
基于深度学习的特征提取和匹配
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|计算机视觉工坊
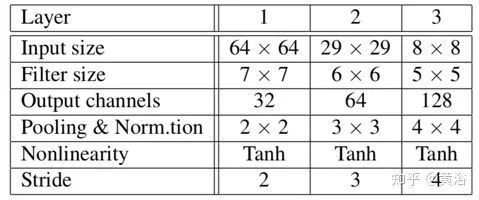
特征提取

-
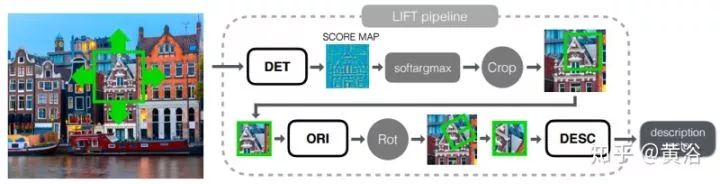
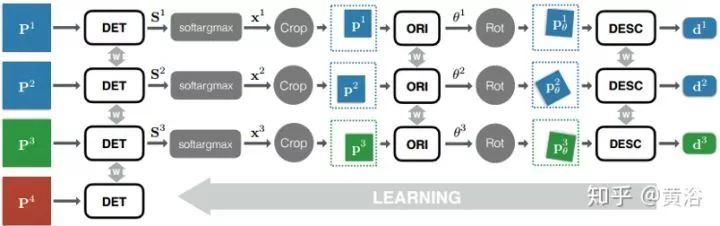
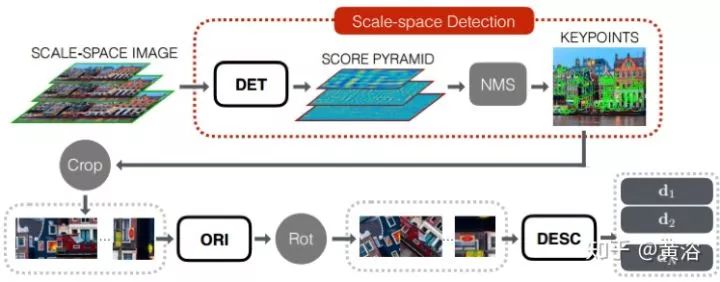
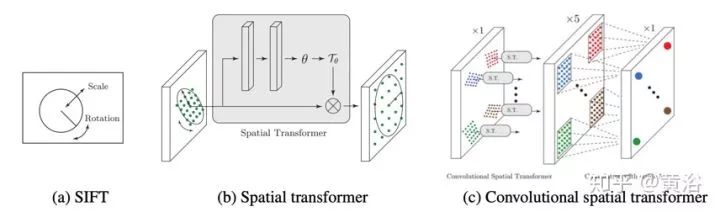
1) 给定输入图像块P,检测器提供得分图S; -
2) 在得分图S上执行soft argmax 并返回单个潜在特征点位置x。 -
3) 用空间变换器层裁剪(Spatial Transformer layer Crop)提取一个以x为中心的较小的补丁p(如图5-3), 作为朝向估计器的输入。 -
4) 朝向估计器预测补丁方向θ。 -
5) 根据该方向第二个空间变换器层(图中的Rot)旋转p产生pθ。 -
6) pθ送到描述子网络计算特征向量d。

特征匹配
-
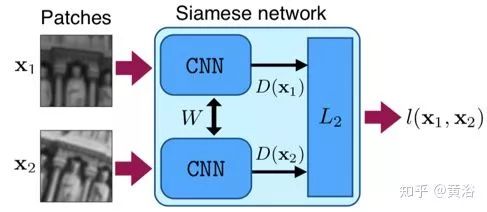
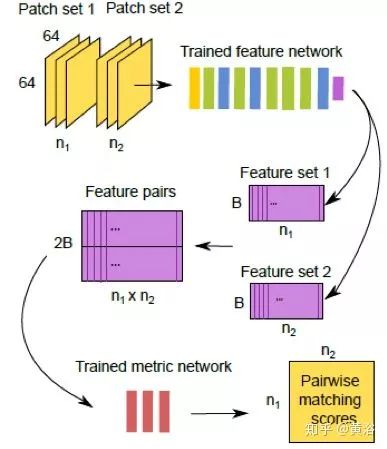
MatchNet【3】

-
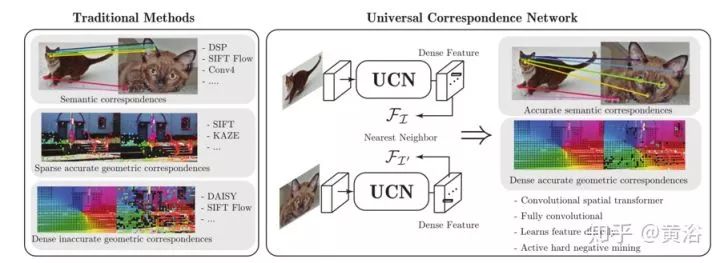
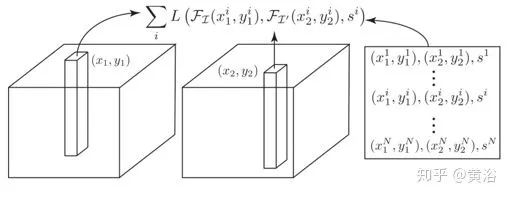
UCN【4】

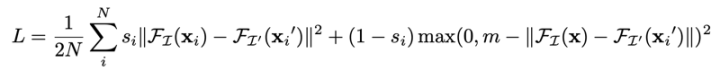
-
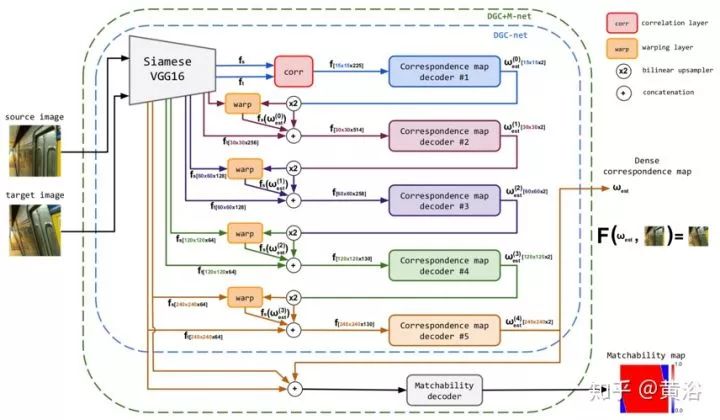
DGC-Net【5】
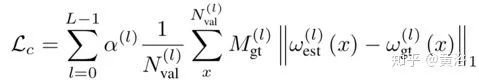

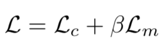

参考文献
-
1. E. Simo-Serra et al., “Discriminative learning of deep convolutional feature point descriptors”. ICCV 2015 -
2. K Yi et al.,“Learned Invariant Feature Transform”, arXiv 1603.09114, 2016 -
3. X Xu et al.,“MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching”, CVPR 2015 -
4. C Choyet al., “Universal Correspondence Network”,NIPS 2016 -
5. I Melekhov et al, “DGC-Net: Dense Geometric Correspondence Network”, CVPR 2019
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论