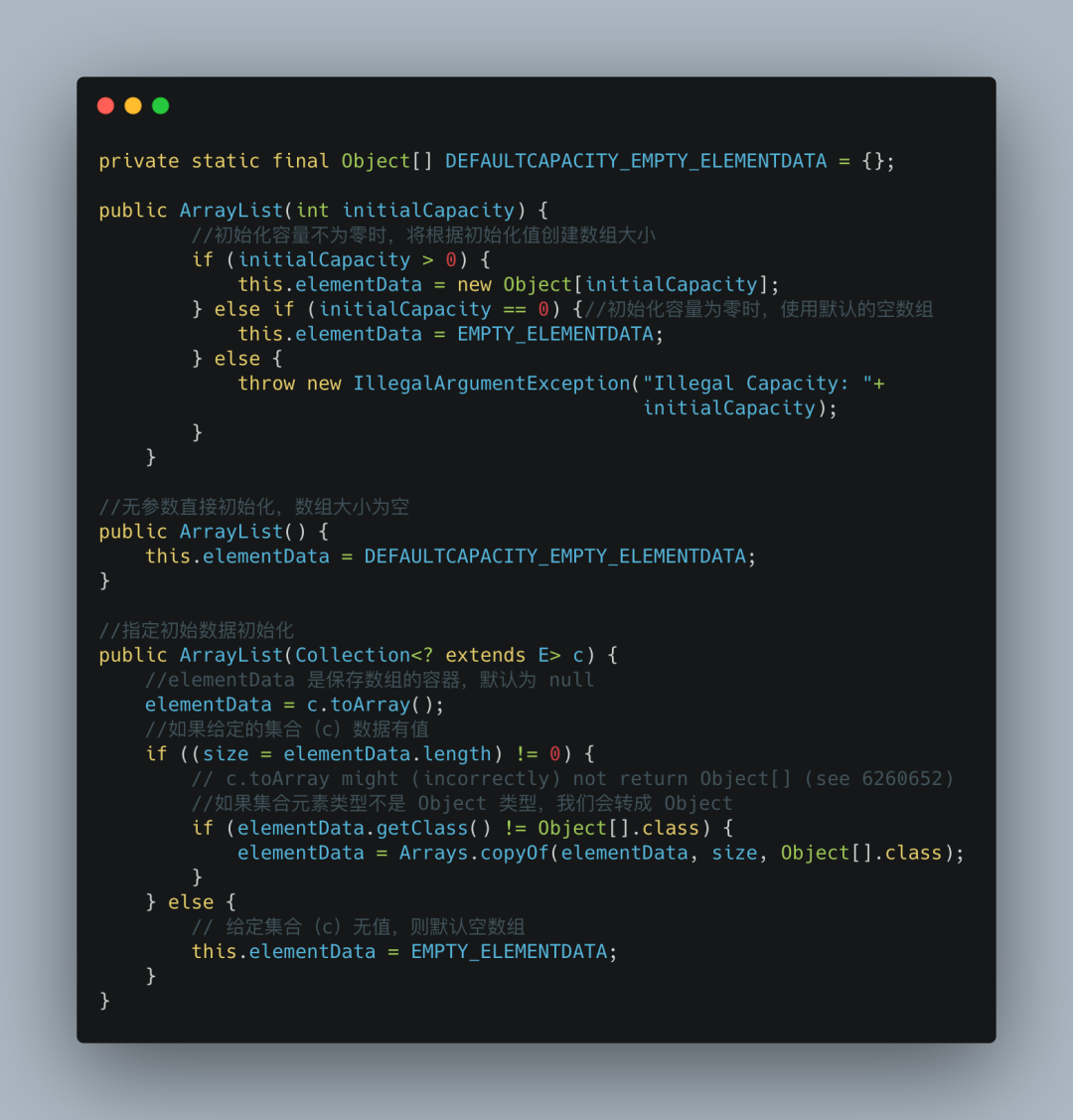
有三种初始化办法:无参数直接初始化、指定大小初始化、指定初始数据初始化,源码如下:
当ArrayList新增元素时,如果所存储的元素已经超过其已有大小,它会计算元素大小后再进行动态扩容,数组的扩容会导致整个数组进行一次内存复制。
因此,我们在初始化ArrayList时,可以通过第一个构造函数合理指定数组初始大小,这样有助于减少数组的扩容次数,从而提高系统性能。
注意点:
ArrayList 无参构造器初始化时,默认大小是空数组,并不是大家常说的 10,10 是在第一次 add 的时候扩容的数组值。
新增元素
ArrayList新增元素的方法有两种,一种是直接将元素加到数组的末尾,另外一种是添加元素到任意位置。
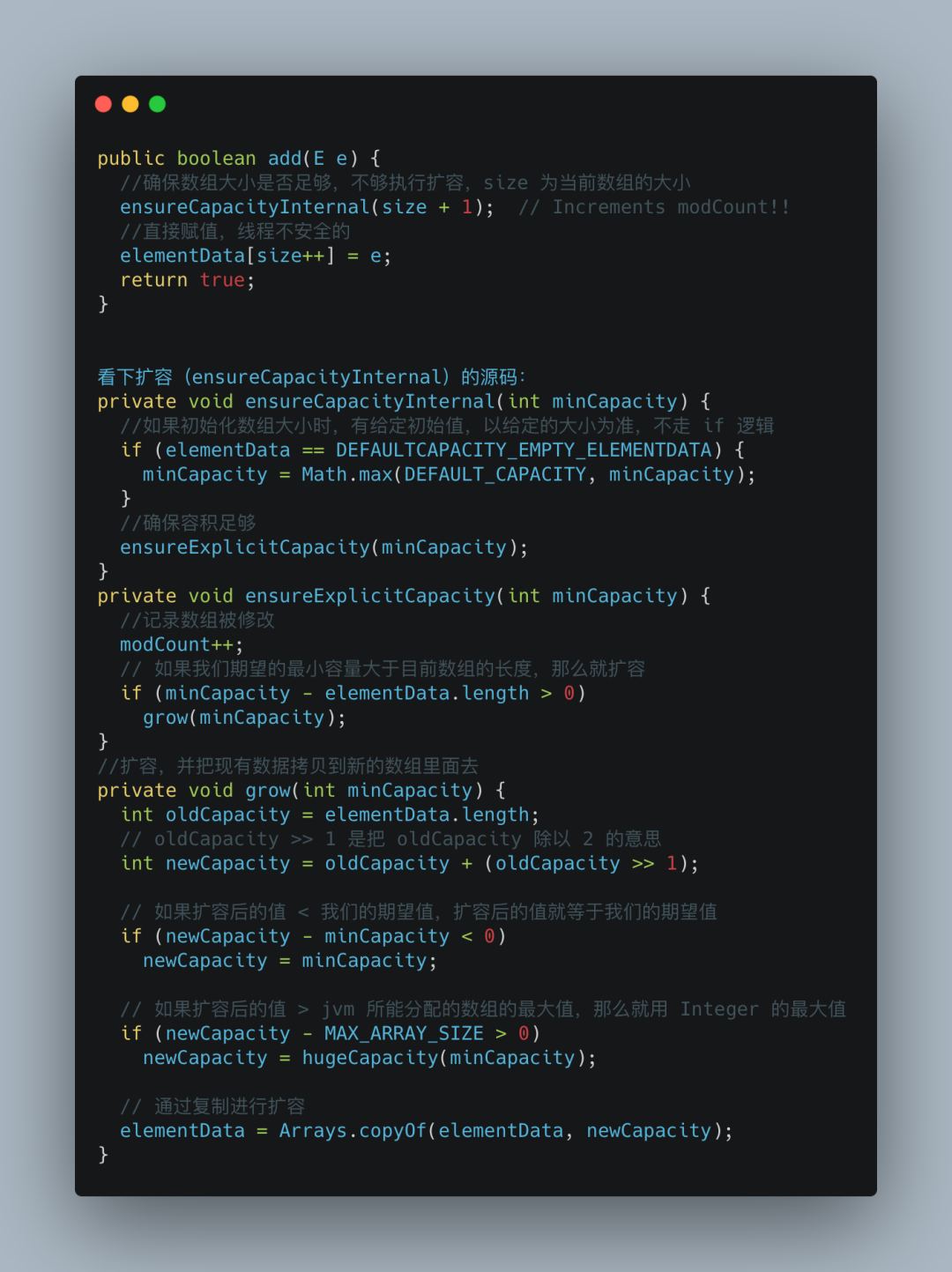
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
两个方法的相同之处是在添加元素之前,都会先确认容量大小,如果容量够大,就不用进行扩容;如果容量不够大,就会按照原来数组的1.5倍大小进行扩容,在扩容之后需要将数组复制到新分配的内存地址。
下面是具体的源码:
