
一直以来,在深度学习领域,图像分类是呈指数级增长的课题之一。传统的图像识别任务很大程度上依赖于一些专有的处理技术,如膨胀/腐蚀、内核和频域转换等处理方法,然而特征提取的困难最终限制了这些方法所取得的进展。另一方面,神经网络关注的是寻找输入图像和输出标签之间的关系,为了实现此目的,需要对架构进行“调优”。虽然准确性提高得很显著,但神经网络通常需要大量的数据来进行训练,因此,现在有许多研究都关注数据增强——在现有数据集基础上增加数据量的过程。本文介绍了一种既简单又有效的增强策略——图像混合(Mixup),利用 PyTorch框架实现图像混合并对结果进行比较。根据给定的训练数据集来训练和更新神经网络体系结构中的参数。然而,由于训练数据集只涵盖了整个可能数据分布的某一部分,网络可能对目前“可见”部分的分布产生过拟合。因此,我们进行训练的数据越多,理论上就能更好地覆盖整个分布。虽然我们拥有的数据数量有限,但我们可以尝试稍微改变图像,并将它们作为“新”样本输入网络进行训练。这个过程被称为数据增强。图像混合为何物?
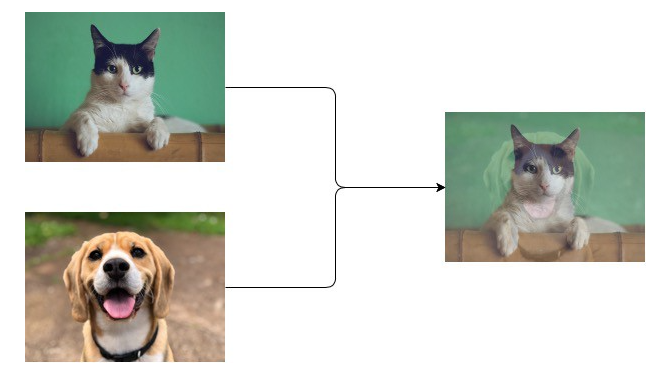
假设需要对狗和猫的图像进行分类,给出一组带有标签的图像集合(即[1,0]代表狗;[0, 1] 代表猫),图像混合的过程是对两幅图像进行简单的平均,它们的标签对应一个新数据。具体地说,可以用以下数学概念来描述图像混合的过程: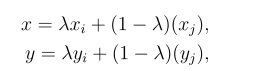
其中x和y分别是图像xᵢ(标签为yᵢ)和图像xⱼ(标签为yⱼ) 混合后的图像和标签,λ为给定beta分布的随机数。这为不同的类提供了连续的数据样本,直观地扩展了给定训练集的分布,从而使网络在测试阶段更加稳健。在神经网络上使用图像混合
由于图像混合仅仅是一种数据增强方法,它与所有分类网络的架构正交,这意味着可以在所有分类问题的神经网络中采用图像混合。Zhang等在 “图像混合:远不止将经验风险最小化”一文的基础上,对多个数据集和架构进行了实验,实验结果表明:图像混合的好处不是一次性的特例。图像混合:远不止将经验风险最小化”
