
SOTA模型Swin Transformer是如何炼成的!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
欢迎start基于detectron2的SwinT实现:xiaohu2015/SwinT_detectron2
https://github.com/xiaohu2015/SwinT_detectron2
最近,微软亚研院提出的Swin Transformer在目标检测和分割任务上取得了新的SOTA:在COCO test-dev 达到58.7 box AP和51.1 mask AP,在ADE20K val上达到53.5 mIoU。Swin Transformer的成功恰恰说明了vision transformer在dense prediction任务上的优势(model long-range dependencies)。Swin Transformer的核心主要有两点:层级结构(即金字塔结构)和window attention,这两个设计让Vision Transformer更高效。
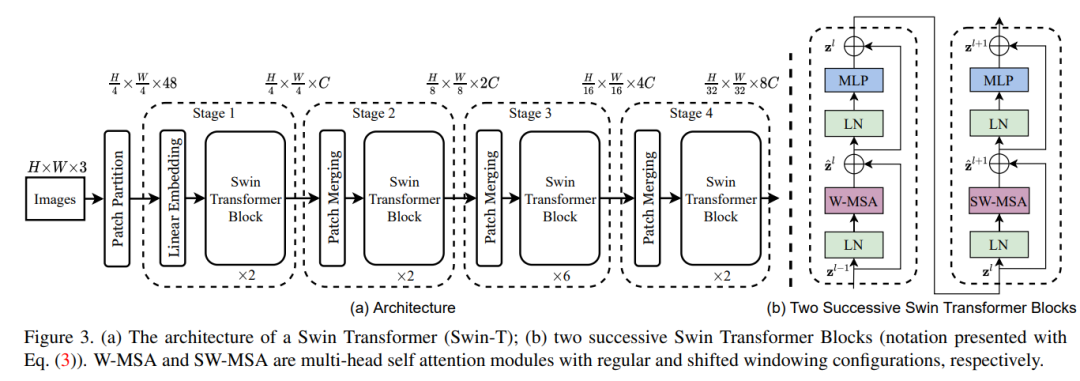
层级结构
主流的CNN模型都是采用金字塔结构或者层级结构,即将模型分成不同stage,每个stage都会降低特征图大小(feature map size)但同时提升特征数量(channels)。但是ViT等模型却没有stage的概念,所有的layers都是采用同样的参数配置,其输入也是同样维度的特征。对于图像来说,这样的设计从计算量来看并没太友好,所以一些最近的工作如PVT就采用了金字塔结构来构造vision transformer,并在速度和效果取得了较好的balance。Swin Transformer设计的金字塔结构和PVT基本一致,网络包括一个patch partition和4个stage:
(1)patch partition:将图像拆分成个patch,每个patch大小为(ViT一般为或);
(2)stage1开始是一个patch embedding操作:通过linear embedding层得到的patch embeddings,通过卷积来实现;
(3)剩余的3个stage开始都先有一个patch merging:将每个相邻patchs的特征合并,此时特征维度大小,然后通过一个linear层映射到的特征空间。这个过程patchs的数量降低4x,而特征增长2x,和CNN的stride=2的downsample类似。其实这个patch merging也等价于对区域做patch embedding。具体实现如下:
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
(4)然后每个stage包含相同配置的transformer blocks,stage1到stage4的特征图分辨率分别是原图的,,,,这样Swin Transformer就非常容易应用在基于FPN的dense prediction任务中;(5)最后对所有的patch embeddings求平均,即CNN中常用的global average pooling,然后送入一个linear classifier进行分类。这和ViT采用class token来做分类不一样。
Window Attention
ViT中的self-attention是对所有的tokens进行attention,这样虽然可以建立tokens间的全局联系,但是计算量和tokens数量的平方成正比。Swin Transformer提出采用window attention来降低计算量,首先将特征图分成互不重叠的window,每个window包含相邻的个patchs,每个window内部单独做self-attention,这可看成是一种local attention方法。对于一个包含个patchs的图像来说,基于window的attention方法(W-MSA)和原始的MSA计算复杂度对比如下:
