我们在学习Flink的时候,到底在学习什么?
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

这是一篇指南和大纲性质的文章。 Flink经过2年左右的官方和社区的大规模推广,现在国内的一众大小企业基本都在使用。
核心背景和论文
基础概念
流(无界流、有界流)和转换
State和checkpoint
并行度
Workers,Slots,Resources
时间和窗口
...
核心模块
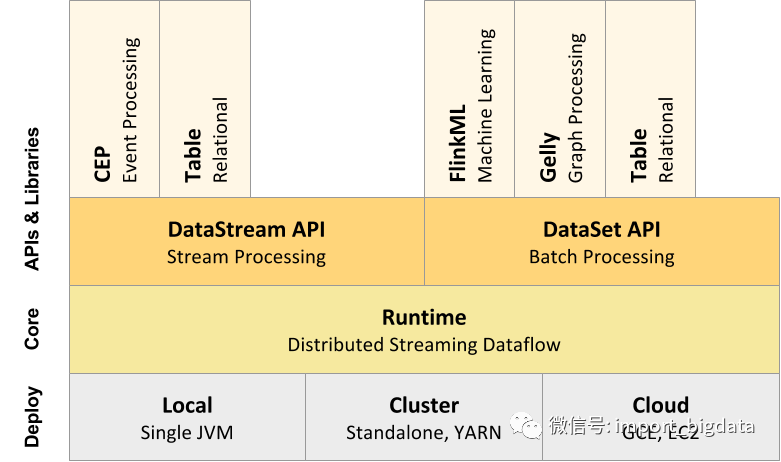
源码阅读
Flink 基本组件和逻辑计划:介绍了 Flink 的基本组件、集群构建的过程、以及客户端逻辑计划的生成过程
Flink 物理计划生成:介绍了 Flink JobManager 对逻辑计划的运行时抽象,运行时物理计划的生成和管理等
Jobmanager 基本组件和TaskManager的基本组件
Flink 算子的生命周期:介绍了 Flink 的算子从构建、生成、运行、及销毁的过程
Flink 网络栈:介绍了 Flink 网络层的抽象,包括中间结果抽象、输入输出管理、BackPressure 技术、Netty 连接等
