
Hadoop创始人聊数字化变革:性能和成本不再是唯二的考虑因素
大数据文摘
共 4551字,需浏览 10分钟
·
2020-09-13 10:56

Doug Cutting:不能从管理层着手,要从更低层次细节,“小步迭代”推动
Doug Cutting:不能从管理层着手,要从更低层次细节,“小步迭代”推动

腾讯云重磅发布大数据平台算力!日实时计算量超40万亿
腾讯云重磅发布大数据平台算力!日实时计算量超40万亿

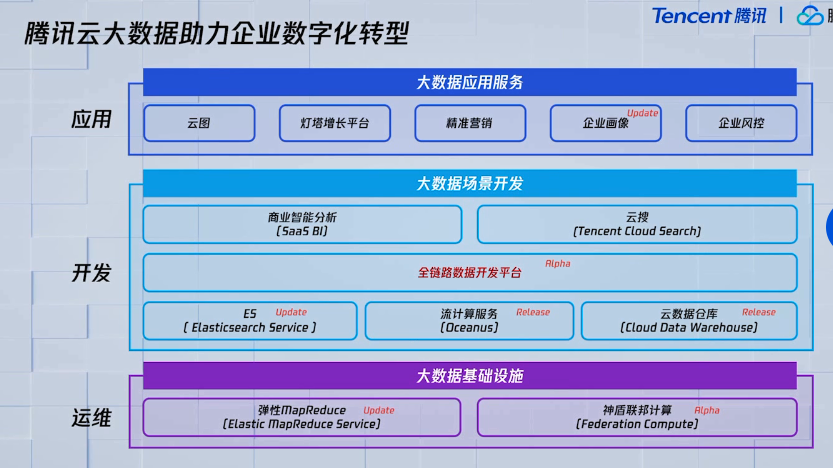
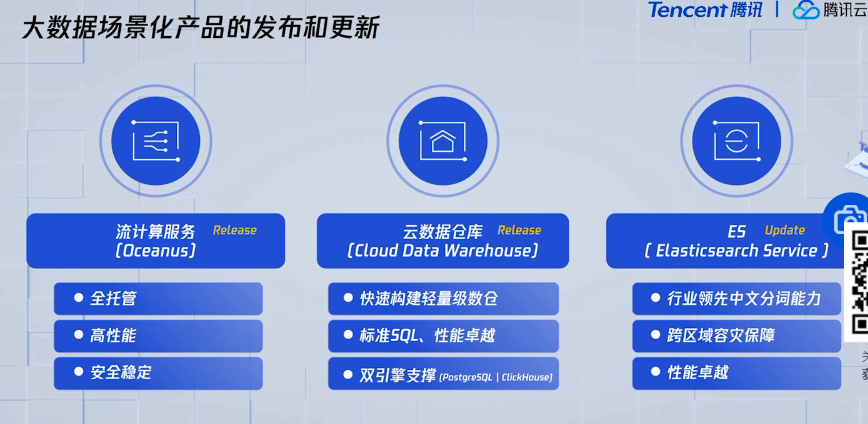
重磅发布全链路大数据平台WeData
重磅发布全链路大数据平台WeData

专访腾讯云大数据负责人:安全与融合是未来发展重点
专访腾讯云大数据负责人:安全与融合是未来发展重点
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
评论