可以看到MSA的计算量与图像大小平方-成正比,而由于window大小是一个固定值(论文中默认为7,相比图像大小较小),所以W-MSA的计算量和图像大小平方-成正比,这对于高分辨率的图像,计算量大大降低。另外,各个window的参数是共享的,这个和卷积的kernel类似,所以W-MSA就和convolution一样具有locality和parameter sharing 两大特性。对于W-MSA,首先要实现window partition和reverse,具体实现如下(由于参数共享,可以将num_windows并入Batch维度):
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
由于self-attention是permutation-invariant的,所以需要引入position embedding来增加位置信息。Swin Transformer采用的是一种相对位置编码,具体的是在计算query和key的相似度时加一个relative position bias:
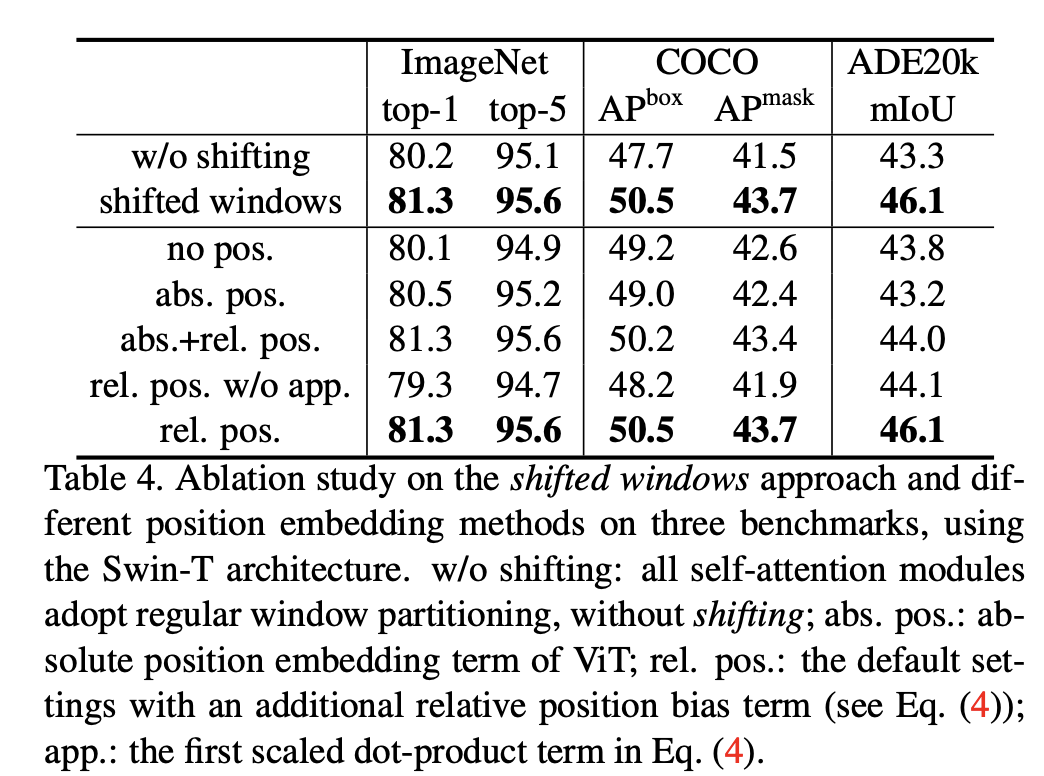
这里的为query,key和value,就是一个window里的patchs总数,而是relative position bias,用来表征patchs间的相对位置,attention mask与之相加后就能引入位置信息了。但是实际上我们并需要定义那么大的参数,由于一个window里的tokens在和每个维度上的相对位置都在范围内,共有个取值,如果我们采用2D relative position来编码的话,相对位置共有 ,那么只需要定义的relative position bias就可以了,这样就降低了参数量(论文中每个W-MSA都独有自己的relative position bias),实际的通过索引从中得到。从论文中的实验来看(如下所示),直接采用relative position效果是最好的,如果加上ViT类似的abs. pos.,虽然分类效果一致,但是分割效果下降。
最终window attention的实现如下所示:
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
# 区分head
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
# 计算tokens间的相对位置
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 # 乘以行count,变为一维索引
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
# 参数共享,只需要定义一套参数
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# 获取B
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
# attention mask
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
对于window attention,还有一个小问题就是如果图像或者特征图不能被整分,那么可以采用的方式是padding,论文中采用的是对右下位置进行padding(可以通过设置attention mask来消除padding的影响,不设置也影响不大):
To make the window size (M, M) divisible by the feature map size of (h, w), bottom-right padding is employed on the feature map if needed.