https://arxiv.org/abs/1710.09412
计算环境
运行库
整个项目通过PyTorch库(包括torchvision)来实现,图像混合需要从beta分布中生成样本,这可以方便地通过NumPy库实现,也可以使用随机库来混合随机图像。利用以下代码导入库: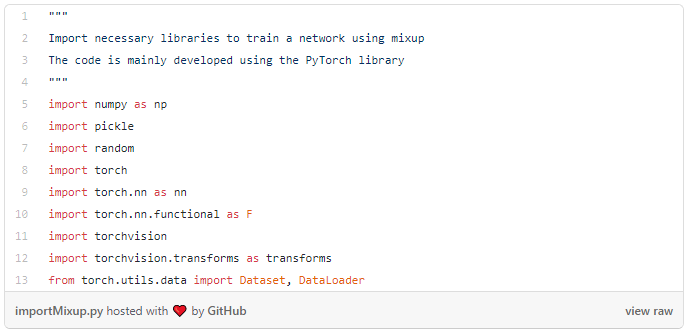
数据集
作为演示,为了将图像混合的概念应用到传统的图像分类上, CIFAR-10数据集似乎是最可行的选择,CIFAR-10数据集包含10个类,多达60000幅彩色图像(每类6000个),以5:1的比例分为训练集和测试集。这些图像的分类相对简单,但比最基本的数字识别数据集MNIST要难。有多种方法可以下载到CIFAR-10数据集,包括从多伦多大学的网站上下载或使用torchvision数据集。另一个值得一提的平台是Graviti Open Datasets 平台,该平台包含数百个数据集及其相应的通讯作者,各个数据集对应训练任务的标签(即分类、目标检测)。也可以下载其他分类数据集,如CompCars或SVHN来测试不同场景下图像混合带来的性能优化。目前,该公司正在开发SDK,虽然现在加载数据会比较费时,但未来不久将可能会有所改进,因为他们正在优化快速批量下载。CIFAR-10
https://gas.graviti.com/dataset/graviti/CIFAR10?utm_medium=0608kol-1
Graviti Open Datasets
https://graviti.com/?utm_medium=0608kol-2
硬件要求
最好在GPU上训练神经网络,因为GPU能显著提高训练速度。但是,如果手上只有CPU可用,仍然可以测试该程序。只需使用以下操作,便可以确定运行程序的硬件要求: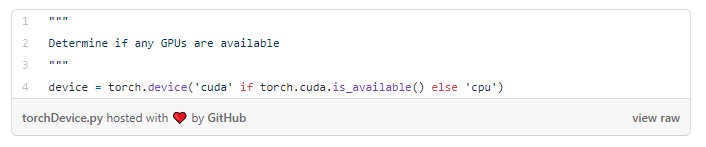
实施情况
网络
实验目的是要看到图像混合的结果,而不是神经网络本身。因此,为了达到演示的目的,实现了一个简单的4层卷积神经网络(CNN),后随 2层全连接层。注意,对于图像混合和非图像混合训练程序,均采用相同的神经网络以确保其公平性。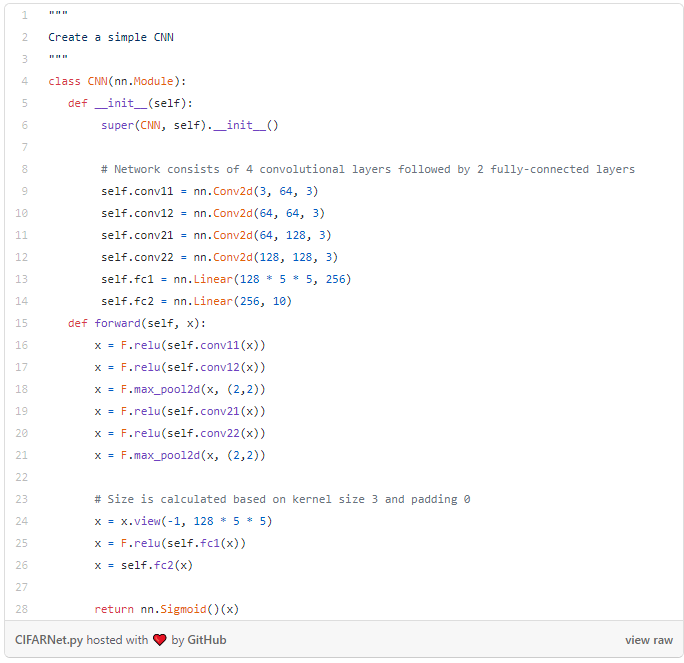
