
使用DeepWalk从图中提取特征
共 10366字,需浏览 21分钟
·
2021-05-16 07:05
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:opencv学堂
-
从表格或图像数据中提取特征的方法已经众所周知了,但是图(数据结构的图)数据呢? -
学习如何使用DeepWalk从图中提取特征 -
我们还将用Python实现DeepWalk来查找相似的Wikipedia页面
我被谷歌搜索的工作方式迷住了。每次我搜索一个主题都会有很多小问题出现。以“人们也在搜索?”为例。当我搜索一个特定的人或一本书,从谷歌我总是得到与搜索内容类似的建议。
数据的图示
不同类型的基于图的特征
节点属性
局部结构特征
节点嵌入
DeepWalk简介
在Python中实施DeepWalk以查找相似的Wikipedia页面
当你想到“网络”时,会想到什么?通常是诸如社交网络,互联网,已连接的IoT设备,铁路网络或电信网络之类的事物。在图论中,这些网络称为图。
网络是互连节点的集合。节点表示实体,它们之间的连接是某种关系。
例如,我们可以用图的形式表示一组社交媒体帐户:
为什么我们将数据表示为图?
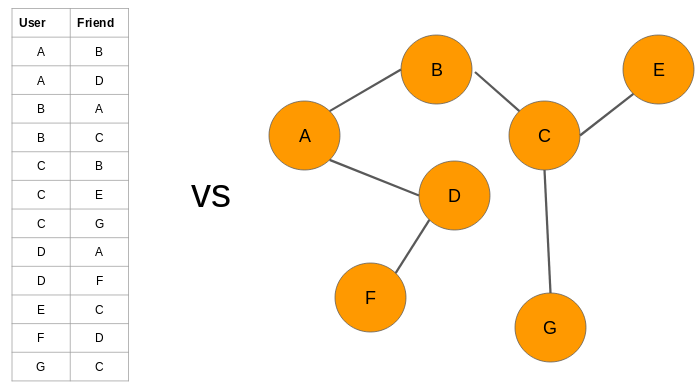
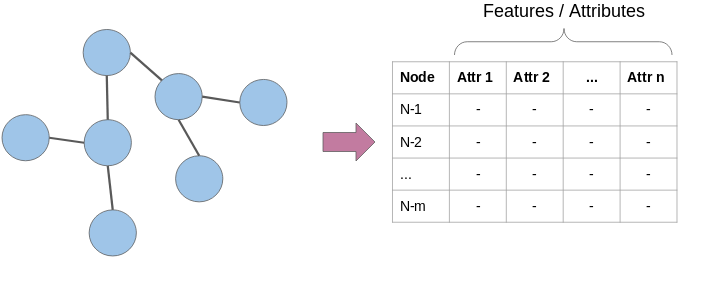
-
节点属性:我们知道图中的节点代表实体,并且这些实体具有自己的特征属性。我们可以将这些属性用作每个节点的特征。例如,在航空公司航线网络中,节点将代表机场。这些节点将具有飞机容量,航站楼数量,着陆区等特征。
2.局部结构特点:节点的度(相邻节点的数量),相邻节点的平均度,一个节点与其他节点形成的三角形数,等等。 -
节点嵌入:上面讨论的特征仅包含与节点有关的信息。它们不捕获有关节点上下文的信息。在上下文中,我指的是周围的节点。节点嵌入通过用固定长度向量表示每个节点,在一定程度上解决了这个问题。这些向量能够捕获有关周围节点的信息(上下文信息)
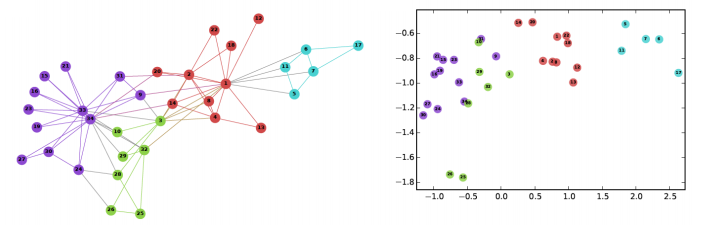
https://www.analyticsvidhya.com/blog/2019/07/how-to-build-recommendation-system-word2vec-python/?utm_source=blog&utm_medium=graph-feature-extraction-deepwalk
-
我乘巴士孟买 -
我乘火车去孟买
什么是随机游走?