这两个方法也有不同之处,添加元素到任意位置,会导致在该位置后的所有元素都需要重新排列,而将元素添加到数组的末尾,在没有发生扩容的前提下,是不会有元素复制排序过程的。
所以ArrayList在大量新增元素的场景下效率不一定就很慢的
如果我们在初始化时就比较清楚存储数据的大小,就可以在ArrayList初始化时指定数组容量大小,并且在添加元素时,只在数组末尾添加元素,那么ArrayList在大量新增元素的场景下,性能并不会变差,反而比其他List集合的性能要好。
删除元素
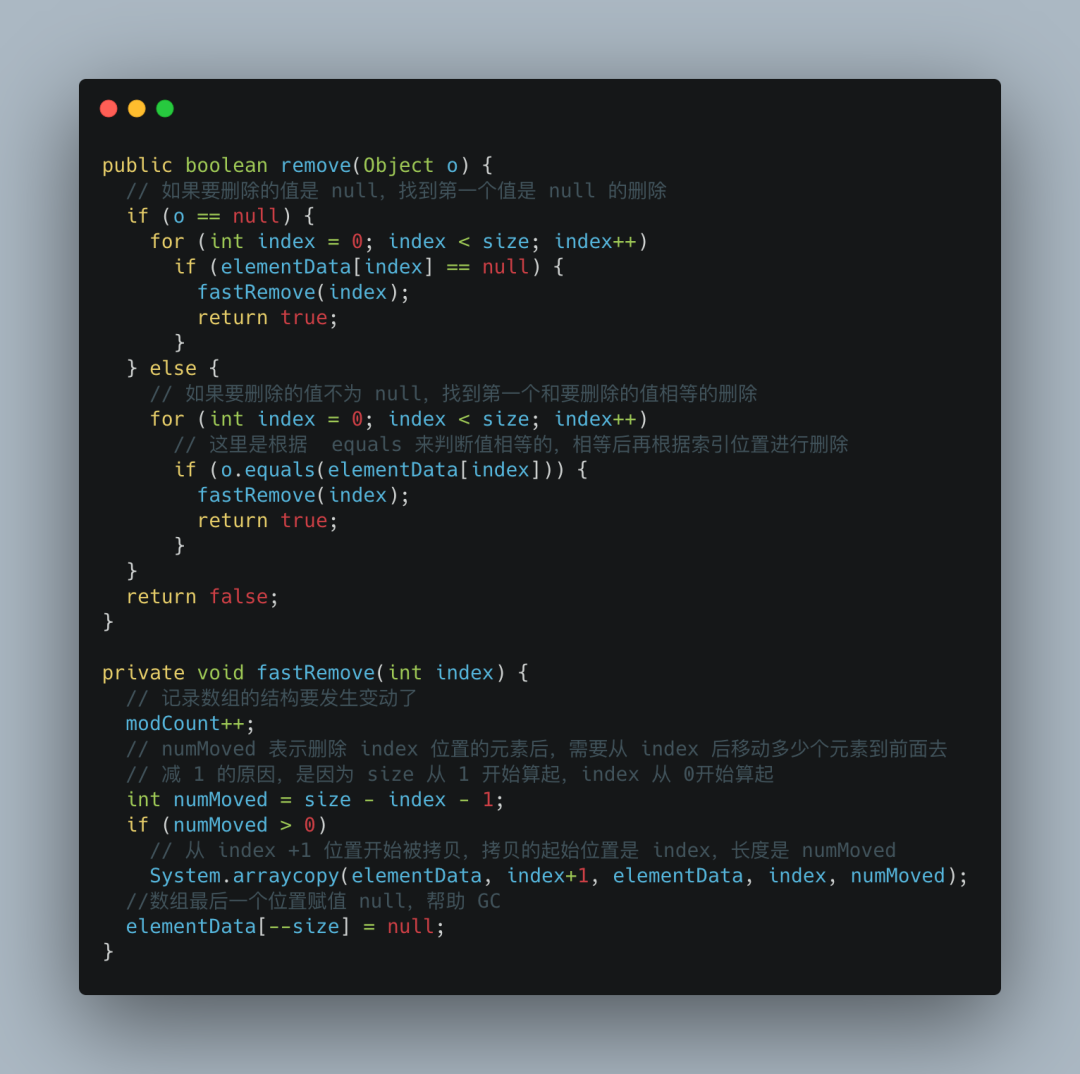
ArrayList 删除元素有很多种方式,比如根据数组索引删除、根据值删除或批量删除等等,原理和思路都差不多。
ArrayList在每一次有效的删除元素操作之后,都要进行数组的重组,并且删除的元素位置越靠前,数组重组的开销就越大。
我们选取根据值删除方式来进行源码说明:
遍历元素
由于ArrayList是基于数组实现的,所以在获取元素的时候是非常快捷的。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
LinkedList
LinkedList是基于双向链表数据结构实现的。
这个双向链表结构,链表中的每个节点都可以向前或者向后追溯,有几个概念如下:
链表每个节点我们叫做 Node,Node 有 prev 属性,代表前一个节点的位置,next 属性,代表后一个节点的位置; first 是双向链表的头节点,它的前一个节点是 null。 last 是双向链表的尾节点,它的后一个节点是 null; 当链表中没有数据时,first 和 last 是同一个节点,前后指向都是 null; 因为是个双向链表,只要机器内存足够强大,是没有大小限制的。
Node结构中包含了3个部分:元素内容item、前指针prev以及后指针next,代码如下。
private static class Node<E> {
E item;// 节点值
Node<E> next; // 指向的下一个节点
Node<E> prev; // 指向的前一个节点
// 初始化参数顺序分别是:前一个节点、本身节点值、后一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList就是由Node结构对象连接而成的一个双向链表。
实现类
LinkedList类实现了List接口、Deque接口,同时继承了AbstractSequentialList抽象类,LinkedList既实现了List类型又有Queue类型的特点;LinkedList也实现了Cloneable和Serializable接口,同ArrayList一样,可以实现克隆和序列化。
由于LinkedList存储数据的内存地址是不连续的,而是通过指针来定位不连续地址,因此,LinkedList不支持随机快速访问,LinkedList也就不能实现RandomAccess接口。
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
基本属性
transient int size = 0;
transient Node first;
transient Node last;
我们可以看到这三个属性都被transient修饰了,原因很简单,我们在序列化的时候不会只对头尾进行序列化,所以LinkedList也是自行实现readObject和writeObject进行序列化与反序列化。
下面是LinkedList自定义序列化的方法。
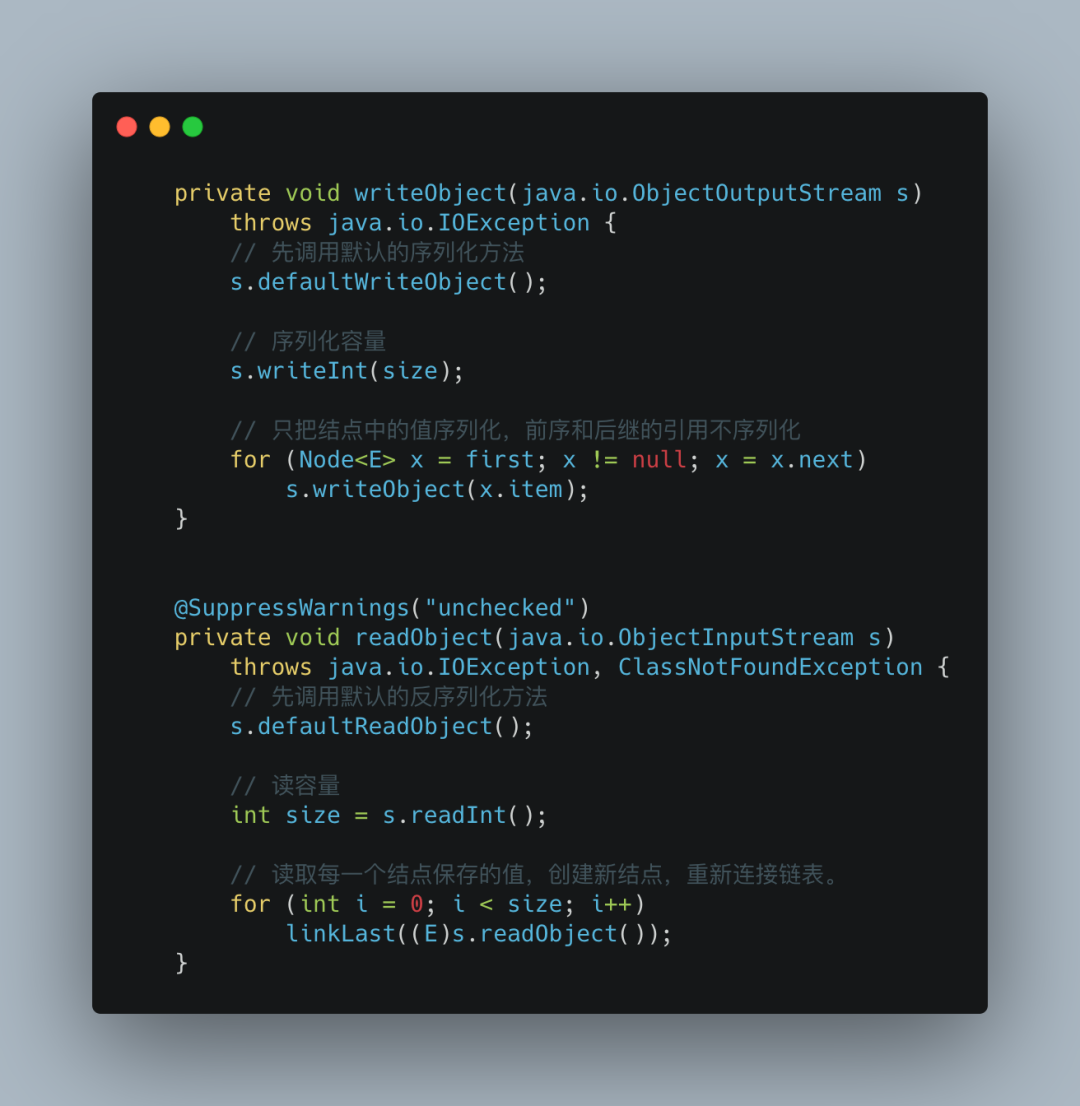
节点查询
链表查询某一个节点是比较慢的,需要挨个循环查找才行,我们看看 LinkedList 的源码是如何寻找节点的:
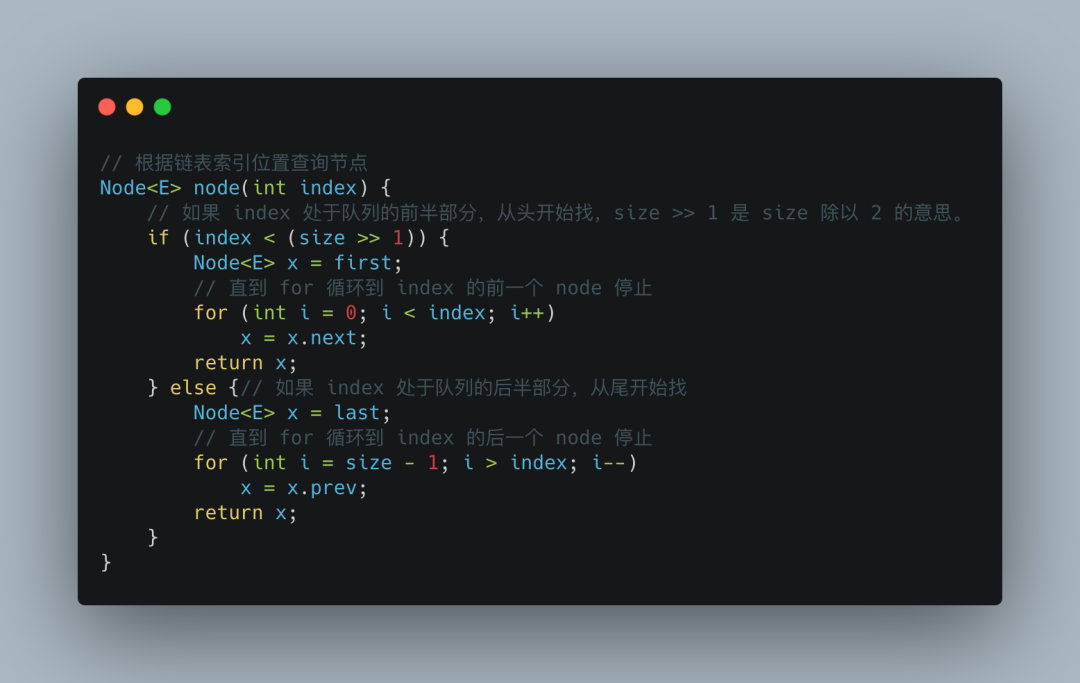
LinkedList 并没有采用从头循环到尾的做法,而是采取了简单二分法,首先看看 index 是在链表的前半部分,还是后半部分。
如果是前半部分,就从头开始寻找,反之亦然。通过这种方式,使循环的次数至少降低了一半,提高了查找的性能。
