
用XGBoost入门可解释机器学习!
经典的全局特征重要性度量
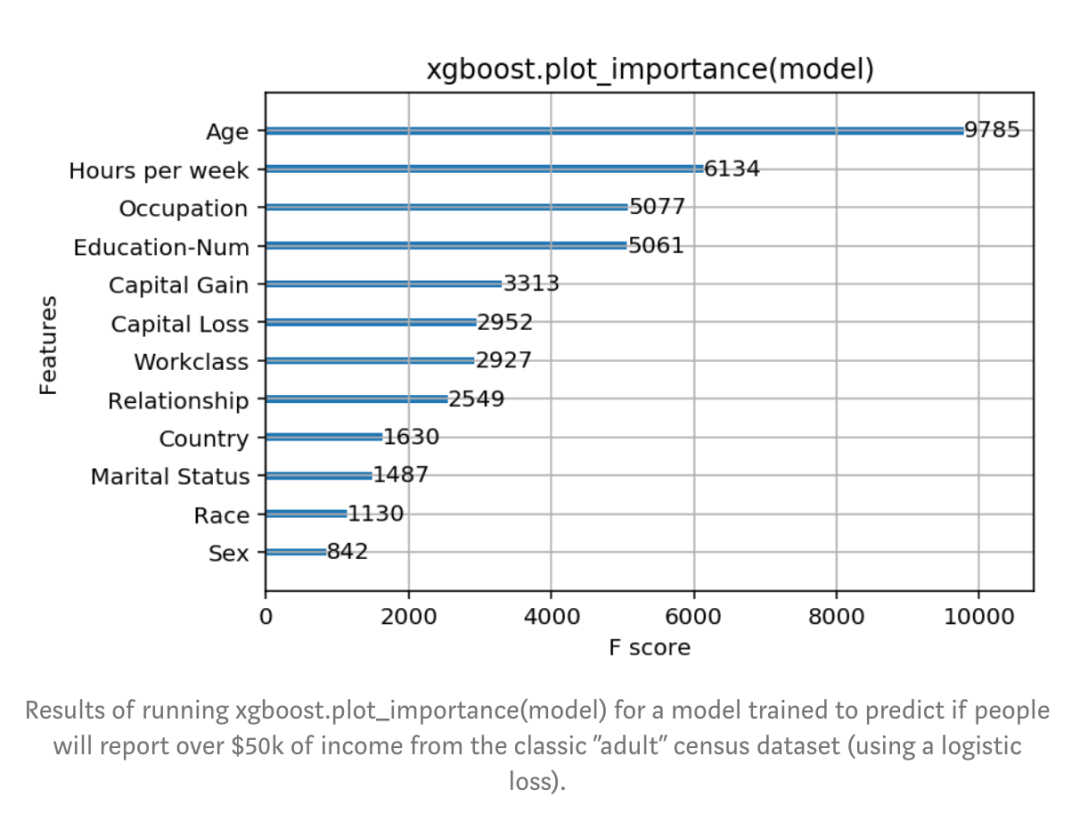
图:该模型在经典的成人普查数据集上被训练用于预测人们是否会报告超过5万美元的收入(使用logistic loss),上图是执行xgboost.plot_importance(model)的结果
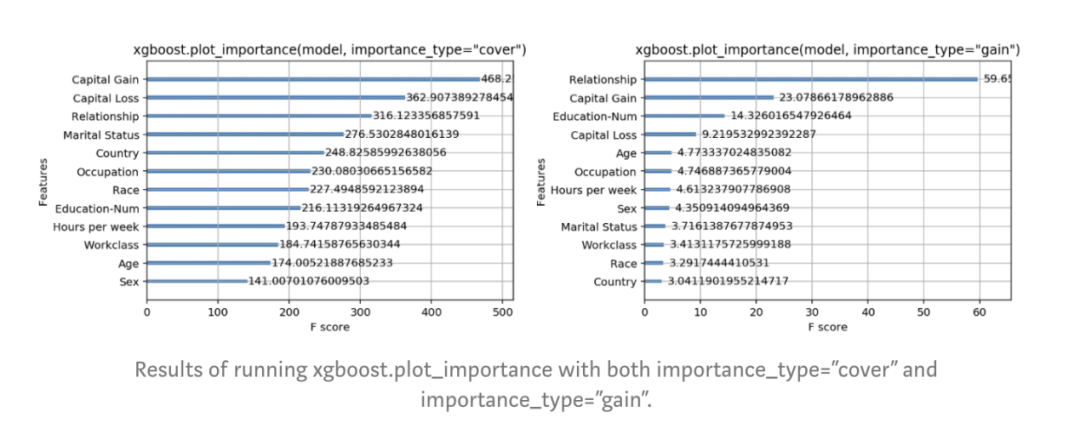
什么因素决定了特征重要性度量的好坏?
