本文介绍了haberman乳腺癌生存二分类数据集,进行神经网络模型拟合。包含数据准备、MLP模型学习机制、模型稳健性评估。
一种方法是先对数据集进行探查,然后思考什么模型适用于这个数据集,先尝试一些简单的模型,最后再开发并调优一个稳健的模型。这个流程适用于为分类、回归预测模型问题开发高效的神经网络。本教程中,你将学习如何开发一个多层感知机神经网络模型,用于癌症生存二分类数据集。
Haberman 乳腺癌生存数据集
神经网络学习机制
模型鲁棒性评估
最终的模型及预测
我们使用的是“haberman”标准二分类数据集。数据集描述的是乳腺癌患者的数据,结局事件是患者生存,具体是指病人是否生存了五年活以上,或患者是否存活。这是学习不平衡数据分类问题的标准的数据集。数据集的背景描述表明,研究是在1958年到1970年期间,在芝加哥大学的Billings医院开展的。我们只有以上数据,无法选择组成数据集合的病例,以及病例的特征。尽管这个数据集描述的是乳腺癌患者的生存情况,但考虑到数据集的样本量少,以及这些数据是基于发生在几十年前的乳腺癌病例,因此基于这个数据集的模型并不具备泛化能力。备注:声明,我们不是要治愈乳腺癌,而是在探索一种标准的分类数据集。
从以下链接,可以对这个数据集有更多了解:
Haberman Survival Dataset (haberman.csv)(https://github.com/jbrownlee/Datasets/blob/master/haberman.csv)
Haberman Survival Dataset Details (haberman.names)(https://github.com/jbrownlee/Datasets/blob/master/haberman.names)
可以直接从URL中加载数据集,保存为pandas DataFrame,如下:
执行这个例子,可以直接从这个URL加载数据,获得数据集的维度。本例中,我们可以确定,数据集有4个变量(3个输入1个输出变量),有306行数据。对于一个神经网络来说,这个数据量不算大,因此一个小的、并适当加入正则项的网络,可能更合适。另外,相对于直接拆分为训练集和测试集,k折交叉验证有助于生成一个更值得信赖的模型结果,因为单一的模型只需要几秒钟就可以拟合得到。
执行这个例子,首先加载了数据,接着打印了对每个变量的统计信息。我们可以看到每个变量的均值和不同,或许在建模之前,需要先进行标准化。
我们发现,第一个变量符合高斯分布,另外两个输入变量可能是指数分布。在每个变量上使用幂变换可以减少概率分布的偏差,从而提高模型的性能。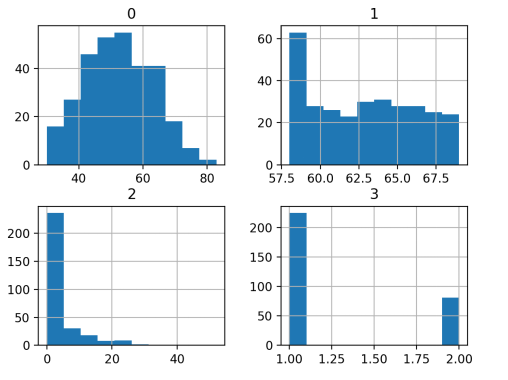
我们可以看到两个类之间的示例分布有一些偏差,这意味着分类是不平衡的。这是不平衡数据。可以用Counter对象统计每个分类下的样本量,用这个统计结果总结分布的特征。
类别1包含225个样本,约为数据集的74%,是最多的分类。类别2是未存活的样本,只有81个,占26%。
当我们评估分类准确性的时候,考虑以上信息是有帮助的,因为任何准确度在73.5%以下的模型在这个数据集上都是没有价值的。现在我们已经熟悉了这个数据集,接下来,一起开发神经网络模型吧。我们将用TensorFlow根据这个数据集拟合多层感知机模型。我们无法知道,在这个数据集上表现最好的超参数是多少,所以我们需要经过实验寻找适合的超参数。考虑到这是个小数据集,用小批尺寸进行批量训练可能是个好主意,例如16或32行。开始时使用Adam版本的随机梯度下降,因为它将自动调整学习速率,并在大多数数据集上运行良好。在我们认真评估模型之前,先回顾下学习机制并调整模型架构和学习配置,直到我们有了稳定的学习机制,然后看看如何最大限度地利用模型。可以通过简单地将数据划分为测试集和训练集,并查看学习曲线来实现以上目标。这个可以帮助我们了解模型过拟合还是欠拟合,接下来,我们可以根据结果调整配置。首先需要确保,输入变量都是浮点值,目标变量是0/1的整型值。接着,我们把数据集划分为输入变量和输出变量,划分成比例为67/33的训练集和测试集。还需要保证,训练集和测试集上不同类别数据的分布和整个数据集是一致的。
本例中,我们可以定义一个小的MLP模型,包含一个10节点的隐藏层,一个输出层(这个是任意选择的)。隐藏层的激活函数用ReLu函数,和he_normal 权重初始化函数 ,通常这些设定在实践中表现优秀。ReLu函数
https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
权重初始化函数
https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
模型的输出是sigmoid激活后的二分类结果,我们将最小化二分类交叉熵损失函数。二分类交叉熵损失函数
https://machinelearningmastery.com/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/
我们将拟合这个模型,由于是小样本数据,使用200个训练epoch(任意选择的),每个批量是16个样本。我们认为在原始数据上拟合模型可能是个好主意,但这是个重要的起点。
