
人人都能读懂的编译器原理

作者注:
简单介绍
编译器是什么?
编译器是做什么的?
从你给定的源代码中读取单个词。
把这些词按照单词、数字、符号、运算符进行分类。
通过模式匹配从分好类的单词中找出运算符,明确这些运算符想进行的运算,然后产生一个运算符的树(表达式树)。
最后一步遍历表达式树中的所有运算符,产生相应的二进制数据。
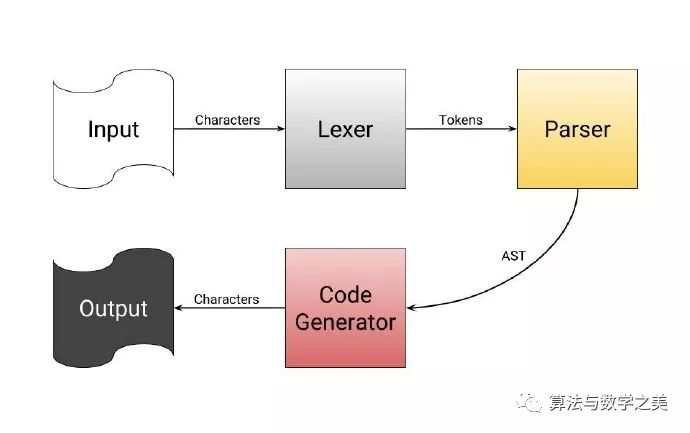
解释器是什么?
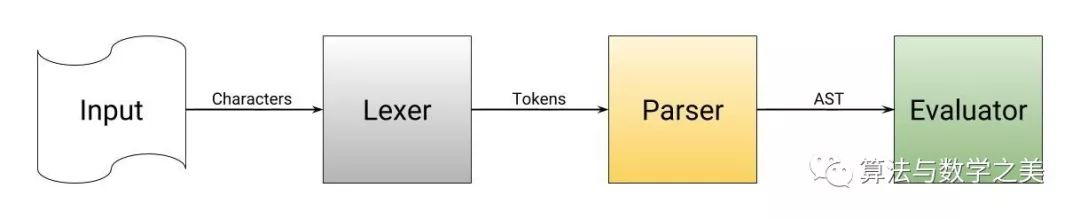
1. 词法分析
2+2 – 其实这个表达式只有三种 标记:一个数字:2,一个加号,另外一个数字:2。12+3 这样的字符串:它会读入字符 1,2,+,和 3。我们已经把这些字符拆分开了,但是现在我们必须把他们组合起来;这是分词器的主要任务之一。举个例子,我们得到了两个单独的字符 1 和 2,但是我们需要把它们放到一起,然后把它们解析成为一个整数。至于 +也需要被识别为加号,而不是它的字符值 – 字符值是43 。2. 解析
int a = 3 和 a: int = 3 的区别在于解析器的处理上面。解析器决定了语法的外在形式是怎样的。它确保括号和花括号的左右括号是数量平衡的,每个语句结尾都有一个分号,每个函数都有一个名称。当标记不符合预期的模式时,解析器就会知道标记的顺序不正确。12+3 :expr 解析器,因为它直接与所有内容都相关的顶层。