哈佛大学单细胞课程|笔记汇总 (五)
生物信息学习的正确姿势
NGS系列文章包括NGS基础、在线绘图、转录组分析 (Nature重磅综述|关于RNA-seq你想知道的全在这)、ChIP-seq分析 (ChIP-seq基本分析流程)、单细胞测序分析 (重磅综述:三万字长文读懂单细胞RNA测序分析的最佳实践教程)、DNA甲基化分析、重测序分析、GEO数据挖掘(典型医学设计实验GEO数据分析 (step-by-step))、批次效应处理等内容。
(五)Count Normalization and Principal Component Analysis
获得高质量的单细胞后,单细胞RNA-seq(scRNA-seq)分析工作流程的下一步就是执行聚类。聚类的目标是将不同的细胞类型分成独特的细胞亚群。为了进行聚类,我们确定了在细胞之间表达差异最大的基因。
数值标准化
标准化最重要的目的就是使表达水平在细胞之间和/或细胞内更具有可比性。那么在标准化中主要需要处理的因素包括:
测序深度:考虑测序深度是比较细胞之间基因表达的必要条件。在下面的示例中,每个基因在细胞2中的表达似乎都增加了一倍,但这是细胞2具有两倍测序深度的结果。
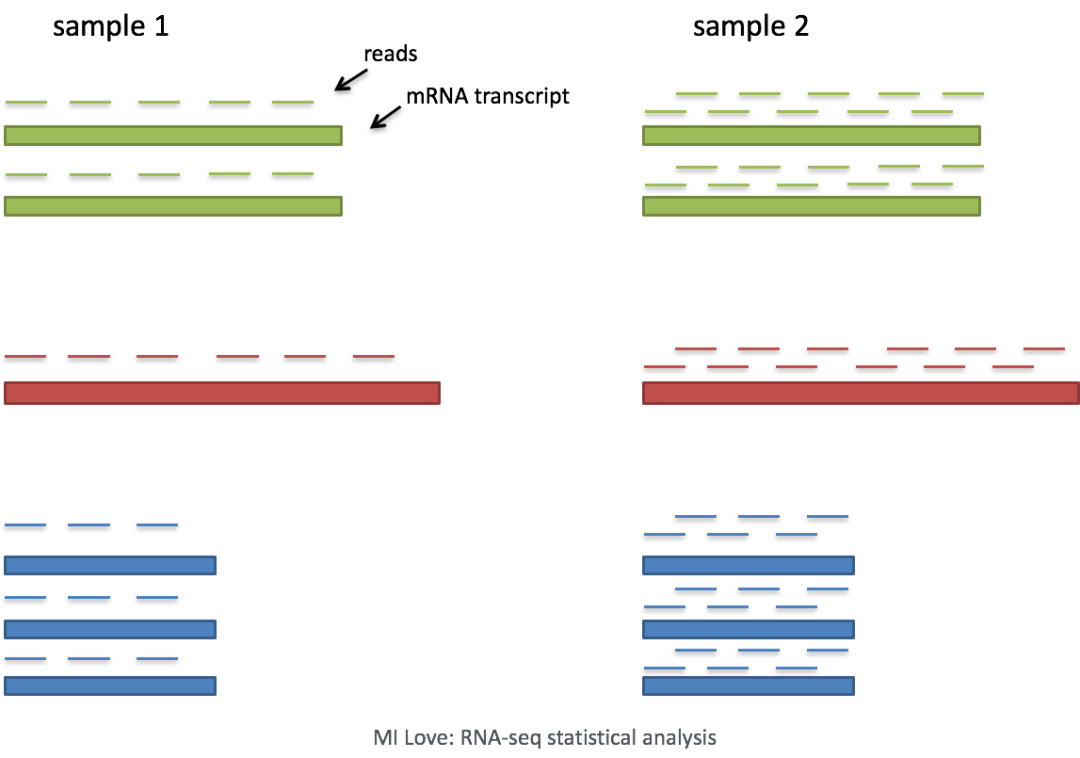
因此,要准确比较细胞之间的表达,有必要对测序深度进行标准化 (什么?你做的差异基因方法不合适?)。