新增元素
LinkedList添加元素的实现很简洁,但添加的方式却有很多种。
默认的add (Ee)方法是将添加的元素加到队尾,首先是将last元素置换到临时变量中,生成一个新的Node节点对象,然后将last引用指向新节点对象,之前的last对象的前指针指向新节点对象。
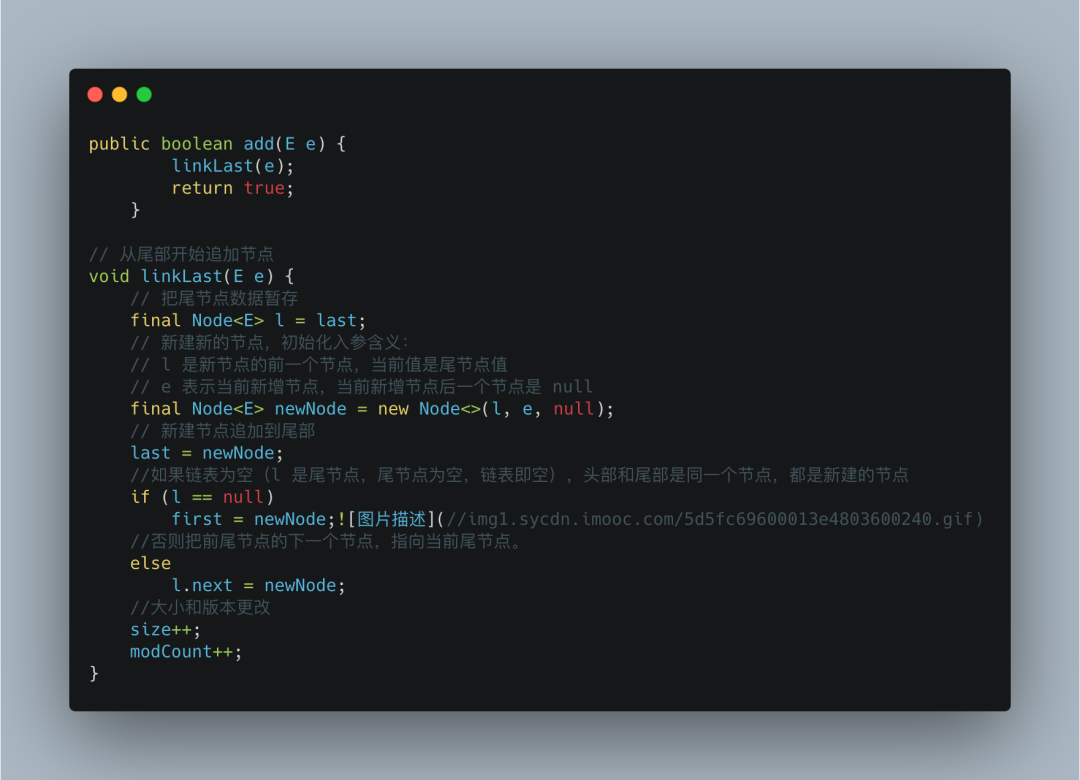
LinkedList也有添加元素到任意位置的方法,如果我们是将元素添加到任意两个元素的中间位置,添加元素操作只会改变前后元素的前后指针,指针将会指向添加的新元素,所以相比ArrayList的添加操作来说,LinkedList的性能优势明显。
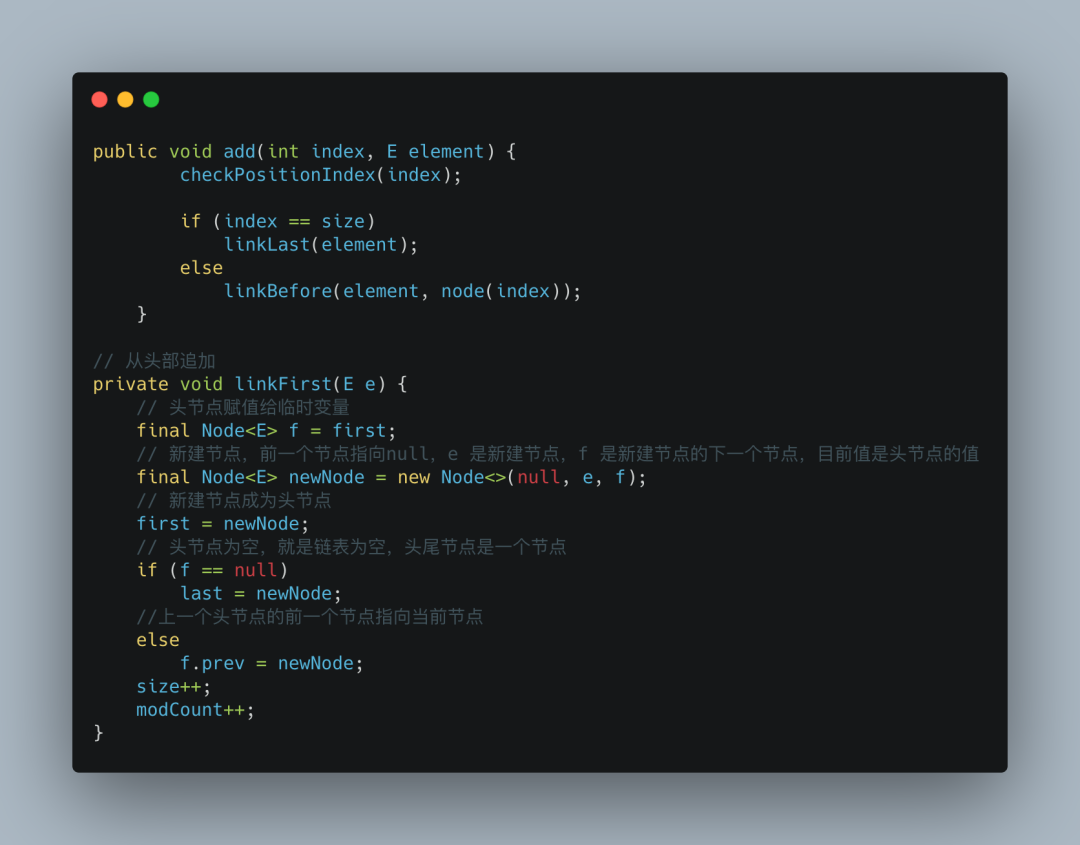
删除元素
在LinkedList删除元素的操作中,我们首先要通过循环找到要删除的元素,如果要删除的位置处于List的前半段,就从前往后找;若其位置处于后半段,就从后往前找。
这样做的话,无论要删除较为靠前或较为靠后的元素都是非常高效的,但如果List拥有大量元素,移除的元素又在List的中间段,那效率相对来说会很低。
遍历元素