Shifted Window
window attention毕竟是一种local attention,如果每个stage采用相同的window attention,那么信息交换只存在每个window内部。用CNN的话语说,那么感受野是没有发生变化的,此时只有当进入下一个stage后,感受野才增大2倍。论文中提出的解决方案是采用shifted window来建立windows间的信息交互。常规的window切分是从特征图的左上角开始均匀地切分,比如下图中的大小的特征图切分成4个windows,这里。那么shifted window是从和两个维度各shift 个patchs,此时切分的windows如下图所示,注意此时边缘部分产生的windows就不再是大小的。通过shifted window进行的window attention记为SW-MSA,当交替地进行W-MSA和SW-MSA,模型的表达能力就会增强,因为windows间也有了信息传递。
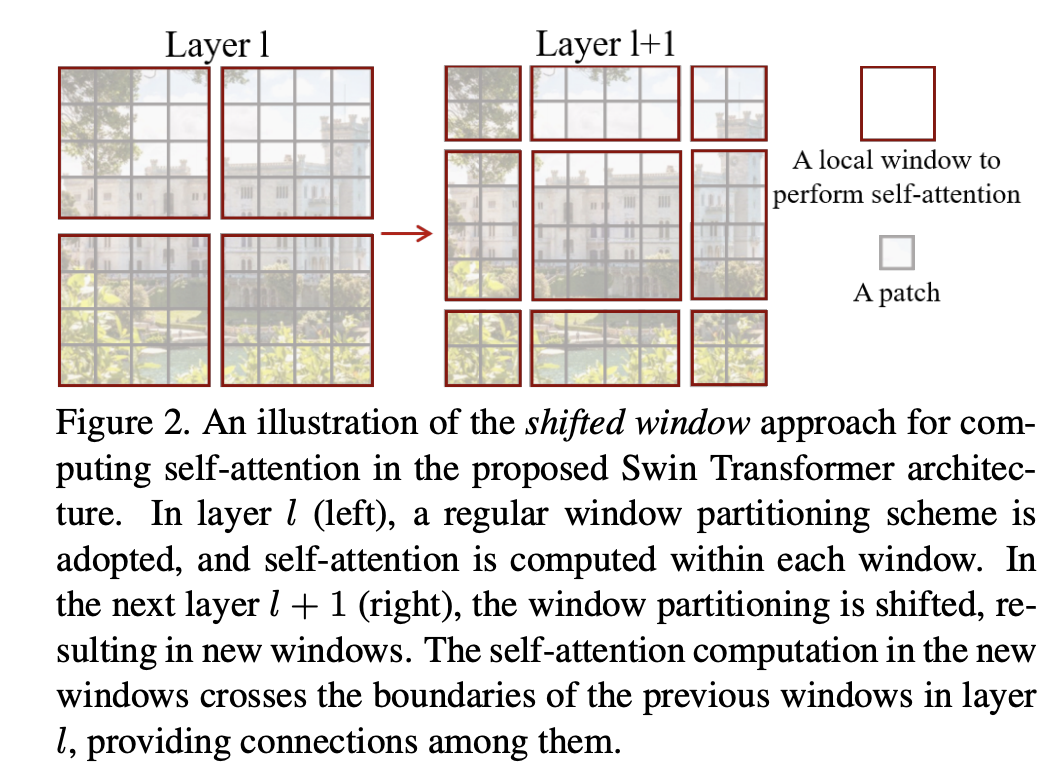
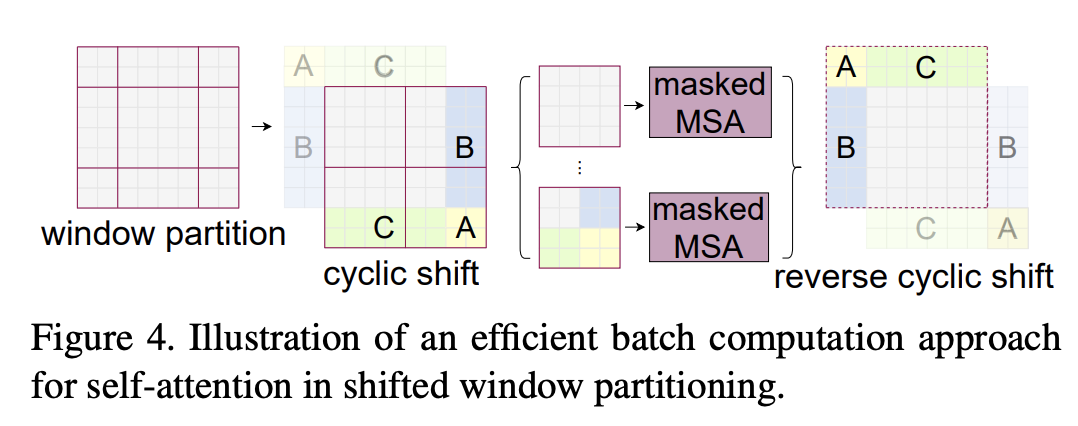
但是shifted window会带来一个问题:边缘处的windows的大小发生了改变,而且这还会导致windows的数量从增加至。在实现SW-MSA时,一种最直接的处理方式是对边缘进行padding,使得所有的windows的大小为,这样就可以像W-MSA一样将windows组成batch进行计算,但是这会增加计算量,特别是当windows总数较少时。比如上图中例子,W-MSA的windows数量为,而SW-MSA的windows数量为,这样计算量将变为原来的2.25倍。论文中提出了一种cyclic-shift的策略来高效地实现SW-MSA,如下图所示,直观来看是讲左上的6个windows移动到右下位置,这样处理后8个较小的windows就可以组成3个大小为的windows,那么总的windows数量就没有变化,计算量一样,完成attention计算后reverse就好。这种cyclic-shift可以通过torch.roll来实现。