当前的归因方法是否一致且准确?
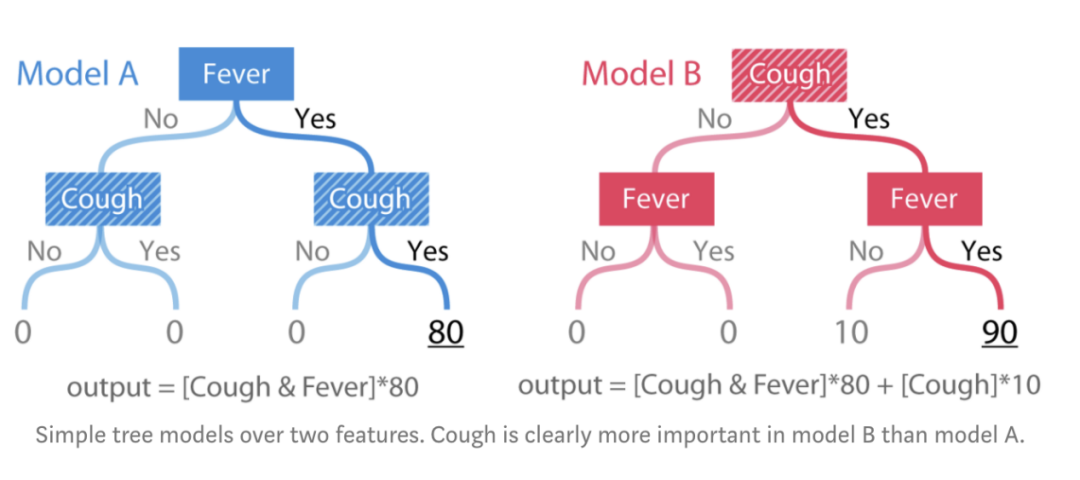
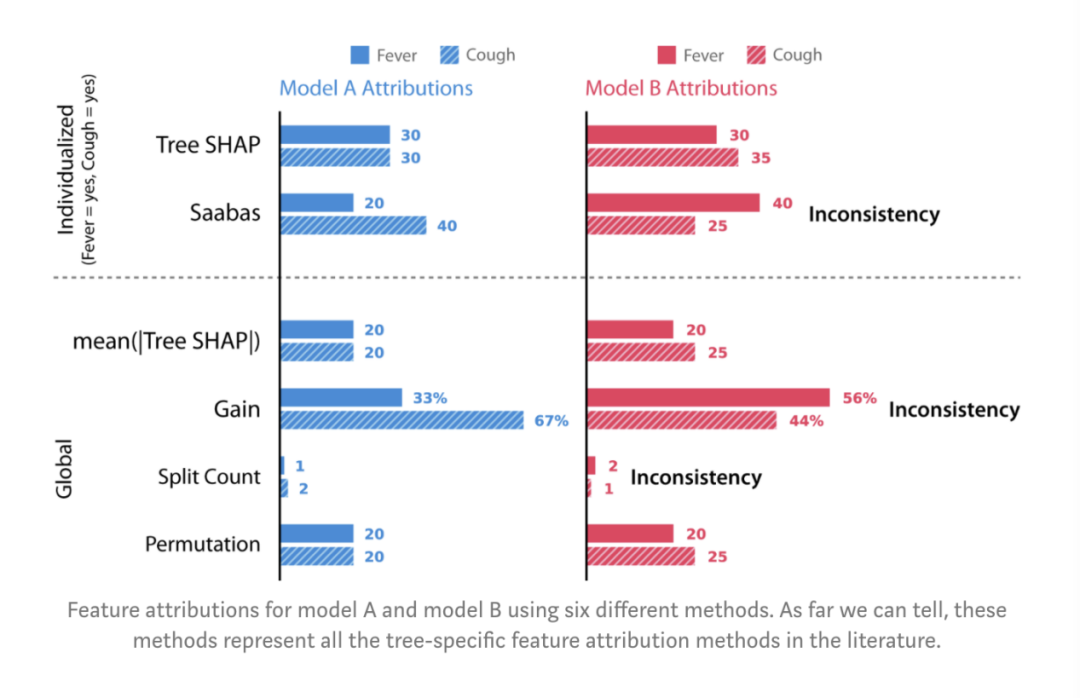
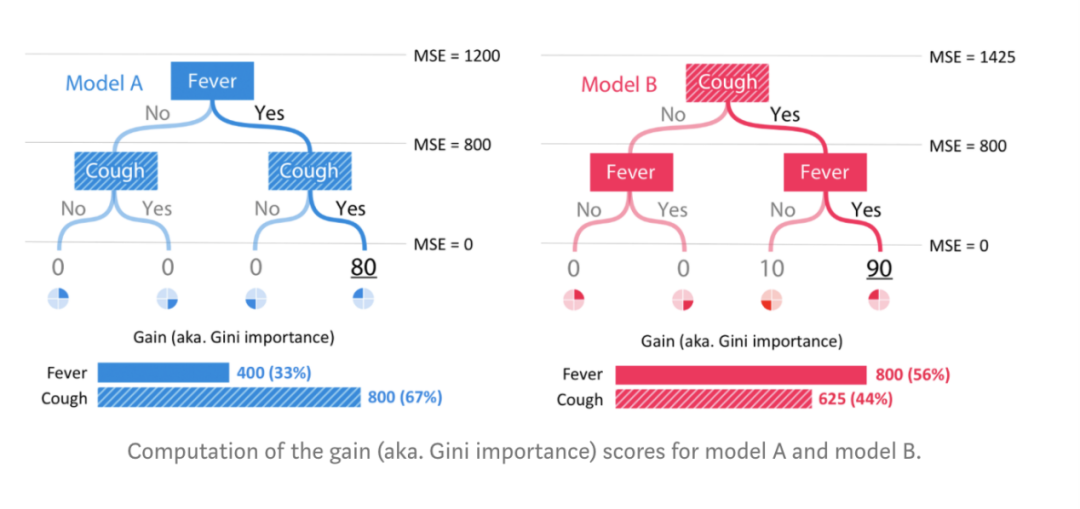
充满信心地解释我们的模型