LinkedList的获取元素操作实现跟LinkedList的删除元素操作基本类似,通过分前后半段来循环查找到对应的元素,但是通过这种方式来查询元素是非常低效的,特别是在for循环遍历的情况下,每一次循环都会去遍历半个List。
所以在LinkedList循环遍历时,我们可以使用iterator方式迭代循环,直接拿到我们的元素,而不需要通过循环查找List。
分析测试
新增元素操作性能测试
测试用例源代码:
ArrayList:https://paste.ubuntu.com/p/gktBvjgMGk/ LinkedList:https://paste.ubuntu.com/p/3jQrY2XMPr/
测试结果:
| 操作 | 花费时间 |
|---|---|
| 从集合头部位置添加元素(ArrayList) | 550 |
| 从集合头部位置添加元素(LinkedList) | 34 |
| 从集合中间位置位置添加元素(ArrayList) | 32 |
| 从集合中间位置位置添加元素(LinkedList) | 58746 |
| 从集合尾部位置添加元素(ArrayList) | 29 |
| 从集合尾部位置添加元素(LinkedList) | 31 |
通过这组测试,我们可以知道LinkedList添加元素的效率未必要高于ArrayList。
从集合头部位置添加元素
由于ArrayList是数组实现的,在添加元素到数组头部的时候,需要对头部以后的数据进行复制重排,所以效率很低;