Flink的水印和Checkpoint
Flink-scheduler:介绍 Flink 的任务调度算法及负载均衡
Flink对用户代码异常处理:介绍作业的代码异常后 Flink 的处理逻辑,从而更好的理解 Flink 是如何保证了 exactly-once 的计算语义
Flink Table/SQL 执行流程、Flink和Hive的集成等
行业应用
实时数据计算
各大电商每年双十一都会直播,实时监控大屏是如何做到的? 公司想看一下大促中销量最好的商品 TOP5? 我是公司的运维,希望能实时接收到服务器的负载情况?
实时数据仓库和 ETL
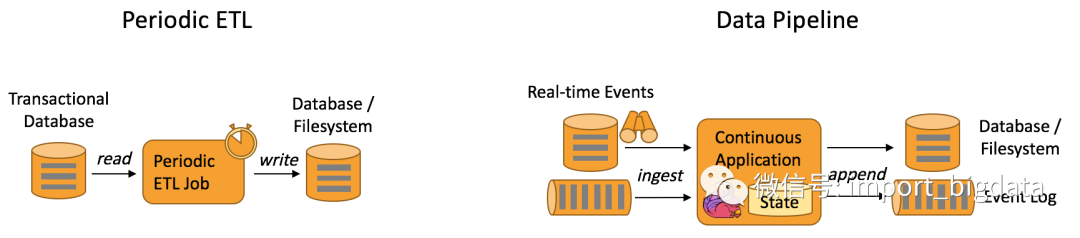
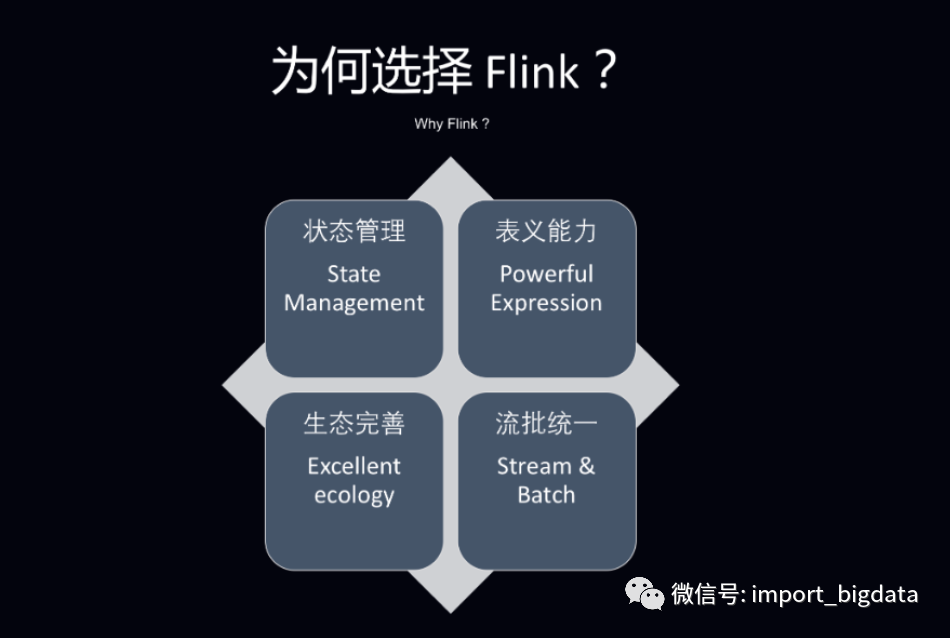
状态管理,实时数仓里面会进行很多的聚合计算,这些都需要对于状态进行访问和管理,Flink 支持强大的状态管理
丰富的 API,Flink 提供极为丰富的多层次 API,包括 Stream API、Table API 及 Flink SQL
生态完善,实时数仓的用途广泛,Flink 支持多种存储(HDFS、ES 等)