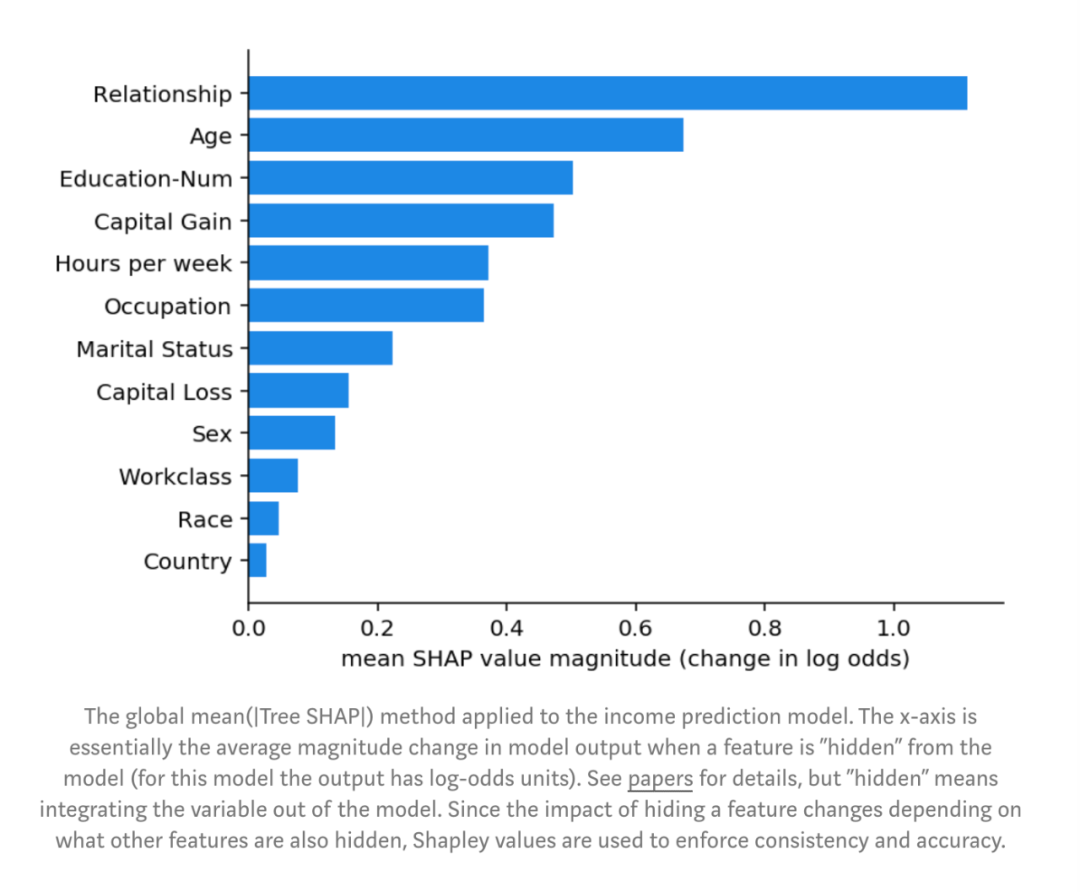 图:全局Mean( |Tree SHAP| )方法应用到收入预测模型上。x轴是当某个特征从模型中’隐藏’时模型输出的平均幅度变化(对于此模型,输出具有log-odds单位)。详细信息,请参见论文。