训练结束,我们将在测试集上评估模型表现,报告分类准确度。
最后,我们将绘制训练过程中的反映交叉熵损失的学习曲线。
把以上操作整合,得到了在癌症生存数据集上的第一个MLP模型的完整代码示例。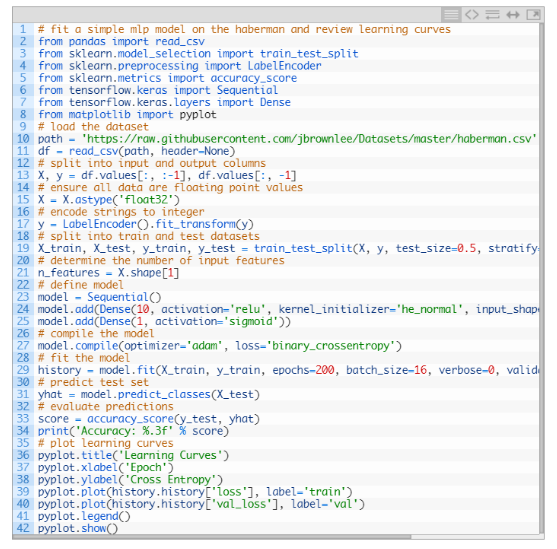
运行该示例首先在训练数据集上拟合模型,然后在测试数据集上报告分类准确度。跟随我的新书 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),开启你的项目,其中包括所有示例的分步教程和Python源代码文件。本例中,我们可以看到模型准确度超过73.5%,比上文提到的全预测为一类的准确度高。
在训练集和测试集上的损失值的曲线图如下。我们可以看到模型拟合的很好,没有出现欠拟合和过拟合。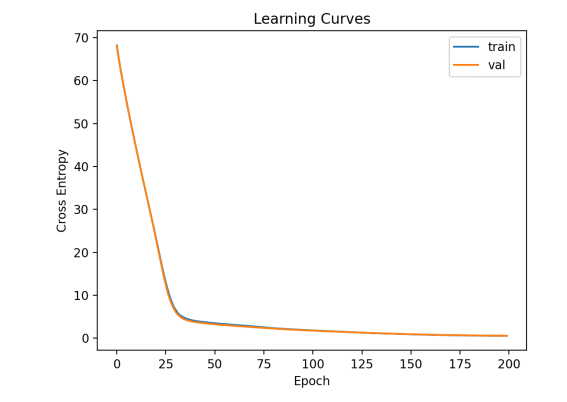
我们已经对这个数据集上简单的MLP模型有了一些概念,我们可以寻求更稳健的模型评估。K折交叉验证的过程可以对模型效果提供更可靠的评估,虽然执行会慢一点。这是因为k模型必须进行拟合和评估。当数据集很小时,这不是问题,例如癌症生存数据集。我们可以用StratifiedKFold这个类,手动循环每个折子,拟合模型,得到模型评估结果,然后整个流程结束后,得到模型评估的平均值。https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html
我们可以应用这个框架得到一个可信赖的MLP模型的结果,对于不同的数据准备、模型架构、学习配置,这个框架都适用。关键的是,在使用k-折交叉验证前,我们先对模型在这个数据集上的学习机制有了了解。如果我们直接对模型调优 ,可能我们会一下子就得到好的结果,但如果没有的话,我们可能不知道为什么,比如说为什么模型会过拟合或者欠拟合。如果我们又对模型进行了大的修改,有必要返回去确认模型是在适当收敛的。
运行示例,报告了评价过程的每次迭代模型性能,并报告了运行结束时分类准确度的均值和标准偏差。跟随我的新书 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),开启你的项目,其中包括所有示例的分步教程和Python源代码文件。这个例子中,MLP模型的平均准确度是75.2%,和我们上一部分的模型结果接近。这证实了我们的期望,即对于这个数据集,基本模型配置可能比简单的模型工作得更好。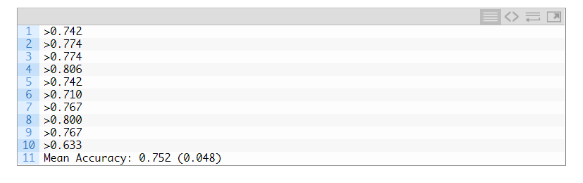
事实上,这是个具有挑战的分类问题,74.5%的准确度结果已经不错了。接下来,让我们看看我们如何拟合最终的模型并用它来预测当我们选择了模型参数,我们可以在所有数据上训练一个最终的模型,并用模型对新数据进行预测。在本例中,我们将使用带dropout的模型,和小批量训练。数据准备和模型拟合按上文实现,尽管是在整个数据集上,而不是在数据集的训练子集上。

备注:我是提取的数据集的第一行数据,预期输出结果是‘1’。

然后对预测结果进行转置,得到正确形式下可解释的结果(是一个整数)。

把以上步骤整合起来,对haberman数据集上进行拟合最终模型,并对新数据进行预测的完整代码示例如下所示。
执行示例代码在整个数据集上拟合模型,并对新数据进行预测。跟随我的新书 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),开启你的项目,其中包括所有示例的分步教程和Python源代码文件。
如果你想在这个方向继续探索,本节提供了更多学习资源
https://machinelearningmastery.com/how-to-develop-a-probabilistic-model-of-breast-cancer-patient-survival/
https://machinelearningmastery.com/predicting-disturbances-in-the-ionosphere/
https://machinelearningmastery.com/results-for-standard-classification-and-regression-machine-learning-datasets/
https://machinelearningmastery.com/tensorflow-tutorial-deep-learning-with-tf-keras/ https://machinelearningmastery.com/k-fold-cross-validation/在本教程中,您了解了如何应用癌症生存二分类数据集开发多层感知器神经网络模型。
Develop a Neural Network for Cancer Survival Datasethttps://machinelearningmastery.com/neural-network-for-cancer-survival-dataset/工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