批流一体,Flink 已经在将流计算和批计算的 API 进行统一。
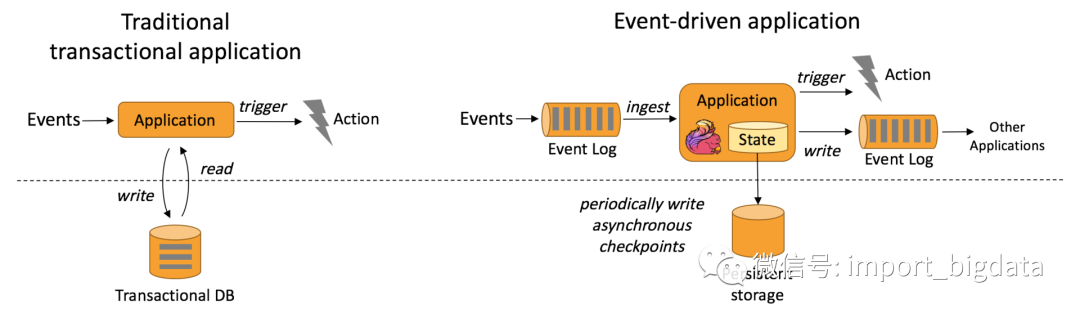
事件驱动型应用
我们公司有几万台服务器,希望能从服务器上报的消息中将 CPU、MEM、LOAD 信息分离出来做分析,然后触发自定义的规则进行报警?我是公司的安全运维人员,希望能从每天的访问日志中识别爬虫程序,并且进行 IP 限制?
高效的状态管理,Flink 自带的 State Backend 可以很好的存储中间状态信息
丰富的窗口支持,Flink 支持包含滚动窗口、滑动窗口及其他窗口
多种时间语义,Flink 支持 Event Time、Processing Time 和 Ingestion Time
不同级别的容错,Flink 支持 At Least Once 或 Exactly Once 容错级别
Flink和IceBerg等框架结合打造未来的数据湖
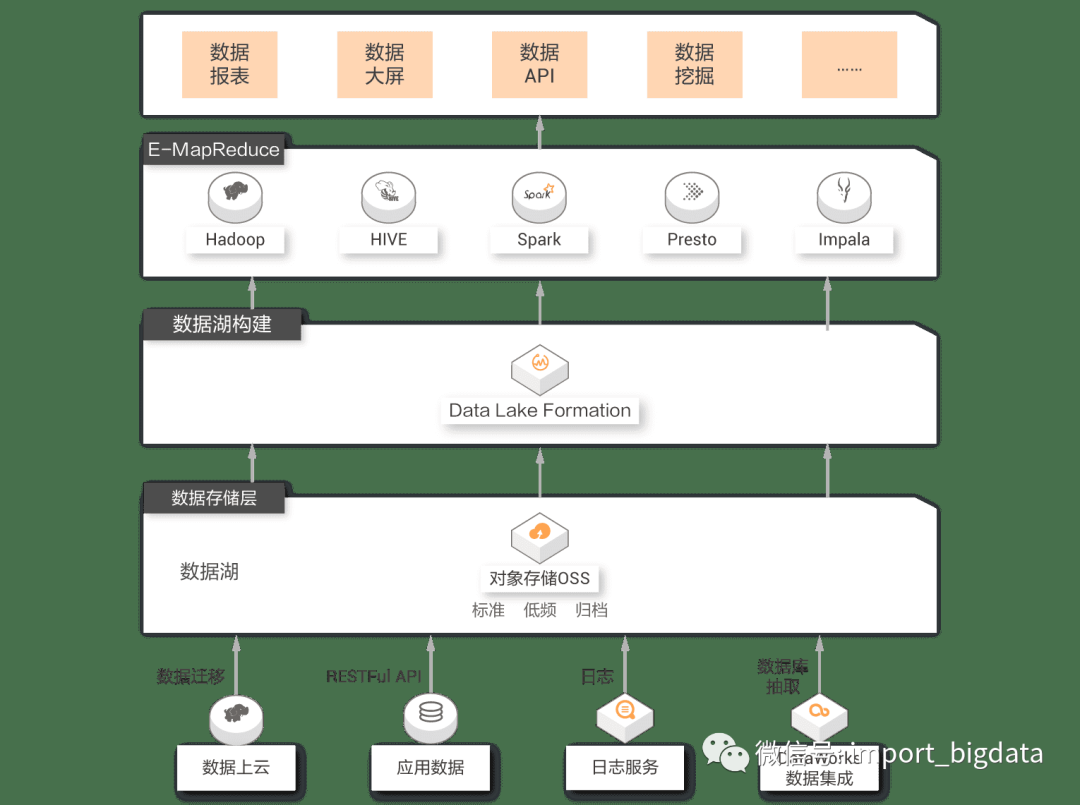
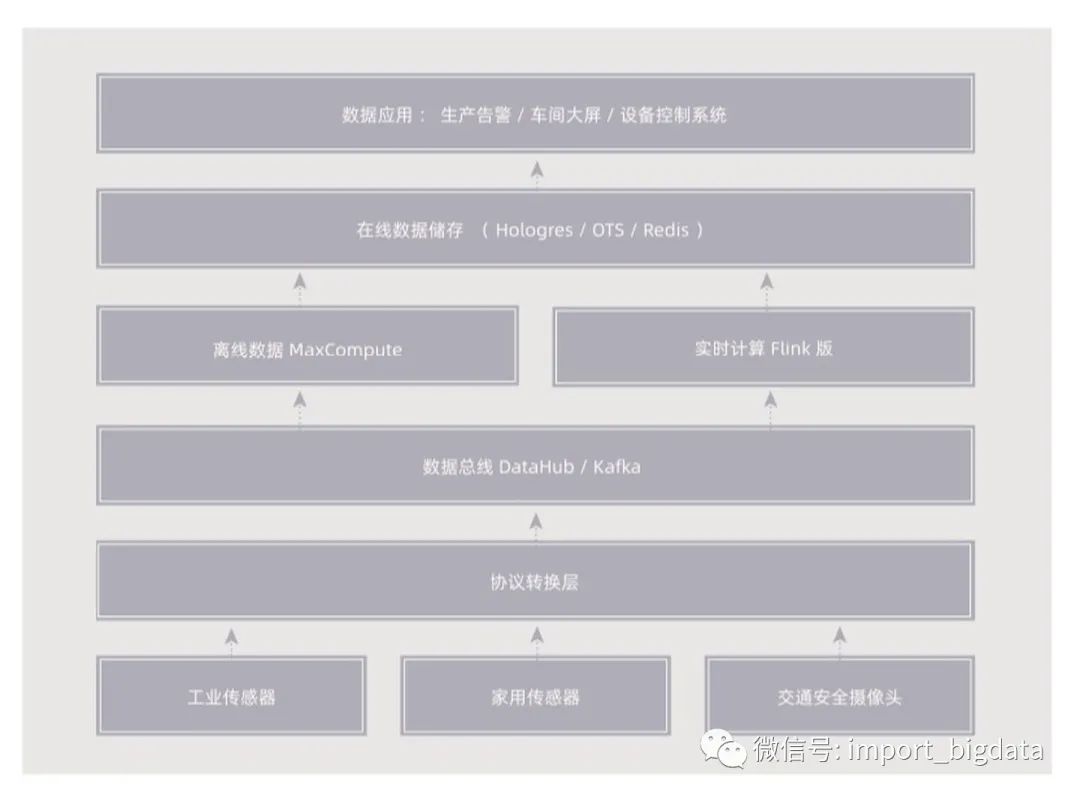
基于Flink的IOT解决方案