但是“隐藏”是指将变量集成到模型之外。由于隐藏特征的影响会根据其他隐藏特征而变化,因此使用Shapley值可迫使一致性和准确性。
图:全局Mean( |Tree SHAP| )方法应用到收入预测模型上。x轴是当某个特征从模型中’隐藏’时模型输出的平均幅度变化(对于此模型,输出具有log-odds单位)。详细信息,请参见论文。但是“隐藏”是指将变量集成到模型之外。由于隐藏特征的影响会根据其他隐藏特征而变化,因此使用Shapley值可迫使一致性和准确性。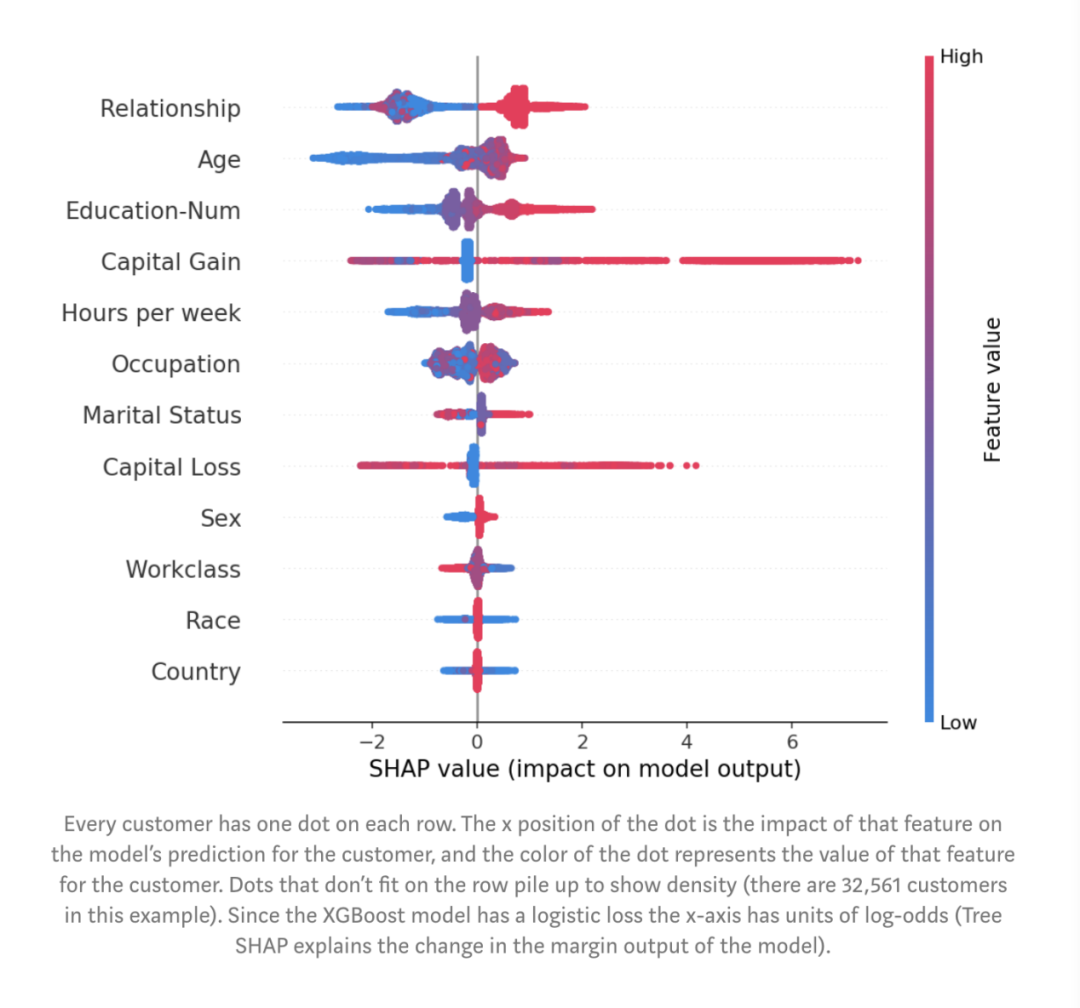
图:每个客户在每一行上都有一个点。点的x坐标是该特征对客户模型预测的影响,而点的颜色表示该特征的值。