虽然小的windows可以组成常规windows,但是在attention计算时要通过mask来保证原来的效果。生成attention mask的实现也是比较简单:所有的windows可以分成9组,其中边缘部分共8个windows,而中间的windows都是大小为的正常windows,可看成1组;9组可以设定不同的id,在组成新的windows后id不同的tokens就通过mask不进行attention计算。
具体到实现如下所示,可以通过shift_size来区分是W-MSA还是SW-MSA:
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# 如果输入分辨率小于M,就直接一个window attention就好
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# 对SW-MSA,生成attention mask
if self.shift_size > 0:
# calculate attention mask for SW-MSA
# 将windows的9组设定不同的id:0~8
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
Swin Transformer
Swin Transformer的核心就是在每个stage交替采用W-MSA和SW-MSA,其中window size ,论文中共设计了4种不同的模型:Swin-T, Swin-S, Swin-B,Swin-L,具体的参数如下所示:
• Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
• Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
• Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
• Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
不同模型主要是特征维度不同和每个stage的层数不同,其中Swin-T和Swin-S的模型复杂度类比ResNet-50 (DeiT-S) 和ResNet-101。模型中的MSA每个head的特征维度(变化的只是heads数量),FFN中的expansion系数。
SwinT模型在ImageNet上与其它模型的对比如下所示,可以看到SwinT效果要优于DeiT,相比CNN网络RegNet和EfficientNet也有较好的speed-accuracy trade-off。
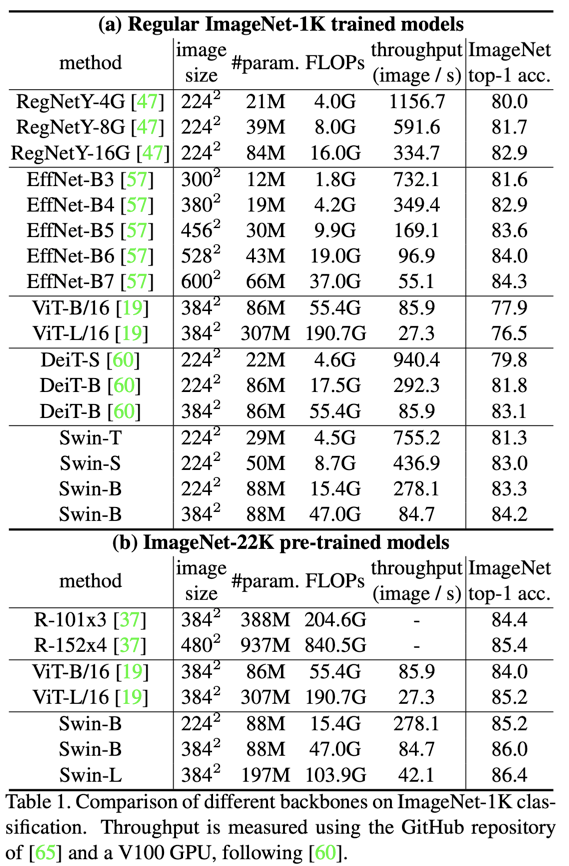
对于目标检测(实例分割),将backbone替换成SwinT,均表现了更好的效果,其中基于Swin-L的HTC++模型在在COCO test-dev 达到58.7 box AP和51.1 mask AP。
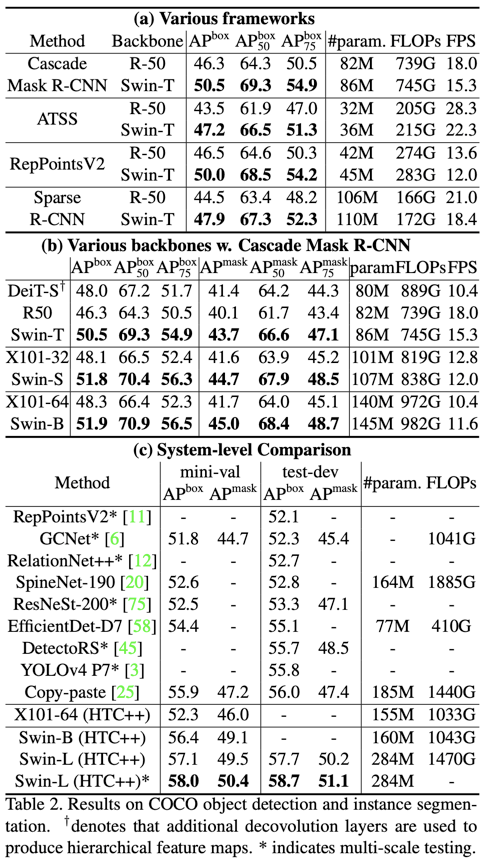
对于语义分割,将backone换成SwinT也可以得到更好的效果,基于Swin-L的UperNet模型在ADE20K val上达到53.5 mIoU。
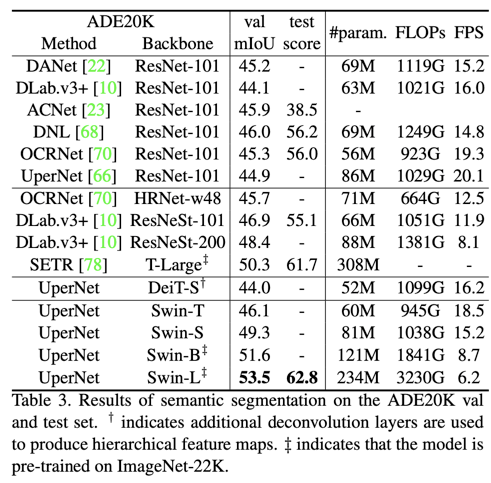
所以,SwinT模型在dense prediction任务上表现还是非常好的。
自监督
近期,SwinT的作者又放出了将SwinT模型用于自监督训练中:Self-Supervised Learning with Swin Transformers。关于将vision transformer模型应用在自监督领域,已经有多篇论文了,这包括Facebook AI的两篇研究:MoCoV3: An Empirical Study of Training Self-Supervised Vision Transformers和DINO: Emerging Properties in Self-Supervised Vision Transformers,这两篇都证明了ViT模型在自监督领域的前景。SwinT的这篇自监督报告更多的倾向于论证基于自监督训练的SwinT模型也可以像CNN一样迁移到下游任务并取得好的效果。
报告中采用的自监督训练方法为MoBY,其实就是将MoCo和BYOL结合在一起了:
MoBY is a combination of two popular selfsupervised learning approaches: MoCo v2 and BYOL. It inherits the momentum design, the key queue, and the contrastive loss used in MoCo v2, and inherits the asymmetric encoders, asymmetric data augmentations and the momentum scheduler in BYOL
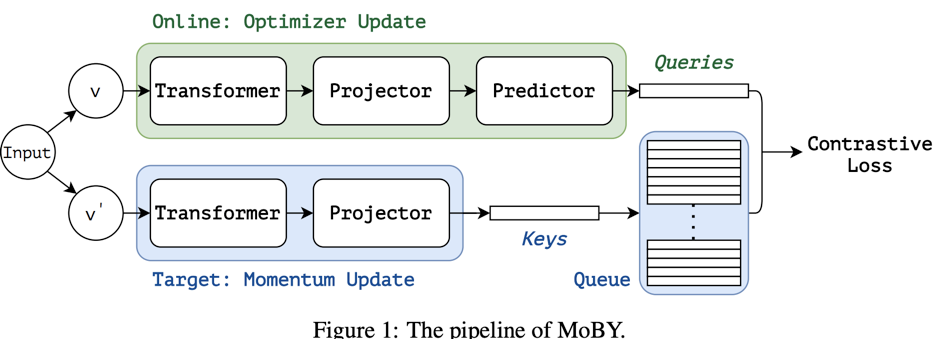
在ImageNet1K linear evaluation实验上,MoBY优于MoCoV3和DINO(无multi-crop scheme),同时基于SwinT的模型效果也优于DeiT:
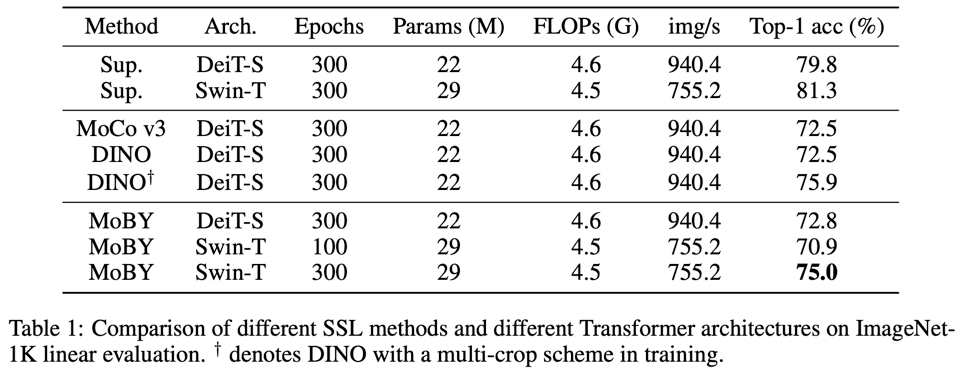
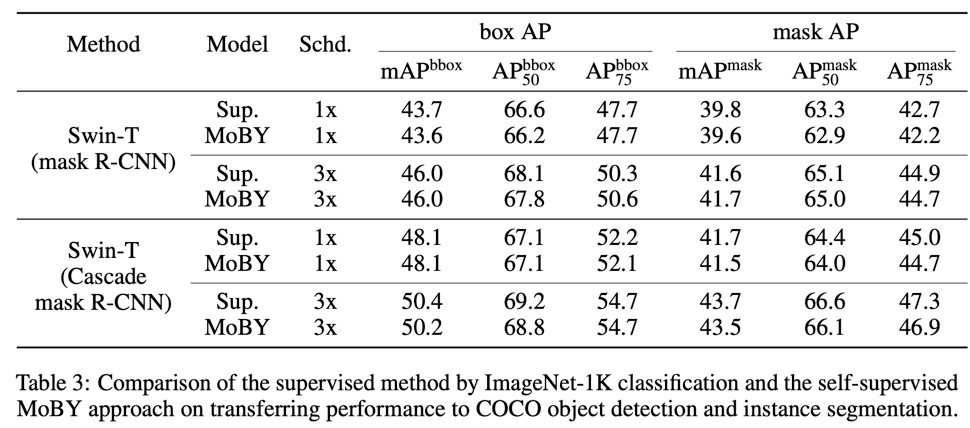
当迁移到下游任务如实例分割中,自监督模型和有监督模型效果相当(稍微差一点):
结语
SwinT的成功让我们看到了vision transformer模型在dense prediction任务的应用前景,但是我个人觉得SwinT设计上还是过于复杂,近期美团提出的Twins: Revisiting the Design of Spatial Attention in Vision Transformers感觉更优雅一些。
参考
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows microsoft/Swin-Transformer xiaohu2015/SwinT_detectron2 Self-Supervised Learning with Swin Transformers
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