随机游走是一种从图中提取序列的技术。我们可以使用这些序列来训练一个skip-gram模型来学习节点嵌入。
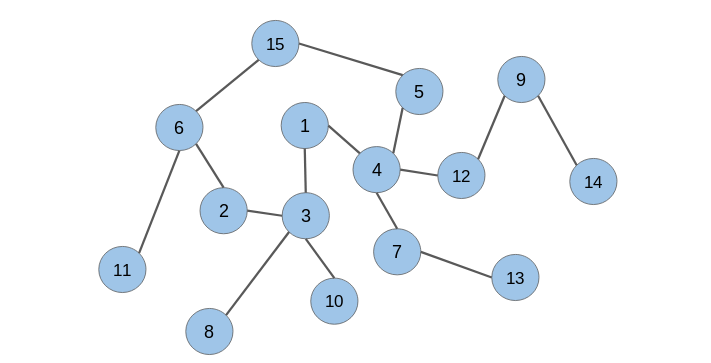
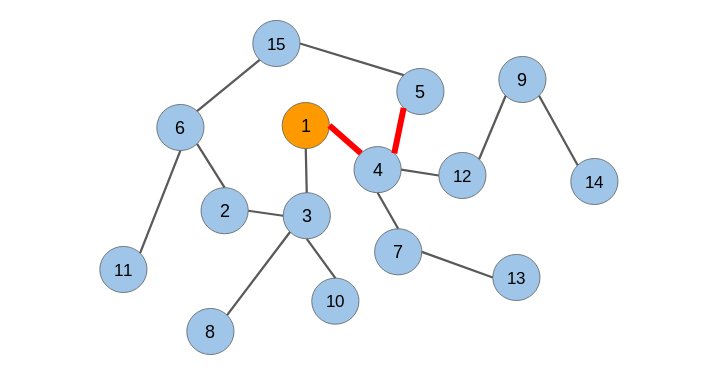
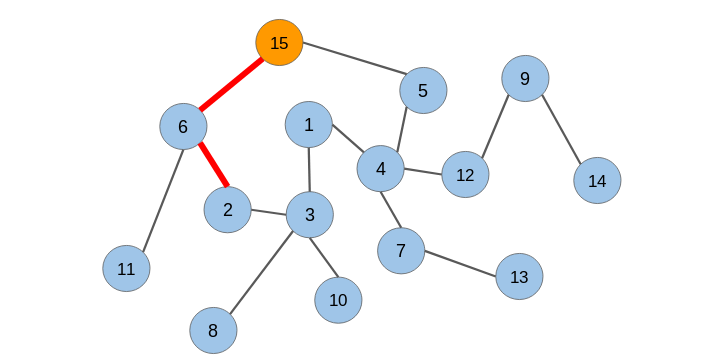
在生成节点序列之后,我们必须将它们提供给一个skip-gram模型以获得节点嵌入。整个过程被称为Deepwalk。
-
如果有数百万个节点,那么我们需要大量的计算能力来解析文本并从所有这些节点或页面中学习词嵌入 -
这种方法不会捕获这些页面之间连接的信息。例如,一对直接连接的页面可能比一对间接连接的页面具有更强的关系
导入所需的Python库
import networkx as nximport pandas as pdimport numpy as npimport randomfrom tqdm import tqdmfrom sklearn.decomposition import PCAimport matplotlib.pyplot as plt%matplotlib inline
加载数据集
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/11/space_data.zip
df = pd.read_csv("space_data.tsv", sep = "\t")df.head()
Output:

构造图
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())让我们检查图中的节点数:
len(G)Output: 2088
我们将处理2,088个Wikipedia页面。
随机游走
def get_randomwalk(node, path_length):random_walk = [node]for i in range(path_length-1):temp = list(G.neighbors(node))temp = list(set(temp) - set(random_walk))if len(temp) == 0:breakrandom_node = random.choice(temp)random_walk.append(random_node)node = random_nodereturn random_walk
让我们来试试节点“space exploration”这个函数:
get_randomwalk('space exploration', 10)输出:

# 从图获取所有节点的列表all_nodes = list(G.nodes())random_walks = []for n in tqdm(all_nodes):for i in range(5):random_walks.append(get_randomwalk(n,10))# 序列个数len(random_walks)
# importing required librariesimport pandas as pdimport networkx as nximport numpy as npimport randomfrom tqdm import tqdmfrom sklearn.decomposition import PCAimport pprintfrom gensim.models import Word2Vecimport warningswarnings.filterwarnings('ignore')# read the datasetdf = pd.read_csv("space_data.tsv", sep = "\t")print(df.head())G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())print('The number of nodes in pur graph: ',len(G))def get_randomwalk(node, path_length):random_walk = [node]for i in range(path_length-1):temp = list(G.neighbors(node))temp = list(set(temp) - set(random_walk))if len(temp) == 0:breakrandom_node = random.choice(temp)random_walk.append(random_node)node = random_nodereturn random_walkprint('\n\nRandom sequence of nodes generated from Random Walk\n\n')while True:first_node = input("Enter name of first node (for example 'space exploration') : ")if len(first_node) > 0:breakpprint.pprint(get_randomwalk(first_node, 10))# 从图中获取所有节点的列表all_nodes = list(G.nodes())random_walks = []for n in tqdm(all_nodes):for i in range(5):random_walks.append(get_randomwalk(n,10))# 序列长度len(random_walks)# 训练skip-gram (word2vec)模型model = Word2Vec(window = 4, sg = 1, hs = 0,negative = 10, # 负采样alpha=0.03, min_alpha=0.0007,seed = 14)model.build_vocab(random_walks, progress_per=2)model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)print('\n\n Get similar nodes\n\n')while True:any_node = input("Enter name of any node (for example 'space toursim') : ")if len(any_node) > 0:breakpprint.pprint(model.similar_by_word(any_node))
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~