不在行上的点堆积起来显示密度(此示例中有32,561个客户)。由于XGBoost模型具有logistic loss,因此x轴具有log-odds单位(Tree SHAP解释了模型的边距输出变化)。
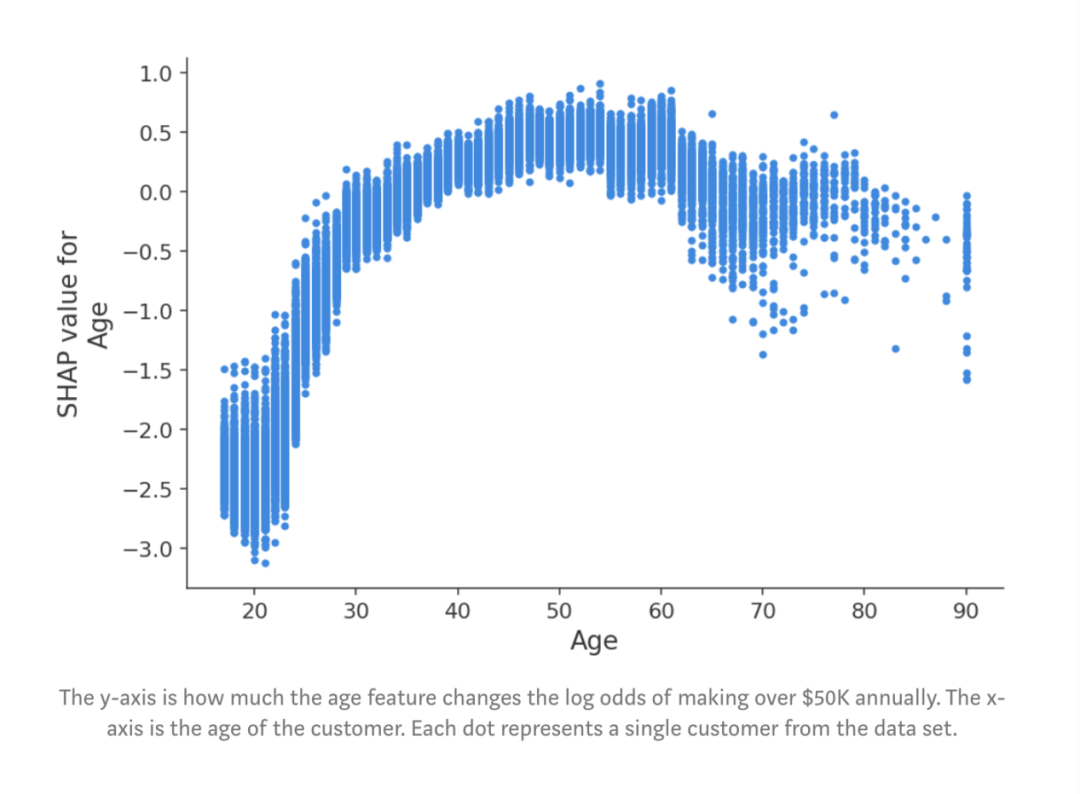