图像混合
在数据集加载过程中完成图像混合,首先必须编写自己的数据集,而不是使用torchvision.datasets提供的默认数据集。以下是利用NumPy中包含的beta分布函数实现图像混合的代码:
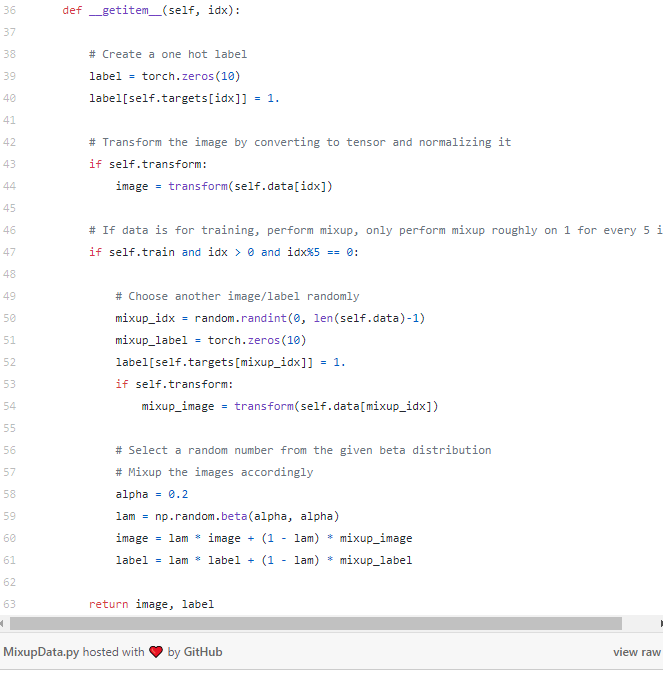
注意,上述程序并没有对所有图像应用图像混合,而是对大约五分之一的图像应用图像混合。此外,还使用了0.2的beta 分布,可以根据不同的实验来修改分布参数和图像的数量,以期取得更好的结果!训练与评估
以下代码为训练程序,将批处理大小设置为128,学习速率设置为1e-3,epochs总数设置为30。整个训练进行了两次,一次是带图像混合的,一次是不带图像混合;损失也由自己定义,因为目前,BCE损失不允许带有小数的标签: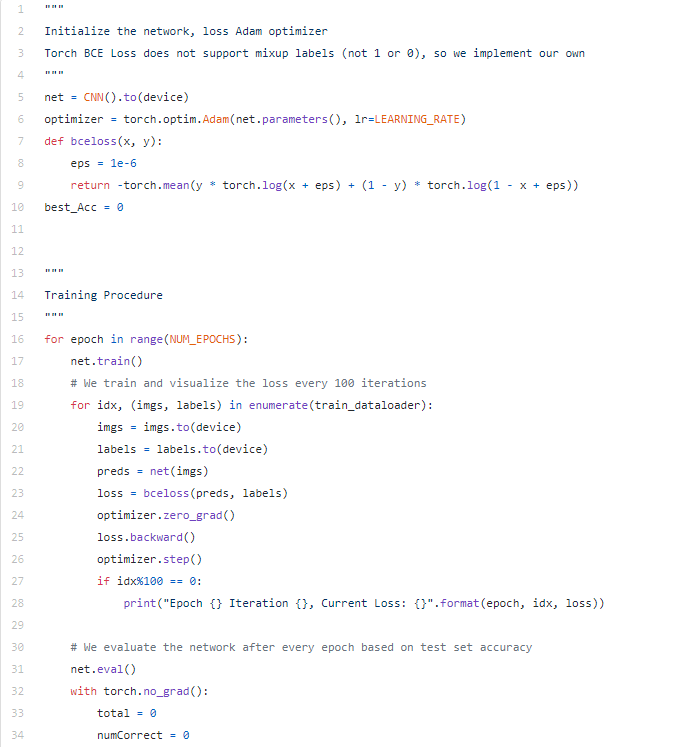
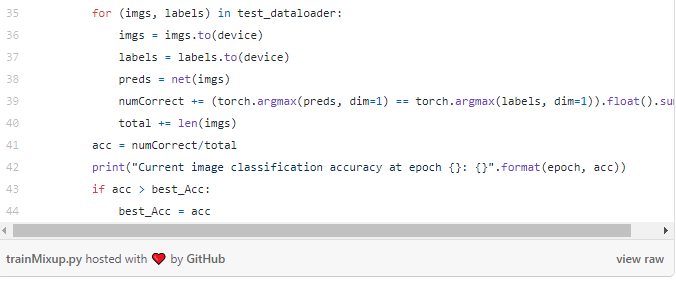
为了评估图像混合的效果,分别对带有图像混合和不带图像混合各自计算了三次准确率。在没有图像混合的情况下,网络对测试集的准确率约为74.5%,而在带有图像混合时,准确率提高到76.5%左右!图像分类之外的拓展
图像混合不但提高了图像分类的准确性,而且研究表明,而且它的优势已经扩展到其他计算机视觉任务中,如能提高对抗性样本的鲁棒性。同时,研究文献也将这个概念扩展到三维表示中,已经证明非常有效(例如:PointMixup)。PointMixup
https://arxiv.org/abs/2008.06374
结论
希望这篇文章能带给你一个关于如何在训练图像分类网络时应用图像混合的基本概述和指南。
谢谢拨冗阅读本文!后续将发布更多关于计算机视觉/深度学习的不同领域的文章。一定要看看关于VAE的其他文章,通过一次性学习,汲取更多知识!
陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