基因长度:需要基因长度来比较同一细胞内不同基因之间的表达。基因长度越长比对到的reads理论上会越多。如下图所示:低表达的较长基因测序到的reads数与较高表达的短基因相差不大。

如果进行的是5’末端或3’末端测序,则不需要考虑基因长度的影响;
如果使用全长测序则需要考虑。
主成分分析(PCA)
PCA是对数据降维的技术,可以用来展示样品差异和相似性,这里推荐一个学习视频:StatQuest's video(https://www.youtube.com/watch?v=_UVHneBUBW0)
下面是PCA的示例模拟过程,帮助理解:
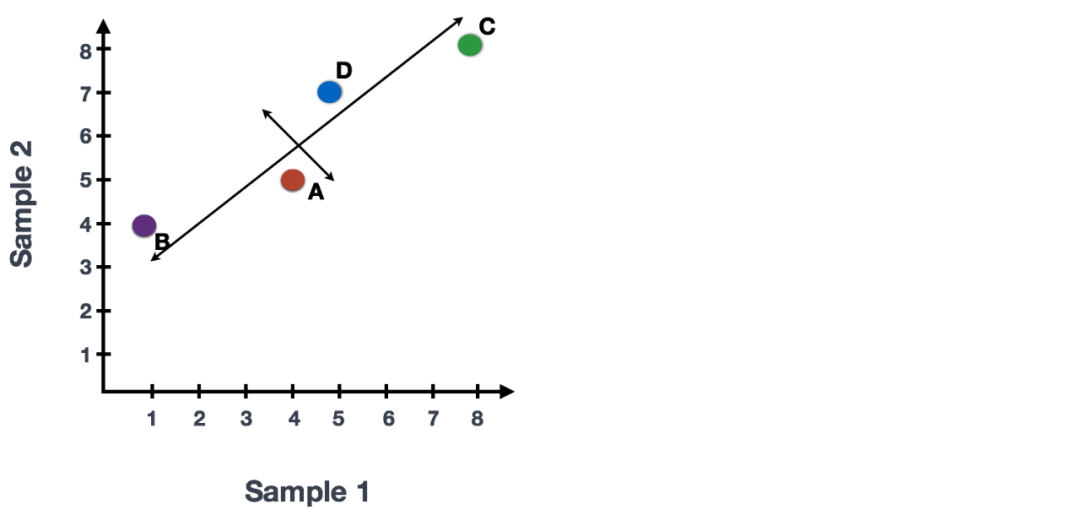
如果你已经定量了两个样本(或细胞)中四个基因的表达,则可以绘制这些基因的表达值,其中一个样本在x轴上表示,另一个样本在y轴上表示,如下所示:

我们可以沿代表最大变化的方向在数据上画一条线,在此示例中为对角线,数据中变化第一大的变量。数据集中的最大变异是在组成两个端点的基因。我们还看到基因在该线的上方和下方有些不同。我们可以在该条线的中点绘制另一条与其垂直的线,代表数据中变化第二大的变量。
末端附近的基因 (B, C)是变异最大的基因。这些基因在数学上对线的方向影响最大。
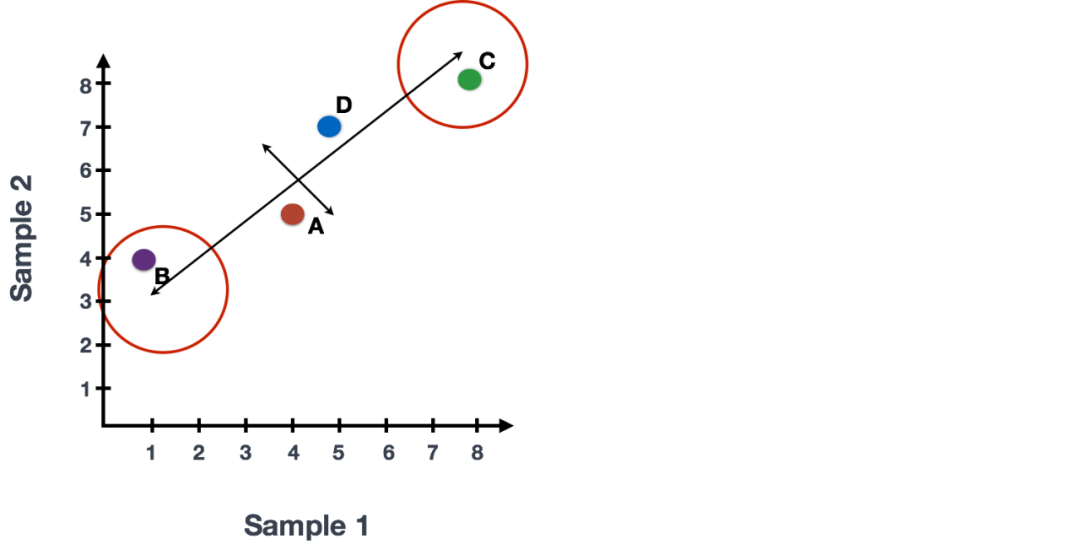