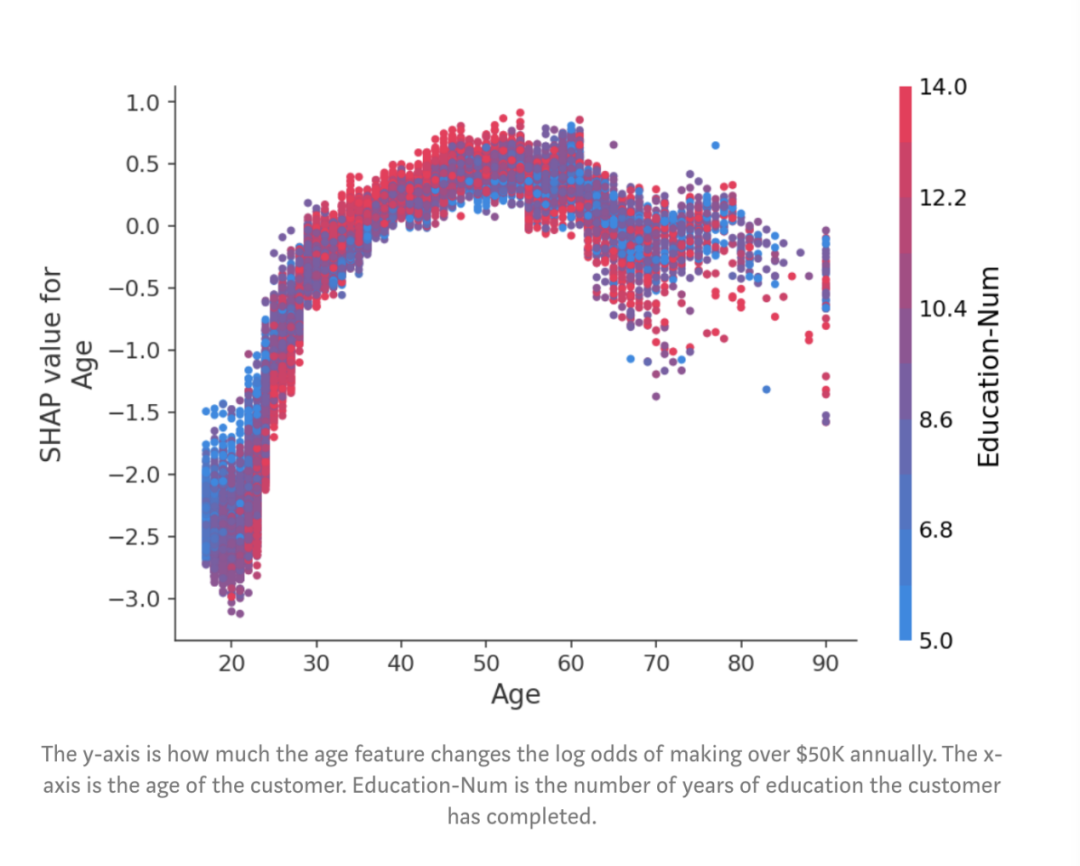
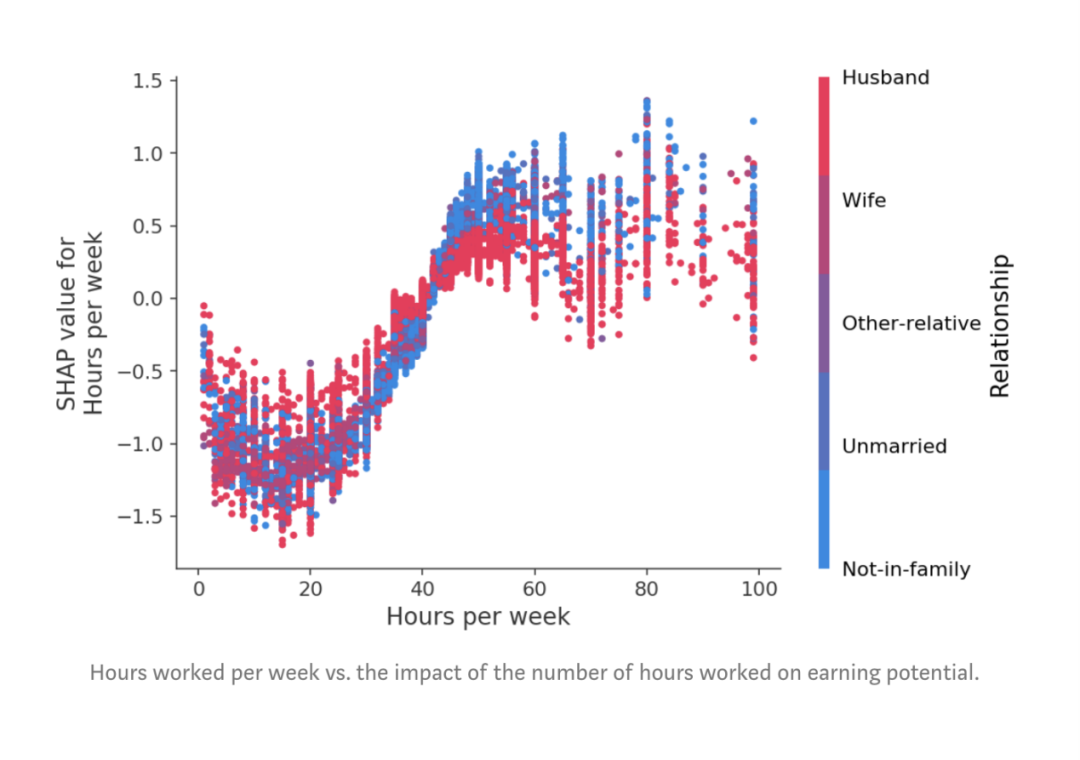 图:每周工作时间与工作时间数对收入潜力的影响。
图:每周工作时间与工作时间数对收入潜力的影响。
解释你自己的模型
评论