作者:Ivan Grishchenko & Valentin Bazarevsky
【新智元导读】谷歌MediaPipe Holistic为突破性的 540 多个关键点(33 个姿势、21 个手和468 个人脸关键点)提供了统一的拓扑结构,并在移动设备上实现了近乎实时的性能。
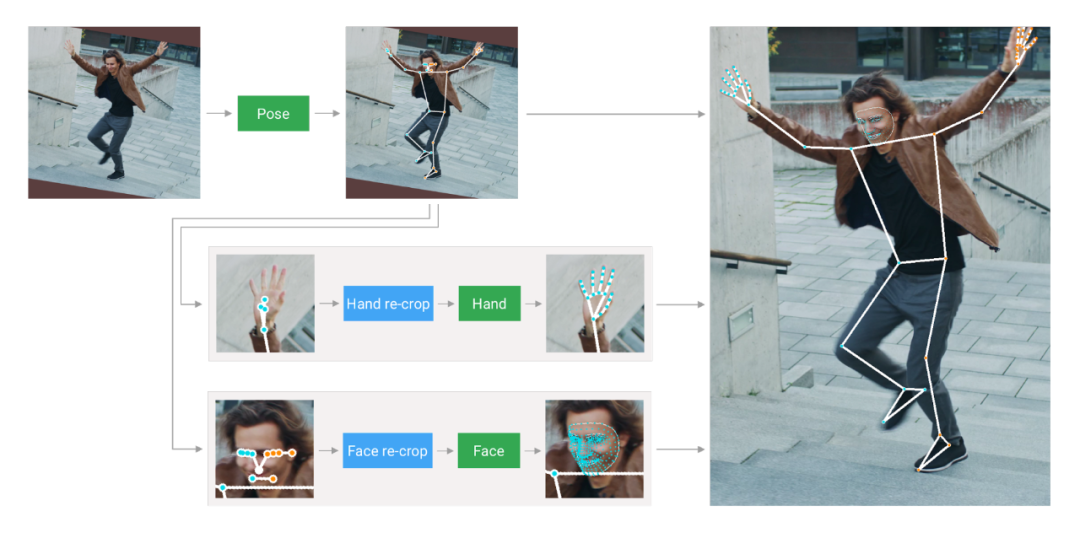
在移动设备上对人体姿势、人脸关键点和手部追踪的实时同步感知,可以实现各种有趣的应用,如健身和运动分析、手势控制和手语识别、增强现实效果等。谷歌之前发布的 MediaPipe 就是一个专门为GPU或CPU而设计的开源框架,已经为这些单个任务提供了快速、准确而又独立的解决方案。但将它们实时组合成一个语义一致的端到端解决方案,仍是一个难题,需要多个依赖性神经网络的同步推理。不久前,谷歌发布了 MediaPipe Holistic,就是针对上述挑战而提出一个解决方案,提出一个最新最先进的人体姿势拓扑结构,可以解锁新的应用。MediaPipe Holistic 由一个新的 pipelines 组成,该 pipelines 具有优化的姿态、人脸和手部组件,每个组件都实时运行,尽量降低内存传输成本,并根据质量/速度的权衡,增加了对三个组件互换性的支持。当包含所有三个组件时,MediaPipe Holistic 为突破性的 540 多个关键点(33 个姿势、21 个手部和 468个人脸关键点)提供了统一的拓扑结构,并在移动设备上实现了近乎实时的性能!MediaPipe Holistic 作为 MediaPipe 的一部分,并在移动设备(Android、iOS)和桌面设备上提供。还将引入 MediaPipe 新的即用型 API,用于研究(Python端)和网页推理(JavaScript端),以方便更多人使用。MediaPipe Holistic pipelines 集成了姿势、面部和手部组件的独立模型,每个组件都针对其特定领域进行了优化,每个组件的推断输入图不同。MediaPipe Holistic 首先通过 BlazePose 的姿势检测器和后续的关键点模型来估计人的姿势。然后,利用推断出的姿势关键点,为每只手和脸部推导出三个感兴趣区域(ROI)裁剪,并采用 re-crop 模型来改进 ROI(详情如下)。然后,pipelines 将全分辨率输入帧上裁剪这些 ROI,并应用特定任务的模型来估计它们对应的关键点。最后,将所有关键点与姿势模型的关键点合并,得出全部 540 多个关键点。MediaPipe Holistic pipeline 概览MediaPipe Holistic 使用姿势预测(在每一帧上)作为额外的 ROI 先验,来减少对快速运动做出反应时 pipeline 的响应时间。使得模型能够通过防止画面中一个人的左右手或身体部位与另一个人的左右手或身体部位之间的混淆,来保持身体及其部位的语义一致性。
此外,姿势模型的输入帧分辨率很低,由此产生的脸部和手部的 ROI 仍然不够准确,无法指导这些区域的重裁,这就需要精确的输入裁剪来保持轻量化。
为了弥补这一精度差距,作者使用轻量级的脸部和手部 re-crop 模型,这些模型扮演了 Spatial Transformers(空间变换器)的角色,并且只花费了相应模型 10% 左右的推理时间。
Performance
MediaPipe Holistic 每一帧需要协调多达 8 个模型:1 个姿势检测器、1 个姿势关键点模型、3 个 re-crop 模型和 3 个手部和面部的关键点模型。在构建过程中,作者不仅优化了机器学习模型,还优化了前处理和后处理算法(例如,仿射变换),由于 pipelines 的复杂性,这些算法在大多数设备上都需要大量的时间。这种情况下,将所有的前处理计算转移到 GPU 上,根据设备的不同,整体 pipelines 速度提升了约 1.5 倍。因此,即使在中端设备和浏览器中,MediaPipe Holistic 也能以接近实时的性能运行。使用TFLite GPU在各种中端设备上的性能,以每秒帧数(FPS)衡量由于 pipeline 的多级性,性能又多两个优点。
因模型大多是独立的,因此可以根据性能和精度要求,使用不同计算量和复杂度的模型。另外,一旦推断出姿势,人们就能精确地知道手和脸是否在帧边界内,从而使pipeline 可以跳过对这些身体部位的推断。MediaPipe Holistic,拥有 540 多个关键点,目的是为实现对身体语言、手势和面部表情的整体、同步感知。它的融合方法可以实现远程手势界面,以及全身AR、运动分析和手语识别的功能。
为了展示 MediaPipe Holistic 的质量和性能,作者构建了一个简单的远程控制界面,该界面在浏览器中本地运行,无需鼠标或键盘,就能实现令人注目的用户交互。
用户可以对屏幕上的物体进行操作,坐在沙发上用虚拟键盘打字,还可以指向或触摸特定的面部区域(例如,静音或关闭摄像头)。在依靠精准的手部检测与后续的手势识别映射到固定在用户肩部的 "触控板 "空间之下,可实现 4 米范围内的远程控制。
当其他人机交互方式不方便的时候,这种手势控制技术可以开启各种新颖的使用场景。
可在该网站演示:https://mediapipe.dev/demo/holistic_remote/
作者希望 MediaPipe Holistic 可以激发更多研究人员可以构建出新的独特应用。并期望这些 pipelines 为如手语识别、非接触式控制界面或其他复杂的用例开辟新途径。
开源地址:
https://github.com/google/mediapipe
https://ai.googleblog.com/2020/12/mediapipe-holistic-simultaneous-face.html