例如,基因C值的微小变化将极大地改变较长线的方向,而基因A或基因D的微小变化对其几乎没有影响。
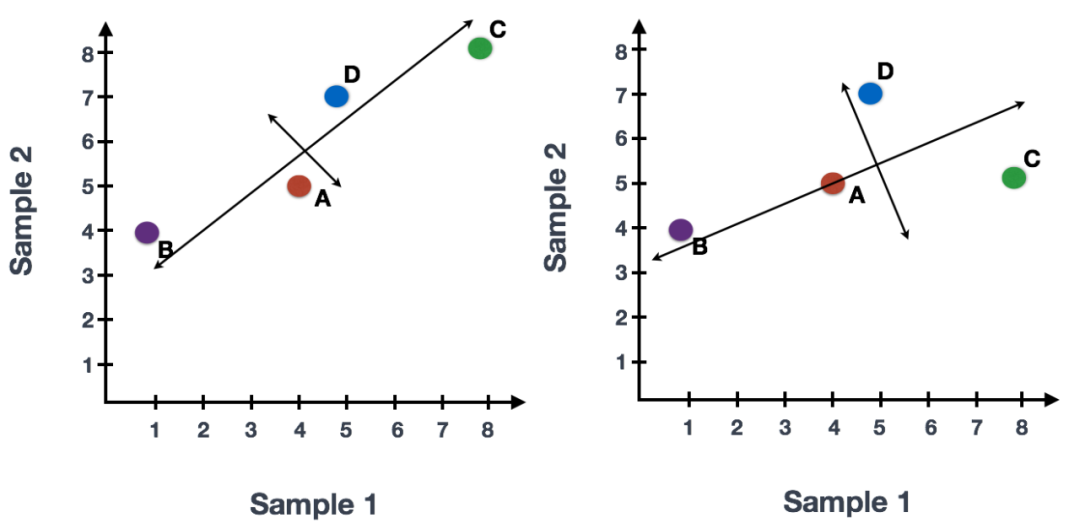
我们还可以旋转整个图,保证线条方向是从左到右和从上到下。现在,可以将这些线视为代表变化的轴。这些轴本质上是“主成分”,其中PC1代表数据的最大差异,PC2代表数据的第二大差异。
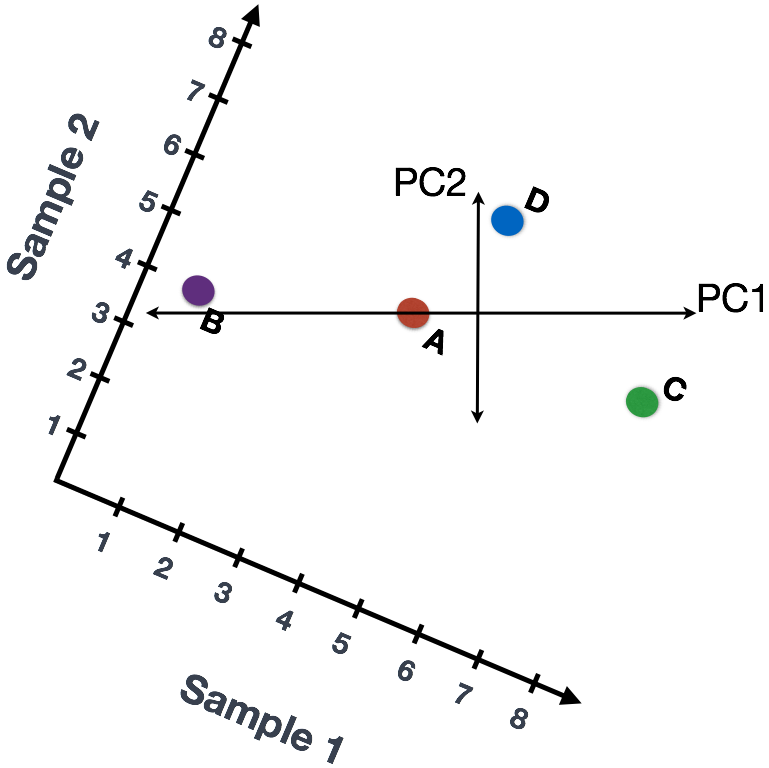
如果有N个细胞,以此类推。。。(PCA主成分分析实战和可视化 | 附R代码和测试数据)
确定PCs后,则需要对每个PC进行评分,按照以下步骤对所有样本PC对(sample-PC pairs)计算分数:
(1)首先,根据基因对每个PC的影响程度,为其分配“影响力”评分。对给定PC没有任何影响的基因得分接近零,而具有更大影响力的基因得分更高。PC线末端的基因将产生更大的影响,因此它们将获得更大的分数,但两端的符号相反。

(2)确定影响分数后,使用以下公式计算每个样本的分数:
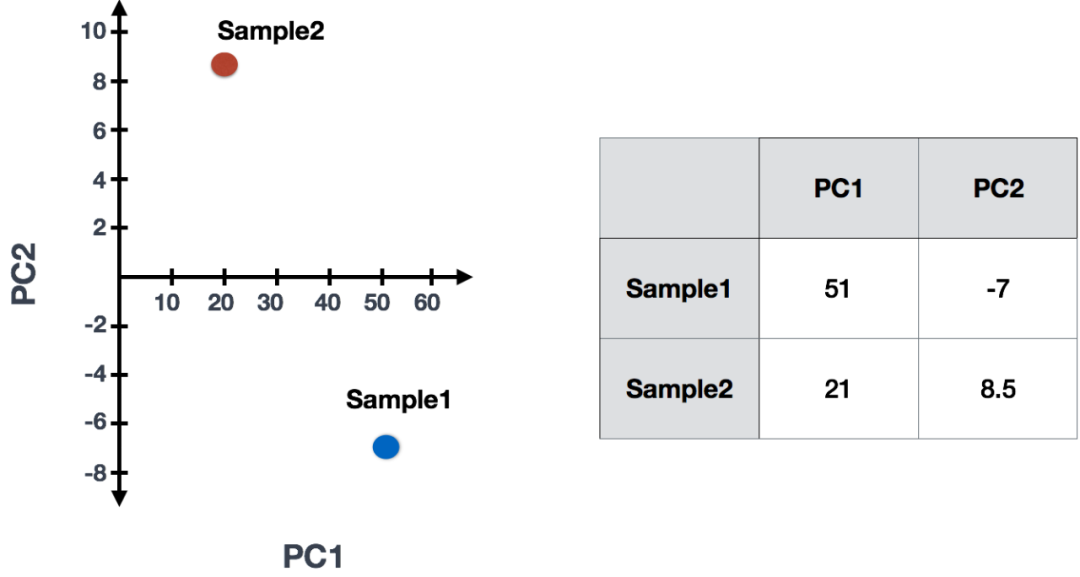
Sample1 PC1 score = (read count * influence) + ... for all genes以我们的2个样本示例,以下是分数的计算方式:
## Sample1
PC1 score = (4 * -2) + (1 * -10) + (8 * 8) + (5 * 1) = 51
PC2 score = (4 * 0.5) + (1 * 1) + (8 * -5) + (5 * 6) = -7
## Sample2
PC1 score = (5 * -2) + (4 * -10) + (8 * 8) + (7 * 1) = 21
PC2 score = (5 * 0.5) + (4 * 1) + (8 * -5) + (7 * 6) = 8.5(3)一旦为各个样本的所有PC计算了这些分数,就可以将其绘制在简单的散点图上。下面是示例图:
对于具有大量样本或细胞的数据集,通常会绘制每个样本/细胞的PC1和PC2分数。由于这些PC解释了数据集中最大的变化,因此更相似的样本/细胞将在PC1和PC2聚在一起。请参见下面的示例:
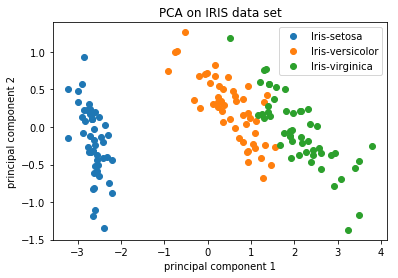
Image credit: https://github.com/AshwiniRS/Medium_Notebooks/blob/master/PCA/PCA_Iris_DataSet.ipynb
对于我们的单细胞数据,我们最终会选择10-100 PC去对细胞进行聚类分析,而不是全部基因。
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集