LinkedList是基于链表实现,在添加元素的时候,首先会通过循环查找到添加元素的位置,如果要添加的位置处于List的前半段,就从前往后找;若其位置处于后半段,就从后往前找,因此LinkedList添加元素到头部是非常高效的。
从集合中间位置位置添加元素
ArrayList在添加元素到数组中间时,同样有部分数据需要复制重排,效率也不是很高;
LinkedList将元素添加到中间位置,是添加元素最低效率的,因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作。
从集合尾部位置添加元素
而在添加元素到尾部的操作中,在没有扩容的情况下,ArrayList的效率要高于LinkedList。
这是因为ArrayList在添加元素到尾部的时候,不需要复制重排数据,效率非常高。
LinkedList虽然也不用循环查找元素,但LinkedList中多了new对象以及变换指针指向对象的过程,所以效率要低于ArrayList。
注意:这是排除动态扩容数组容量的情况下进行的测试,如果有动态扩容的情况,ArrayList的效率也会降低。
删除元素操作性能测试
ArrayList和LinkedList删除元素操作测试的结果和添加元素操作测试的结果很接近!
结论:如果需要在List的头部进行大量的插入、删除操作,那么直接选择LinkedList。否则,ArrayList即可。
遍历元素操作性能测试
测试用例源代码:
ArrayList:https://paste.ubuntu.com/p/ZNWc9H2pYm/ LinkedList:https://paste.ubuntu.com/p/xSk4nHDHvN/
测试结果:
| 操作 | 花费时间 |
|---|---|
| for循环(ArrayList) | 3 |
| for循环(LinkedList) | 17557 |
| 迭代器循环(ArrayList) | 4 |
| 迭代器循环(LinkedList) | 4 |
我们可以看到,LinkedList的for循环性能是最差的,而ArrayList的for循环性能是最好的。
这是因为LinkedList基于链表实现的,在使用for循环的时候,每一次for循环都会去遍历半个List,所以严重影响了遍历的效率;ArrayList则是基于数组实现的,并且实现了RandomAccess接口标志,意味着ArrayList可以实现快速随机访问,所以for循环效率非常高。
LinkedList的迭代循环遍历和ArrayList的迭代循环遍历性能相当,也不会太差,所以在遍历LinkedList时,我们要切忌使用for循环遍历。
往期精选
