
Python之pandas实现更复杂的Excel操作

◆ ◆ ◆ ◆ ◆
有人问了我一个这样的问题,题目是:……。直接上图吧~
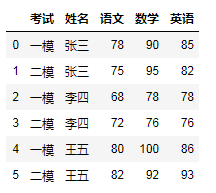
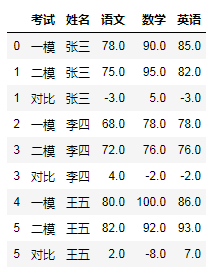
import pandas as pddata = {'考试':['一模','二模','一模','二模','一模','二模'],'姓名':['张三','张三','李四','李四','王五','王五'],'语文':[78,75,68,72,80,82],'数学':[90,95,78,76,100,92],'英语':[85,82,78,76,86,93]}df = pd.DataFrame(data)df
#方法一#
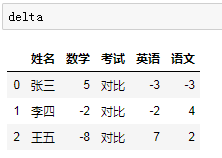
# 一定要深刻体会groupby后加的字段的不同delta = df.groupby('姓名')['考试','语文','数学','英语'].last() - df.groupby('姓名')['语文','数学','英语'].first()# 重设索引,使姓名列恢复列字段delta.reset_index(inplace = True)# 填充为对比,满足需求的每一个小细节delta.fillna('对比',inplace=True)# 输出瞧一瞧delta
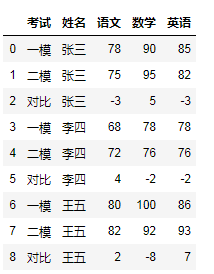
# 这种方式是可以设置ignore_index = Truedf.append(delta,ignore_index = True,sort = False).sort_values('姓名').reset_index(drop=True)
#方法二#
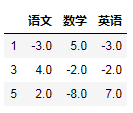
delta = df.groupby('姓名').diff().dropna()delta
3.2使用append添加结果进去
# 这种方式必须设置ignore_index = False,否则在索引排序时就会匹配不到结果df.append(delta,ignore_index = False,sort = False).sort_index().fillna({'考试':'对比'}).fillna(method = 'ffill')


送书:在看,点赞,分享朋友圈第一名即可获得。
-- END --
更
多
精
彩

评论