唯一有效的输入必须是任意数字,加号或减号,任意数字。expr 需要一个 additive_expr,这主要出现在加法和减法表达式中。additive_expr 首先需要一个 term (一个数字),然后是加号或者减号,最后是另一个 term 。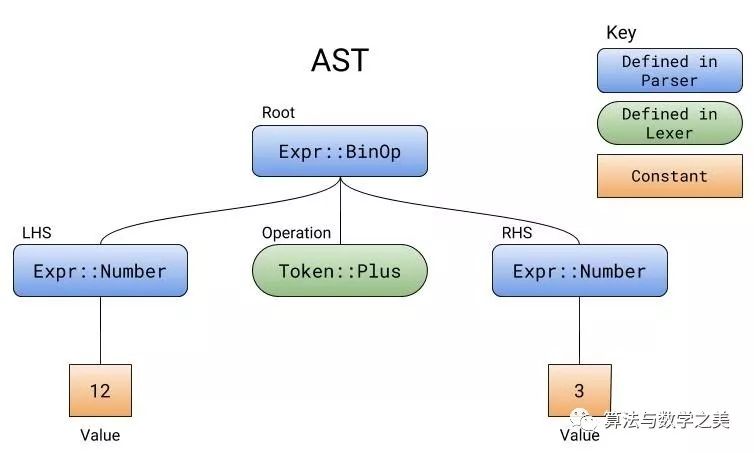
// BEGIN PARSER // 和 // END PARSER // 的注释标记出了新的解析器代码的开头和结尾。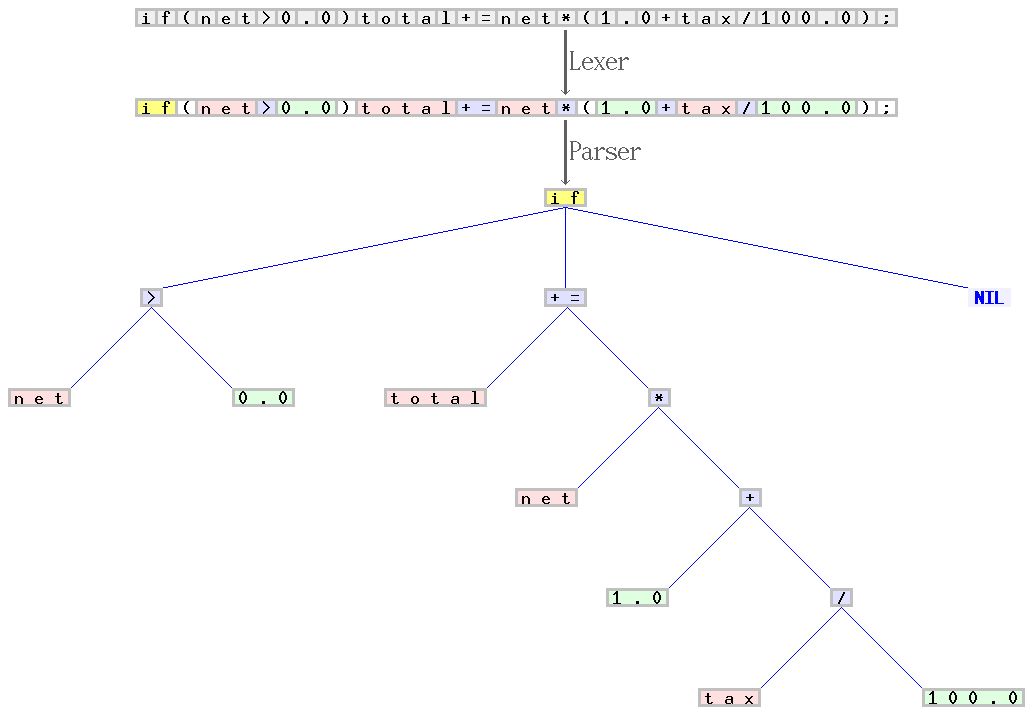
针对 C 语言语法编写的解析器(又叫做词法分析器)和解析器样例。从字符序列的开始 “if(net>0.0)total+=net(1.0+tax/100.0);”,扫描器组成了一系列标记,并且对它们进行分类,例如,标识符,保留字,数字,或者运算符。后者的序列由解析器转换成语法树,然后由其他的编译器分阶段进行处理。扫描器和解析器分别处理 C 语法中的规则和与上下文无关的部分。引自:Jochen Burghardt.来源.
3. 生成代码
-O ).s 或 .asm)。然后该文件会被传递给汇编器,汇编器是汇编语言的编译器,它会生成相应的二进制代码。之后这些二进制代码会被写入到一个新的目标文件中 (.o) 。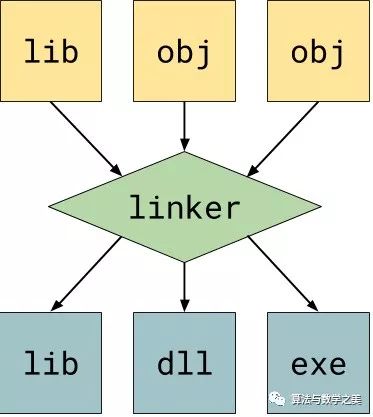
总结
推荐阅读:
专注服务器后台技术栈知识总结分享
欢迎关注交流共同进步
评论